






点击下方卡片,关注“自动驾驶之心”公众号
PRIMEDrive-CoT
论文标题:PRIMEDrive-CoT: A Precognitive Chain-of-Thought Framework for Uncertainty-Aware Object Interaction in Driving Scene Scenario
论文链接:https://arxiv.org/abs/2504.05908
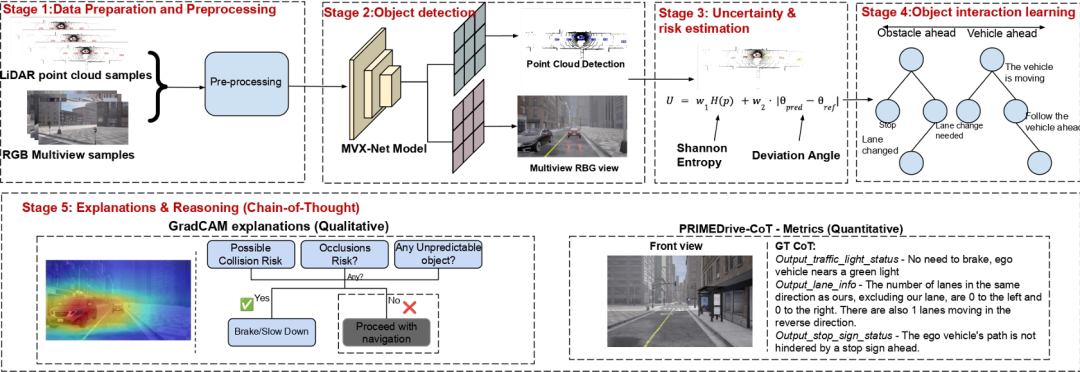
核心创新点:
1. 贝叶斯图神经网络(BGNN)驱动的不确定性建模
首次将BGNN应用于驾驶场景的物体交互推理,通过概率图结构建模车辆-行人、车辆-车辆间的动态交互。结合Shannon熵与偏航角偏差量化检测不确定性,并引入接近度感知风险指标 (基于指数衰减函数),实现对潜在威胁的优先级排序。
2. 可解释的链式思维(CoT)推理机制
通过分阶段的CoT模块生成结构化解析(如"减速因行人接近与前车急刹"),同步融合Grad-CAM可视化注意力图,显式关联决策依据与多模态输入(LiDAR点云与RGB图像),确保黑箱模型的透明性。
3. 多模态特征增强与轻量化部署
采用改进的MVX-Net架构实现LiDAR点云体素化与多视角RGB特征融合,在保持3D检测精度(IoU 78%)的同时,通过RGB验证机制降低误检率。推理速度达18.7 FPS(单RTX 3090),满足实时性需求。
MIAT
论文标题:MIAT: Maneuver-Intention-Aware Transformer for Spatio-Temporal Trajectory Prediction
论文链接:https://arxiv.org/abs/2504.05059
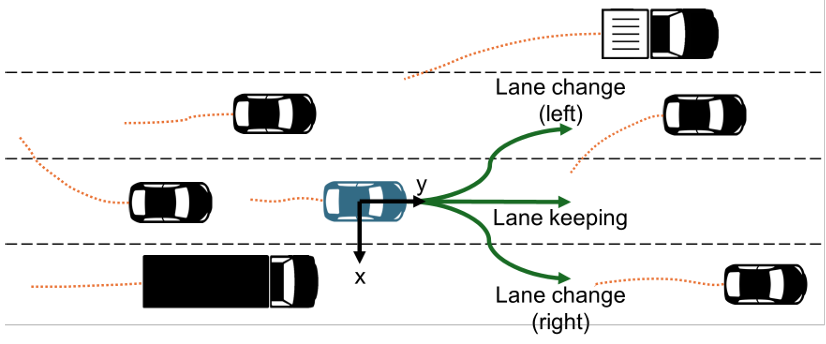
核心创新点:
1. 机动意图感知Transformer架构(MIAT)
提出Transformer-based时空交互建模 ,替代传统LSTM,通过自注意力机制(self-attention)捕捉车辆轨迹的长程时空依赖,解决LSTM在长序列处理中的梯度消失与效率瓶颈。
2. 多模态机动意图融合机制
引入六类驾驶意图分类 (横向:车道保持、左/右换道;纵向:加速、减速、匀速),通过动态意图概率分布 (softmax分类)与时空特征融合(soft attention),实现意图感知的轨迹预测。
3. 可调节损失加权策略
设计联合优化目标函数(L = + ),通过控制机动损失权重(λ)平衡短期精度与长期预测鲁棒性。实验表明,高权重(如200x)显著提升长时域(5秒)预测精度(+11.1%),验证意图建模对复杂行为长期演化的关键作用。
4. 动态交互依赖建模(DID模块)
采用多头自注意力 捕捉车辆间交互的时序相关性,突破传统方法对静态交互假设的局限,动态建模邻车影响随时间的变化。
5. 高效并行计算优化
利用Transformer的并行特性,结合GPU加速,实现实时轨迹预测 (50Hz以上),满足自动驾驶系统的低延迟需求。
DDT
论文标题:DDT: Decoupled Diffusion Transformer
论文链接:https://arxiv.org/abs/2504.05741

核心创新点:
1. 解耦架构设计
采用双模块分工机制 :条件编码器(Condition Encoder)通过自监督对齐预训练视觉特征(REPAlign),专注提取低频语义信息;速度解码器(Velocity Decoder)基于编码器生成的自条件特征(self-condition),高效解码高频细节。该设计突破了传统扩散Transformer单模块处理全频段信息的局限性,在ImageNet 256×256和512×512数据集上分别实现1.31 FID(256 epochs)和 1.28 FID(500K steps)的SOTA性能,训练效率提升4倍。
2. 推理加速策略
利用编码器特征的时序一致性,提出统计动态规划算法 优化自条件特征共享策略。通过构建相似性矩阵并求解最小路径和问题,在保证生成质量的前提下,实现相邻去噪步骤间编码器计算的动态复用(如87%共享率下FID仅上升0.09),显著降低推理复杂度。
3. 架构扩展性突破
发现编码器容量与模型性能的强相关性,提出非对称层分配原则 (如DDT-XL/2采用22层编码器+6层解码器),验证了大规模模型下"强编码-轻解码"架构的优越性。结合改进的RoPE位置编码与RMSNorm等技术,进一步优化高频重建能力。
Pedestrian-Aware Motion Planning
论文标题:Pedestrian-Aware Motion Planning for Autonomous Driving in Complex Urban Scenarios
论文链接:https://arxiv.org/abs/2504.01409
代码:https://github.com/TUM-AVS/PedestrianAwareMotionPlanning
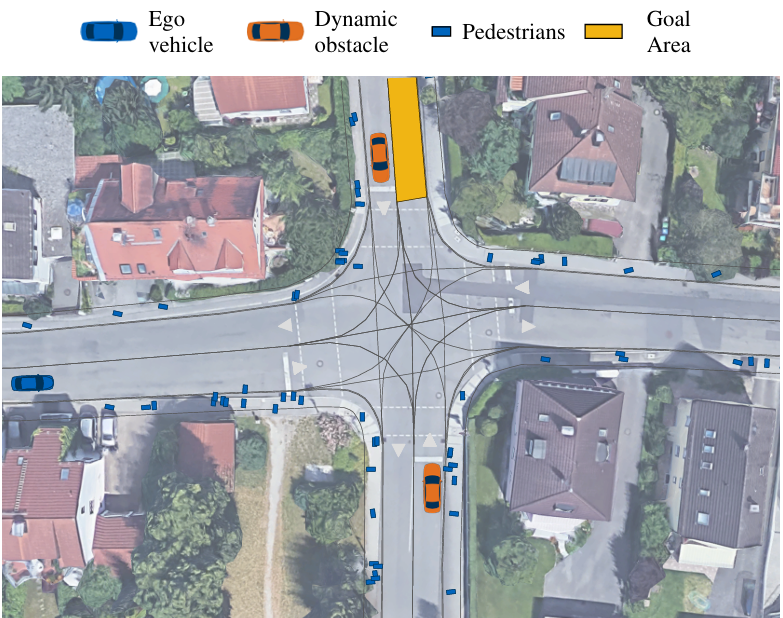
核心创新点:
1. 社会力模型驱动的行人仿真框架
提出基于改进社会力模型(Social Force Model)的行人行为仿真模块,集成于CommonRoad环境,首次实现对城市结构化场景(人行道/斑马线)的细粒度建模。通过离线值迭代生成行人路径策略,动态响应车辆交互(如避让高速车辆),解决了传统仿真中行人行为僵化及局部极小值问题。
2. 风险-伤害联合评估的运动规划算法
开发风险感知运动规划器,创新性地融合碰撞概率(Collision Probability)与伤害值(Harm Metric)构建风险评估框架。采用逻辑回归模型量化MAIS3+级伤害概率,并基于Maximin原则筛选轨迹,突破传统仅依赖碰撞概率的局限,有效缓解"机器人冻结"问题。
3. 车辆-行人耦合预测机制
行人运动预测采用常速模型结合车辆预测的BND(Bivariate Normal Distribution)不确定性建模,车辆端集成Wale-Net预测动态障碍物轨迹。通过蒙特卡洛采样与解析法混合计算碰撞概率,提升复杂交互场景的决策鲁棒性。
4. 开源验证体系构建
首次公开行人-车辆耦合仿真代码库(基于CommonRoad扩展),包含可复现的行人策略生成器与风险评估模块,为自动驾驶在密集人群场景的研究提供标准化测试基准。
强化学习运动规划综述
论文标题:A Survey of Reinforcement Learning-Based Motion Planning for Autonomous Driving: Lessons Learned from a Driving Task Perspective
论文链接:https://arxiv.org/abs/2503.23650
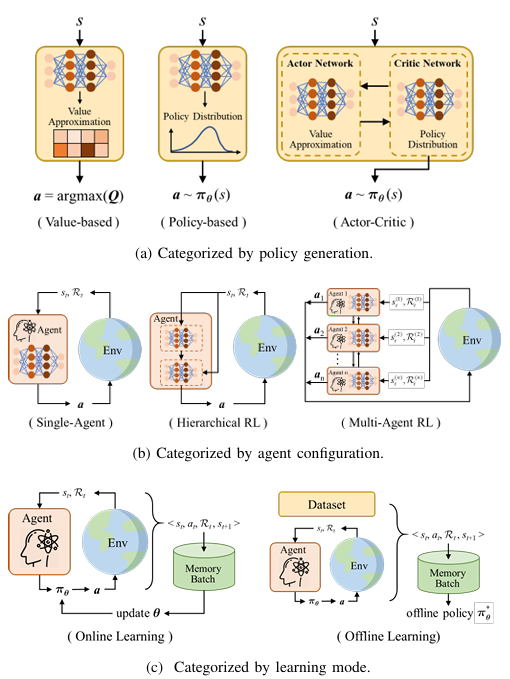
核心创新点:
1. 安全增强的强化学习框架
提出对抗性约束RL与控制屏障函数(CBF)融合方法,通过动态不确定环境下的鲁棒性约束优化,解决自动驾驶中的安全临界场景(如紧急避撞)
基于模型不确定性的风险敏感型算法,采用分布鲁棒策略优化(DRPO)实现碰撞概率的显式约束
2. 多智能体与分层强化学习架构
构建分层决策架构,将驾驶任务解耦为策略层(宏观行为决策)与执行层(轨迹规划),通过Option框架实现层次化策略优化
提出多智能体深度RL(MADRL)协同机制,采用注意力机制建模交通参与者交互,解决多车博弈场景下的策略收敛性问题
3. 持续学习与知识迁移方法
开发基于弹性权重固化(EWC)的持续RL框架,通过参数重要性评估缓解灾难性遗忘,实现跨场景策略迁移
提出混合专家系统(MoE)与元学习结合的元策略迁移方法,在匝道汇入等动态场景中提升策略适应效率
4. 基于模仿学习的高效探索策略
创新性结合专家示范与好奇心驱动机制,采用优先经验回放(PER)与逆RL联合训练,将人类驾驶数据的利用率提升40%
设计基于参数化动作空间的深度Q网络,通过混合离散-连续动作建模解决传统方法在复杂场景中的维度爆炸问题
5. 泛化能力增强技术
提出元强化学习与因果推理融合框架,通过干预变量建模提升策略在未见过的交通场景中的适应性
开发基于神经过程(Neural Process)的上下文感知RL,实现动态环境特征的快速推理与策略调整
Vision-Language Model Predictive Control
论文标题:Vision-Language Model Predictive Control for Manipulation Planning and Trajectory Generation
论文链接:https://arxiv.org/abs/2504.05225
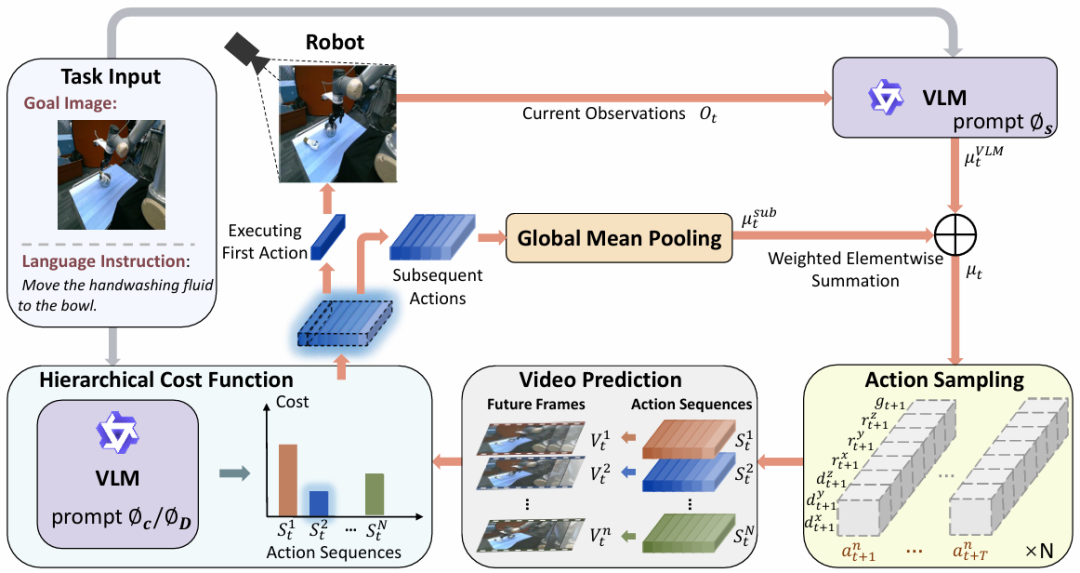
核心创新点:
1. 提出视觉-语言模型预测控制(VLMPC)框架
将视觉-语言模型(VLM)与模型预测控制(MPC)相结合,通过VLM的感知能力和MPC的前瞻性规划能力,解决了传统MPC在复杂、非结构化场景中缺乏环境感知的局限性。VLMPC能够基于目标图像或语言指令生成候选动作序列,并利用视频预测模型模拟未来状态,从而实现精准的机器人操作规划。
2. 设计条件动作采样模块和层次化成本函数
条件动作采样:通过VLM生成基于视觉观察和任务目标的动作采样分布,避免了手动设计动作原语,提升了动作生成的灵活性和适应性。
层次化成本函数:结合像素级成本(评估视频预测与目标图像的相似性)和知识级成本(通过VLM动态识别子目标和干扰物),实现了从粗到细的多层级动作评估,显著提高了复杂任务的规划能力。
3. 提出轨迹优化的增强版框架(Traj-VLMPC)
Traj-VLMPC通过引入高斯混合模型(GMM)生成3D运动轨迹,并结合体素化3D价值图进行高效轨迹评估。相比于逐帧动作采样的VLMPC,Traj-VLMPC显著降低了计算复杂度,同时增强了轨迹规划的稳定性和避障能力,特别适用于长时域任务和实时应用。
4. 实验验证与性能提升
在模拟和真实场景中验证了VLMPC和Traj-VLMPC的有效性,证明其在多种操作任务中优于现有方法。
Traj-VLMPC在长时域任务中表现出更高的控制稳定性和执行速度,特别是在涉及多个子目标和干扰物的复杂任务中表现突出。
本文均出出自『自动驾驶之心知识星球』硬核资料在星球置顶链接,加入即可获取:
行业招聘信息&独家内推;
自驾学习视频&资料;
前沿技术每日更新;




















 3411
3411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









