






作者 | OpenDriveLab 编辑 | OpenDriveLab
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文

ECCV 2024

ECCV 2024将在当地时间9月29号于意大利米兰召开,团队各篇论文作者将会在会场线下进行分享。此外,李弘扬博士将在两个论坛上进行演讲,期待与各位深入交流。
DriveLM被评选为ECCV 2024 Oral论文
世界首个语言+自动驾驶全栈开源数据集DriveLM旨在借助大语言模型和海量自然语言数据集,构筑复杂场景下安全、精准、可解释的自动驾驶系统,突破现有自动驾驶推理能力上限。更多关于该工作的信息请见:DriveLM:世界首个语言+自动驾驶全栈开源数据集 (by 司马崇昊)
论文链接:https://arxiv.org/abs/2312.14150
项目主页:https://github.com/OpenDriveLab/DriveLM
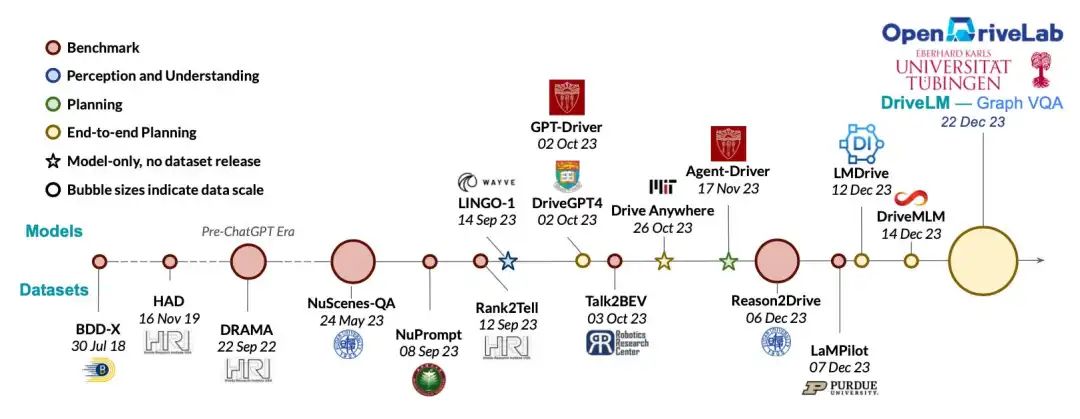
ELM:自动驾驶具身场景理解
ELM先驱性地将具身理解的哲学引入自动驾驶领域中,提出世界首个用于理解大尺度和长时序驾驶场景的具身语言模型。ELM将拓展的十项任务建立自动驾驶场景理解的新基准,以完备地公平地评价视觉语言模型在具身理解中的能力。(by 周云松)
论文链接:https://arxiv.org/abs/2403.04593
项目主页:https://github.com/OpenDriveLab/ELM
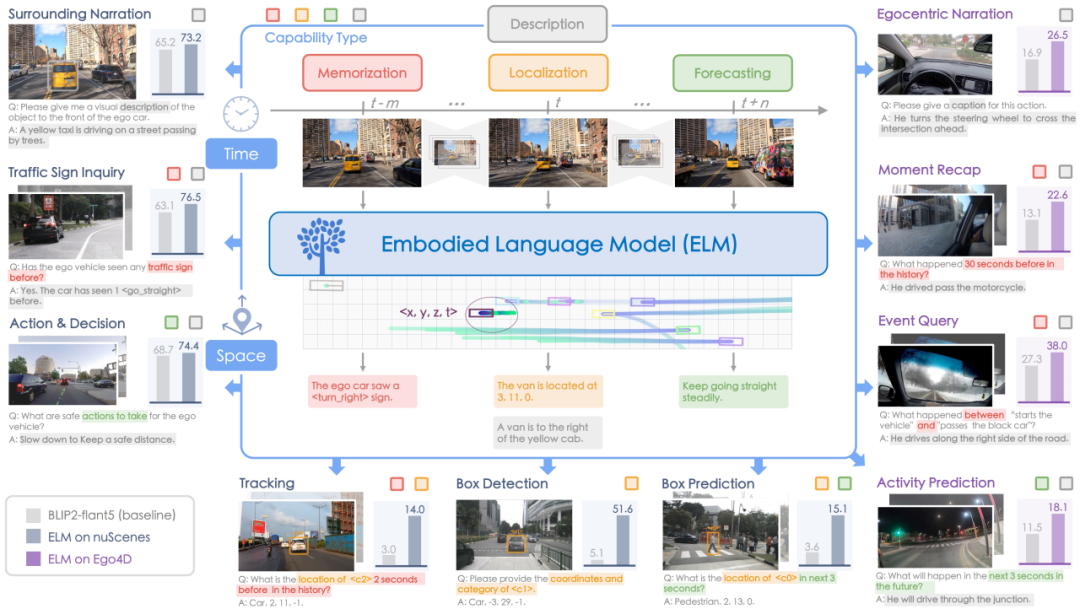
SparseOcc:全稀疏占据栅格预测网络
SparseOcc从纯相机输入中重建稀疏的三维表示,并通过稀疏Query预测语义和实例占用栅格。此外,本文提出的一种基于射线的评价指标RayIoU同时作为CVPR 2024国际自动驾驶挑战赛中占据栅格预测与运动估计赛道中的评测指标。挑战赛中,Lightwheel AI与团队联合推出并开源的LightwheelOcc数据集也被用于占据栅格和运动估计赛道。该数据集包含不同地域环境、天气条件、车辆类型、植被、道路标记的泛化数据集,提供占用网格和深度图标签,可导航各种区域地形、天气模式、车辆类型、植被和道路分界线。(by 刘海松)
数据集链接:https://github.com/OpenDriveLab/LightwheelOcc/
李弘扬博士将在两个论坛上进行演讲
多模态大模型对自动驾驶感知与理解任务十分重要,ECCV 2024中的两个论坛(MLLMAV与CODA)将从不同角度对自动驾驶多模态相关内容进行讨论。李弘扬博士也将在两个论坛中进行演讲,期待在意大利米兰与各位线下进行交流。
Autonomous Vehicles meet Multimodal Foundation Models(9月29号):https://mllmav.github.io/
Multimodal Perception and Comprehension of Corner Cases in Autonomous Driving(9月30号):https://coda-dataset.github.io/w-coda2024/


NeurIPS 2024

NeurIPS 2024结果公布,团队有以下亮点工作:Vista为新一代自动驾驶世界模型,更具可泛化性与可控性;CLOVER为具身智能闭环视觉运动控制框架,为具身智能控制模块提供有效的长时序闭环反馈预测;BeTop则关注多智能体的拓扑表征,进一步推进预测与规划性能;NAVSIM是用于大规模真实世界自动驾驶规划的基准测试。
Vista:可泛化的自动驾驶世界模型
新一代的自动驾驶世界模型Vista具有高度可泛化与可控性。与上一代自动驾驶世界模型GenAD相比,该工作在以下方面均具有优异性能提升:多样且高分辨率的未来驾驶场景、 稳定的长时序预测结果、多模态的自车控制输入、任意场景的奖励(reward)评估。更多详情请见推送:构建开放自动驾驶场景中的世界模型 (by 高深远)
论文链接:https://arxiv.org/abs/2405.17398
项目主页:https://github.com/OpenDriveLab/Vista

CLOVER:闭环视觉运动控制框架
CLOVER采用基于文本的视频扩散模型,可生成视觉预测作为控制参考,并用此参考为后续闭环控制模块进行偏差估计。得益于闭环控制策略,该模型对视觉干扰和物体变化等情况具有良好的鲁棒性,获得精准且可靠的状态控制及优秀的长时序任务性能。(by 布清文)
论文链接:https://arxiv.org/abs/2409.09016
项目主页:https://github.com/OpenDriveLab/CLOVER

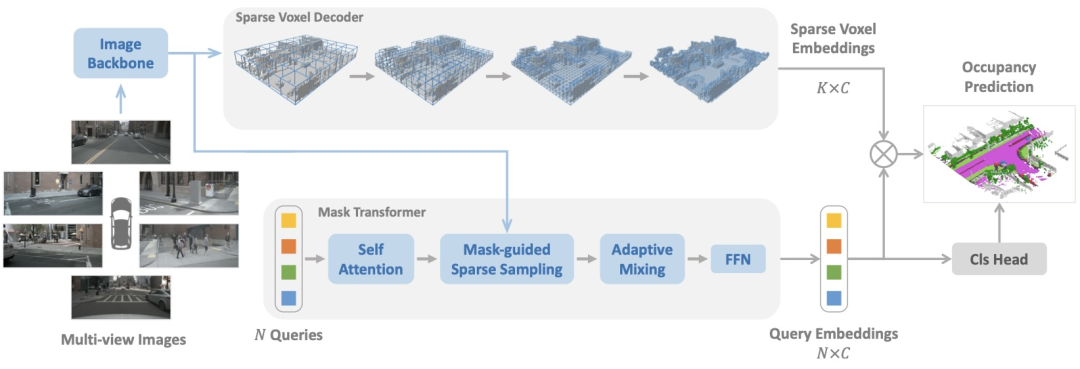
BeTop:自动驾驶多智能体行为拓扑推理
BeTop利用绳结理论,建立了一种多智能体未来行为的拓扑表征,将拓扑推理与预测和规划任务相结合。在包括WOMD和nuPlan在内的大规模真实数据集上进行了广泛验证,BeTop在预测和规划任务中均达到了最先进的性能。(by 刘浩晨)
项目主页:https://github.com/OpenDriveLab/BeTop
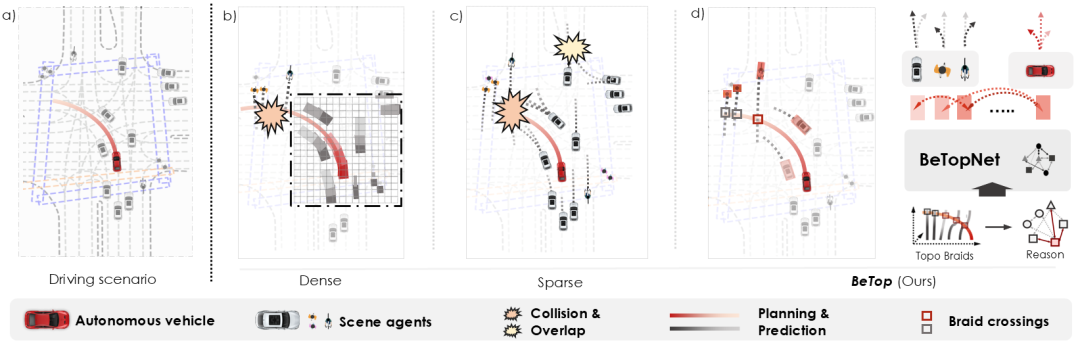
NAVSIM:数据驱动的非响应式自动驾驶仿真与评测基准
团队与图宾根大学、英伟达合作的NAVSIM是一个介于端到端规划任务的开环和闭环评估之间的,用于大规模真实世界自动驾驶规划任务的基准测试。NAVSIM结合了大规模数据集和非响应式模拟器,使用鸟瞰视角的场景抽象并在短期内进行模拟,从而收集如自车行进进展和碰撞等基于模拟的指标。该模拟器是非反应性的,即被评估的规划策略和环境彼此独立。此外,该工作同时作为CVPR 2024国际自动驾驶挑战赛中端到端自动驾驶赛道,吸引了众多世界各地参赛者参与。
论文链接:https://arxiv.org/abs/2406.15349
项目主页:https://github.com/autonomousvision/navsim

征稿启事

Automotive Innovation - 端到端自动驾驶
此征稿启事为围绕自动驾驶端到端范式的专题,欢迎各位进行投稿。专栏旨在交流探讨端到端自动驾驶技术的多方面情况,包括基础理论、创新应用技术,以推动自动驾驶技术在现实世界中的影响与应用。详情请访问:征稿 | Automotive Innovation自动驾驶中的人工智能:端到端范式专题征稿


国际标准

Call for Participation - IEEE国际标准P3474:自动驾驶大模型安全对齐
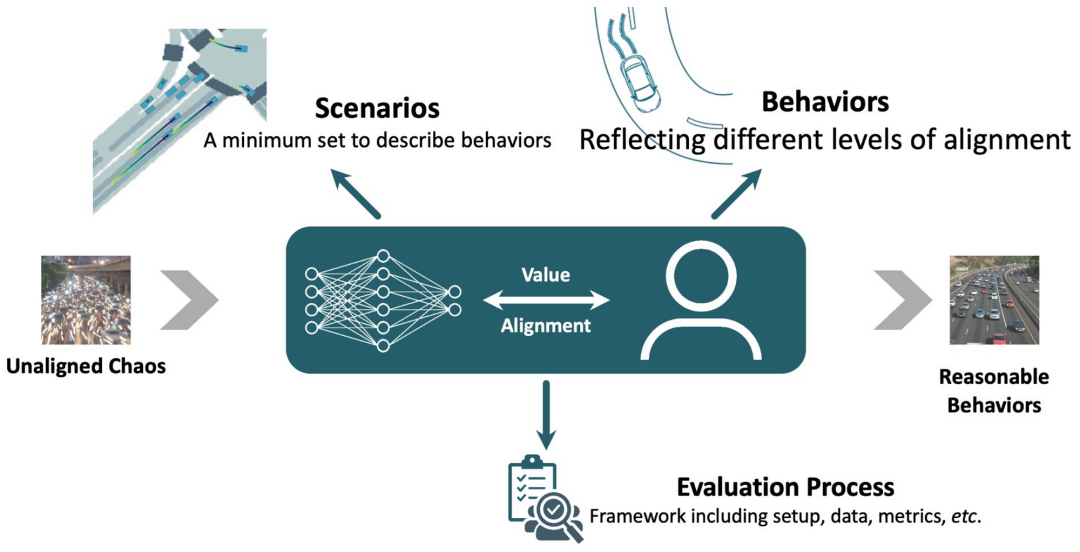
IEEE国际标准自主智能体对齐工作组(VT/AVSC/AAA-WG)专注于智能体安全对齐的相关标准制定工作。该工作组的首个标准P3474已经正式开始制定工作,该标准将规范自动驾驶大模型安全对齐相关任务。同时,工作组也将继续接受新的标准及白皮书提案。
工作组主页:https://sagroups.ieee.org/3474/
Slack交流群:加入Slack(https://join.slack.com/t/opendrivelab/shared_invite/zt-2ft3dfjoz-6XErfBts4s_8Fen88wO4Jg)-> 加入频道 ieee-p3474
下一次会议将于10月8号召开:https://sagroups.ieee.org/3474/meeting/ieee-vt-avsc-aaa-wg-october-2024/

『自动驾驶之心知识星球』欢迎加入交流!重磅,自动驾驶之心科研论文辅导来啦,申博、CCF系列、SCI、EI、毕业论文、比赛辅导等多个方向,欢迎联系我们!

① 全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内外最大最专业,近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵















 261
261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









