







库API文档: https://huggingface.co/transformers/
版本号:4.3.0
序言
Transformers库应该算是一个比较新的项目,截至2021年3月2日,当中已经收录了不少arxiv上2020年发表的论文的模型代码,通过这个库可以非常轻松的调取最先进的,包括BERT在内的深度学习模型(以自然语言处理领域的模型为主),并且可以使用PyTorch或TensorFlow 2.x进行继续训练或微调。
相对于Tensorhub需要翻墙,目前在网络情况不错的情况下,从huggingface上下载模型的镜像文件还是非常快的,也是目前PyTorch调取BERT模型的主流方案,当然TensorFlow调取BERT模型可以通过BERT官方项目下的README中的方法,笔者之前也写过相关的文章做,但是笔者发现更新到TensorFlow 2.x后,很多之前的方法都不能适用了,因此这个Transformers库还是非常重要的。
跟之前的DGL库类似,笔者主要是做了API文档的翻译工作,大部分有用的内容笔者都已经摘录,省略的基本上都是不太重要的内容,并加了一些笔者注释,可以用于介绍和快速上手(这个库使用起来还是比较简单的)。
第一部分: 入门
快速上手
从管道模型开始上手
Translation from https://huggingface.co/transformers/quicktour.html ;
- 管道(pipeline):
- 任务类型:
- (1) 情感分析(Sentiment analysis): 判断文本是积极的或是消极的;
- (2) 文本生成(Text generation): 根据某种提示生成一段相关文本;
- (3) 命名实体识别(Name entity recognition): 判断语句中的某个分词属于何种类型;
- (4) 问答系统(Question answering): 根据上下文和问题生成答案;
- (5) 缺失文本填充(Filling masked text): 还原被挖去某些单词的语句;
- (6) 文本综述(Summarization): 根据长文本生成总结性的文字;
- (7) 机器翻译(Translation): 将某种语言的文本翻译成另一种语言;
- (8)特征挖掘(Feature extraction): 生成文本的张量表示;
- 以情感分析为例, 给出一个快速上手的示例:
from transformers import pipeline nlp = pipeline("sentiment-analysis") result = nlp("I hate you")[0] print(f"label: {result['label']}, with score: {round(result['score'], 4)}") result = nlp("I love you")[0] print(f"label: {result['label']}, with score: {round(result['score'], 4)}")- 该管道模型从distilbert-base-uncased-finetuned-sst-2-english 处下载获得, 如果需要指定使用哪种特定的模型, 可以设置
model参数, 获取从model hub 上储存的模型, 如下面这个模型除了可以处理英文外, 还可以处理法语, 意大利语, 荷兰语:
from transformers import pipeline classifier = pipeline('sentiment-analysis', model="nlptown/bert-base-multilingual-uncased-sentiment")- 关于这些模型的参数可以到huggingface页面上去查阅README文件;
- 通常可以为管道模型添加
tokenizer参数, 即指定好分词器, transformers库中已经提供了相应的模块AutoModelForSequenceClassification或TFAutoModelForSequenceClassification:# PyTorch from transformers import AutoTokenizer, AutoModelForSequenceClassification model_name = "nlptown/bert-base-multilingual-uncased-sentiment" model = AutoModelForSequenceClassification.from_pretrained(model_name) tokenizer = AutoTokenizer.from_pretrained(model_name) classifier = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer) # TensorFlow from transformers import AutoTokenizer, TFAutoModelForSequenceClassification model_name = "nlptown/bert-base-multilingual-uncased-sentiment" # This model only exists in PyTorch, so we use the `from_pt` flag to import that model in TensorFlow. model = TFAutoModelForSequenceClassification.from_pretrained(model_name, from_pt=True) tokenizer = AutoTokenizer.from_pretrained(model_name) classifier = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer)
- 如果需要在特定的数据集上微调这些预训练管道模型, 可以参考Example ;
- 该管道模型从distilbert-base-uncased-finetuned-sst-2-english 处下载获得, 如果需要指定使用哪种特定的模型, 可以设置
- 其他任务的管道模型调用详细方法可以参考task summary , 以下是一个序列分类(sequence classification)的示例代码;
# PyTorch from transformers import AutoTokenizer, AutoModelForSequenceClassification import torch tokenizer = AutoTokenizer.from_pretrained("bert-base-cased-finetuned-mrpc") model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased-finetuned-mrpc") classes = ["not paraphrase", "is paraphrase"] sequence_0 = "The company HuggingFace is based in New York City" sequence_1 = "Apples are especially bad for your health" sequence_2 = "HuggingFace's headquarters are situated in Manhattan" paraphrase = tokenizer(sequence_0, sequence_2, return_tensors="pt") not_paraphrase = tokenizer(sequence_0, sequence_1, return_tensors="pt") paraphrase_classification_logits = model(**paraphrase).logits not_paraphrase_classification_logits = model(**not_paraphrase).logits paraphrase_results = torch.softmax(paraphrase_classification_logits, dim=1).tolist()[0] not_paraphrase_results = torch.softmax(not_paraphrase_classification_logits, dim=1).tolist()[0] # Should be paraphrase for i in range(len(classes)): print(f"{classes[i]}: {int(round(paraphrase_results[i] * 100))}%") # Should not be paraphrase for i in range(len(classes)): print(f"{classes[i]}: {int(round(not_paraphrase_results[i] * 100))}%") # TensorFlow from transformers import AutoTokenizer, TFAutoModelForSequenceClassification import tensorflow as tf tokenizer = AutoTokenizer.from_pretrained("bert-base-cased-finetuned-mrpc") model = TFAutoModelForSequenceClassification.from_pretrained("bert-base-cased-finetuned-mrpc") classes = ["not paraphrase", "is paraphrase"] sequence_0 = "The company HuggingFace is based in New York City" sequence_1 = "Apples are especially bad for your health" sequence_2 = "HuggingFace's headquarters are situated in Manhattan" paraphrase = tokenizer(sequence_0, sequence_2, return_tensors="tf") not_paraphrase = tokenizer(sequence_0, sequence_1, return_tensors="tf") paraphrase_classification_logits = model(paraphrase)[0] not_paraphrase_classification_logits = model(not_paraphrase)[0] paraphrase_results = tf.nn.softmax(paraphrase_classification_logits, axis=1).numpy()[0] not_paraphrase_results = tf.nn.softmax(not_paraphrase_classification_logits, axis=1).numpy()[0] # Should be paraphrase for i in range(len(classes)): print(f"{classes[i]}: {int(round(paraphrase_results[i] * 100))}%") # Should not be paraphrase for i in range(len(classes)): print(f"{classes[i]}: {int(round(not_paraphrase_results[i] * 100))}%")
调用管道模型时在做什么
- 使用分词器(tokenizer): 事实上所有的模型和分词器都是通过
from_pretrained方法创建得到的, 一般;
- 示例: 注意到调用模型和分词器的
AutoTokenizer和AutoModelForSequenceClassification是一个高层的接口类, 也可以根据不同的模型调用不同的类, 如distilbert-base-uncased-finetuned-sst-2-english模型对应的就是DistilBertTokenizer和DistilBertForSequenceClassification;# PyTorch from transformers import AutoTokenizer, AutoModelForSequenceClassification # method 1 model_name = "distilbert-base-uncased-finetuned-sst-2-english" pt_model = AutoModelForSequenceClassification.from_pretrained(model_name) tokenizer = AutoTokenizer.from_pretrained(model_name) inputs = tokenizer("We are very happy to show you the 🤗 Transformers library.") # method 2 from transformers import DistilBertTokenizer, DistilBertForSequenceClassification model_name = "distilbert-base-uncased-finetuned-sst-2-english" model = DistilBertForSequenceClassification.from_pretrained(model_name) tokenizer = DistilBertTokenizer.from_pretrained(model_name) # TensorFlow # method 1 from transformers import AutoTokenizer, TFAutoModelForSequenceClassification model_name = "distilbert-base-uncased-finetuned-sst-2-english" tf_model = TFAutoModelForSequenceClassification.from_pretrained(model_name) tokenizer = AutoTokenizer.from_pretrained(model_name)\ inputs = tokenizer("We are very happy to show you the 🤗 Transformers library.") # method 2 from transformers import DistilBertTokenizer, TFDistilBertForSequenceClassification model_name = "distilbert-base-uncased-finetuned-sst-2-english" model = TFDistilBertForSequenceClassification.from_pretrained(model_name) tokenizer = DistilBertTokenizer.from_pretrained(model_name) print(inputs)- 输出结果: 分词的编号与一些其他对于模型训练有用的信息;
{'input_ids': [101, 2057, 2024, 2200, 3407, 2000, 2265, 2017, 1996, 100, 19081, 3075, 1012, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]} - 多语句分词:
batch = tokenizer( ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."], padding=True, truncation=True, max_length=512, return_tensors="pt" # change to "tf" for got TensorFlow ) for key, value in batch.items(): print(f"{key}: {value.numpy().tolist()}")- 输出结果:
input_ids: [[101, 2057, 2024, 2200, 3407, 2000, 2265, 2017, 1996, 100, 19081, 3075, 1012, 102], [101, 2057, 3246, 2017, 2123, 1005, 1056, 5223, 2009, 1012, 102, 0, 0, 0]] attention_mask: [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]] - 更多与分词相关的内容可以参考Preprocessing data ;
- 使用预训练模型: 经过分词器预处理后的数据可以直接输入到模型中, 正如上文所述, 分词器的输出包含了模型所需的所有信息:
- 示例: 注意PyTorch版本需要打包字典输入;
# PyTorch # import torch # pt_outputs = pt_model(**pt_batch, labels = torch.tensor([1, 0])) # add labels outputs = pt_model(**pt_batch) print(outputs) # TensorFlow # import tensorflow as tf # tf_outputs = tf_model(tf_batch, labels = tf.constant([1, 0])) # add labels outputs = tf_model(tf_batch) print(outputs)- 输出结果:
(tensor([[-4.0833, 4.3364], [ 0.0818, -0.0418]], grad_fn=<AddmmBackward>),) (<tf.Tensor: shape=(2, 2), dtype=float32, numpy= array([[-4.0832963 , 4.336414 ], [ 0.08181786, -0.04179301]], dtype=float32)>,)- 重点注意: 输出结果是去除了模型最后一个激活层(如
softmax等激活函数)的输出, 这在所有transformers库中的模型都是通用的, 原因是最后一个激活层会和损失函数相融合(fused with loss)
- 将输出结果手动激活:
# PyTorch import torch.nn.functional as F predictions = F.softmax(outputs[0], dim=-1) # TensorFlow import tensorflow as tf predictions = tf.nn.softmax(outputs[0], axis=-1) - 预训练模型本身都是
torch.nn.Module或tensorflow.keras.Model类型的, 因此可以在PyTorch或TensorFlow的框架下进行训练, 其中transformers库提供了训练模块Trainer和TFTrainer, 详细的训练微调方法可以参考training tutorial ;- 训练微调后的分词器或模型可以保存并重新加载使用:
tokenizer.save_pretrained(save_directory) model.save_pretrained(save_directory) tokenizer = AutoTokenizer.from_pretrained(save_directory) model = AutoModel.from_pretrained(save_directory, from_tf=True)- 返回模型的隐层状态以及所有的注意力权重:
# PyTorch pt_outputs = pt_model(**pt_batch, output_hidden_states=True, output_attentions=True) all_hidden_states, all_attentions = pt_outputs[-2:] # TensorFlow tf_outputs = tf_model(tf_batch, output_hidden_states=True, output_attentions=True) all_hidden_states, all_attentions = tf_outputs[-2:] - 可以通过设置
config参数来调整模型的架构, 一些简单的配置参数也可以直接在from_pretrained方法中设置:# PyTorch from transformers import DistilBertConfig, DistilBertTokenizer, DistilBertForSequenceClassification config = DistilBertConfig(n_heads=8, dim=512, hidden_dim=4*512) tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased') model = DistilBertForSequenceClassification(config) from transformers import DistilBertConfig, DistilBertTokenizer, DistilBertForSequenceClassification model_name = "distilbert-base-uncased" model = DistilBertForSequenceClassification.from_pretrained(model_name, num_labels=10) tokenizer = DistilBertTokenizer.from_pretrained(model_name) # TensorFlow from transformers import DistilBertConfig, DistilBertTokenizer, TFDistilBertForSequenceClassification config = DistilBertConfig(n_heads=8, dim=512, hidden_dim=4*512) tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased') model = TFDistilBertForSequenceClassification(config) from transformers import DistilBertConfig, DistilBertTokenizer, TFDistilBertForSequenceClassification model_name = "distilbert-base-uncased" model = TFDistilBertForSequenceClassification.from_pretrained(model_name, num_labels=10) tokenizer = DistilBertTokenizer.from_pretrained(model_name)
安装transformers
- 详细可见https://huggingface.co/transformers/installation.html , 一般直接使用
pip安装即可, 如果尚未安装TensorFlow或PyTorch可以参考链接中的指令合并安装;- 这里特别地提到一个可以在移动设备上运行的Transformer模型, 具体项目地址在GitHub@swift-coreml-transformers , 是基于iOS系统开发的深度学习模型;
哲学
- 这一章节其实是在讲Transformers库建立的思路, 该库主要由三个类构成:
- (1) Model类: 如
BertModel, 目前收录有超过30个PyTorch模型或Keras模型; - (2) Configuration类: 如
BertConfig, 用于存储搭建模型的参数; - (3) Tokenizer类: 如
BertTokenizer, 用于存储分词词汇表以及编码方式; - 使用
from_pretrained()和save_pretrained()方法来调用和保存这三种类的实例对象;
- 这里文档中提到一个耐人寻味的东西:
- The code is usually as close to the original code base as possible which means some PyTorch code may be not as pytorchic as it could be as a result of being converted TensorFlow code and vice versa.
- 即便如此, 官方文档中也写了这样的预期目标: Switch easily between PyTorch and TensorFlow 2.0, allowing training using one framework and inference using another.
- 笔者是觉得第一句话说的是从TensorFlow移植到PyTorch的模型可能会失效, 言外之意似乎还是TensorFlow要比PyTorch主流一些的;
术语汇编
- 本节主要是对Transformers模型中的一些术语, 包括位置编码(positional encoding), 编码器(encoder), 解码器(decoder)等做了一些说明, 拿的是BERT模型调用举的例子, 还是比较有借鉴意义的;
- 这里把记一下代码示例:
# Input IDs from transformers import BertTokenizer tokenizer = BertTokenizer.from_pretrained("bert-base-cased") sequence = "A Titan RTX has 24GB of VRAM" tokenized_sequence = tokenizer.tokenize(sequence) print(tokenized_sequence) # ['A', 'Titan', 'R', '##T', '##X', 'has', '24', '##GB', 'of', 'V', '##RA', '##M'] inputs = tokenizer(sequence) encoded_sequence = inputs["input_ids"] print(encoded_sequence) # [101, 138, 18696, 155, 1942, 3190, 1144, 1572, 13745, 1104, 159, 9664, 2107, 102] decoded_sequence = tokenizer.decode(encoded_sequence) print(decoded_sequence) # [CLS] A Titan RTX has 24GB of VRAM [SEP] # Attention mask from transformers import BertTokenizer tokenizer = BertTokenizer.from_pretrained("bert-base-cased") sequence_a = "This is a short sequence." sequence_b = "This is a rather long sequence. It is at least longer than the sequence A." encoded_sequence_a = tokenizer(sequence_a)["input_ids"] encoded_sequence_b = tokenizer(sequence_b)["input_ids"] print(len(encoded_sequence_a), len(encoded_sequence_b)) # 8, 19 padded_sequences = tokenizer([sequence_a, sequence_b], padding=True) print(padded_sequences["input_ids"]) # [[101, 1188, 1110, 170, 1603, 4954, 119, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [101, 1188, 1110, 170, 1897, 1263, 4954, 119, 1135, 1110, 1120, 1655, 2039, 1190, 1103, 4954, 138, 119, 102]] print(padded_sequences["attention_mask"]) # [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]] # Token Type IDs from transformers import BertTokenizer tokenizer = BertTokenizer.from_pretrained("bert-base-cased") sequence_a = "HuggingFace is based in NYC" sequence_b = "Where is HuggingFace based?" encoded_dict = tokenizer(sequence_a, sequence_b) decoded = tokenizer.decode(encoded_dict["input_ids"]) print(decoded) # [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1] print(encoded_dict['token_type_ids']) # [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]
第二部分: 基础使用手册
任务汇总
序列分类
- 代码示例:
# PyTorch from transformers import AutoTokenizer, AutoModelForSequenceClassification import torch tokenizer = AutoTokenizer.from_pretrained("bert-base-cased-finetuned-mrpc") model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased-finetuned-mrpc") classes = ["not paraphrase", "is paraphrase"] sequence_0 = "The company HuggingFace is based in New York City" sequence_1 = "Apples are especially bad for your health" sequence_2 = "HuggingFace's headquarters are situated in Manhattan" paraphrase = tokenizer(sequence_0, sequence_2, return_tensors="pt") not_paraphrase = tokenizer(sequence_0, sequence_1, return_tensors="pt") paraphrase_classification_logits = model(**paraphrase).logits not_paraphrase_classification_logits = model(**not_paraphrase).logits paraphrase_results = torch.softmax(paraphrase_classification_logits, dim=1).tolist()[0] not_paraphrase_results = torch.softmax(not_paraphrase_classification_logits, dim=1).tolist()[0] # Should be paraphrase for i in range(len(classes)): print(f"{classes[i]}: {int(round(paraphrase_results[i] * 100))}%") # Should not be paraphrase for i in range(len(classes)): print(f"{classes[i]}: {int(round(not_paraphrase_results[i] * 100))}%") # TensorFlow from transformers import AutoTokenizer, TFAutoModelForSequenceClassification import tensorflow as tf tokenizer = AutoTokenizer.from_pretrained("bert-base-cased-finetuned-mrpc") model = TFAutoModelForSequenceClassification.from_pretrained("bert-base-cased-finetuned-mrpc") classes = ["not paraphrase", "is paraphrase"] sequence_0 = "The company HuggingFace is based in New York City" sequence_1 = "Apples are especially bad for your health" sequence_2 = "HuggingFace's headquarters are situated in Manhattan" paraphrase = tokenizer(sequence_0, sequence_2, return_tensors="tf") not_paraphrase = tokenizer(sequence_0, sequence_1, return_tensors="tf") paraphrase_classification_logits = model(paraphrase)[0] not_paraphrase_classification_logits = model(not_paraphrase)[0] paraphrase_results = tf.nn.softmax(paraphrase_classification_logits, axis=1).numpy()[0] not_paraphrase_results = tf.nn.softmax(not_paraphrase_classification_logits, axis=1).numpy()[0] # Should be paraphrase for i in range(len(classes)): print(f"{classes[i]}: {int(round(paraphrase_results[i] * 100))}%") # Should not be paraphrase for i in range(len(classes)): print(f"{classes[i]}: {int(round(not_paraphrase_results[i] * 100))}%")
问答挖掘
- 关于SQuAD任务的模型微调可以参考run_squad.py 与run_tf_squad.py , 前者的PyTorch脚本似乎已经挂掉了, 只有后者TensorFlow的脚本仍然是有效的了;
- 简单示例一:
from transformers import pipeline nlp = pipeline("question-answering") context = r""" Extractive Question Answering is the task of extracting an answer from a text given a question. An example of a question answering dataset is the SQuAD dataset, which is entirely based on that task. If you would like to fine-tune a model on a SQuAD task, you may leverage the examples/question-answering/run_squad.py script. """ result = nlp(question="What is extractive question answering?", context=context) print(f"Answer: '{result['answer']}', score: {round(result['score'], 4)}, start: {result['start']}, end: {result['end']}") # Answer: 'the task of extracting an answer from a text given a question.', score: 0.6226, start: 34, end: 96 result = nlp(question="What is a good example of a question answering dataset?", context=context) print(f"Answer: '{result['answer']}', score: {round(result['score'], 4)}, start: {result['start']}, end: {result['end']}") # Answer: 'SQuAD dataset,', score: 0.5053, start: 147, end: 161 - 简单示例二:
# PyTorch from transformers import AutoTokenizer, AutoModelForQuestionAnswering import torch tokenizer = AutoTokenizer.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad") model = AutoModelForQuestionAnswering.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad") text = r""" 🤗 Transformers (formerly known as pytorch-transformers and pytorch-pretrained-bert) provides general-purpose architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet…) for Natural Language Understanding (NLU) and Natural Language Generation (NLG) with over 32+ pretrained models in 100+ languages and deep interoperability between TensorFlow 2.0 and PyTorch. """ questions = [ "How many pretrained models are available in 🤗 Transformers?", "What does 🤗 Transformers provide?", "🤗 Transformers provides interoperability between which frameworks?", ] for question in questions: inputs = tokenizer(question, text, add_special_tokens=True, return_tensors="pt") input_ids = inputs["input_ids"].tolist()[0] text_tokens = tokenizer.convert_ids_to_tokens(input_ids) outputs = model(**inputs) answer_start_scores = outputs.start_logits answer_end_scores = outputs.end_logits answer_start = torch.argmax( answer_start_scores ) # Get the most likely beginning of answer with the argmax of the score answer_end = torch.argmax(answer_end_scores) + 1 # Get the most likely end of answer with the argmax of the score answer = tokenizer.convert_tokens_to_string(tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])) print(f"Question: {question}") print(f"Answer: {answer}") # TensorFlow from transformers import AutoTokenizer, TFAutoModelForQuestionAnswering import tensorflow as tf tokenizer = AutoTokenizer.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad") model = TFAutoModelForQuestionAnswering.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad") text = r""" 🤗 Transformers (formerly known as pytorch-transformers and pytorch-pretrained-bert) provides general-purpose architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet…) for Natural Language Understanding (NLU) and Natural Language Generation (NLG) with over 32+ pretrained models in 100+ languages and deep interoperability between TensorFlow 2.0 and PyTorch. """ questions = [ "How many pretrained models are available in 🤗 Transformers?", "What does 🤗 Transformers provide?", "🤗 Transformers provides interoperability between which frameworks?", ] for question in questions: inputs = tokenizer(question, text, add_special_tokens=True, return_tensors="tf") input_ids = inputs["input_ids"].numpy()[0] text_tokens = tokenizer.convert_ids_to_tokens(input_ids) outputs = model(inputs) answer_start_scores = outputs.start_logits answer_end_scores = outputs.end_logits answer_start = tf.argmax( answer_start_scores, axis=1 ).numpy()[0] # Get the most likely beginning of answer with the argmax of the score answer_end = ( tf.argmax(answer_end_scores, axis=1) + 1 ).numpy()[0] # Get the most likely end of answer with the argmax of the score answer = tokenizer.convert_tokens_to_string(tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])) print(f"Question: {question}") print(f"Answer: {answer}")- 输出结果:
Question: How many pretrained models are available in 🤗 Transformers? Answer: over 32 + Question: What does 🤗 Transformers provide? Answer: general - purpose architectures Question: 🤗 Transformers provides interoperability between which frameworks? Answer: tensorflow 2 . 0 and pytorch
语言模型
- 语言模型一般是根据特定领域的语料库训练得到的;
- 收录的某个语言模型: arxiv-nlp@lysandre
带掩码的语言模型
- Masked Language Modeling: 即通过挖去语句中的部分单词,对这些单词进行预测得到的结果;
- 示例一:
from transformers import pipeline nlp = pipeline("fill-mask") from pprint import pprint pprint(nlp(f"HuggingFace is creating a {nlp.tokenizer.mask_token} that the community uses to solve NLP tasks."))- 输出结果:
[{'score': 0.1792745739221573, 'sequence': '<s>HuggingFace is creating a tool that the community uses to ' 'solve NLP tasks.</s>', 'token': 3944, 'token_str': 'Ġtool'}, {'score': 0.11349421739578247, 'sequence': '<s>HuggingFace is creating a framework that the community uses ' 'to solve NLP tasks.</s>', 'token': 7208, 'token_str': 'Ġframework'}, {'score': 0.05243554711341858, 'sequence': '<s>HuggingFace is creating a library that the community uses to ' 'solve NLP tasks.</s>', 'token': 5560, 'token_str': 'Ġlibrary'}, {'score': 0.03493533283472061, 'sequence': '<s>HuggingFace is creating a database that the community uses ' 'to solve NLP tasks.</s>', 'token': 8503, 'token_str': 'Ġdatabase'}, {'score': 0.02860250137746334, 'sequence': '<s>HuggingFace is creating a prototype that the community uses ' 'to solve NLP tasks.</s>', 'token': 17715, 'token_str': 'Ġprototype'}] - 示例二:
# PyTorch from transformers import AutoModelWithLMHead, AutoTokenizer import torch tokenizer = AutoTokenizer.from_pretrained("distilbert-base-cased") model = AutoModelWithLMHead.from_pretrained("distilbert-base-cased") sequence = f"Distilled models are smaller than the models they mimic. Using them instead of the large versions would help {tokenizer.mask_token} our carbon footprint." input = tokenizer.encode(sequence, return_tensors="pt") mask_token_index = torch.where(input == tokenizer.mask_token_id)[1] token_logits = model(input).logits mask_token_logits = token_logits[0, mask_token_index, :] top_5_tokens = torch.topk(mask_token_logits, 5, dim=1).indices[0].tolist() # TensorFlow from transformers import TFAutoModelWithLMHead, AutoTokenizer import tensorflow as tf tokenizer = AutoTokenizer.from_pretrained("distilbert-base-cased") model = TFAutoModelWithLMHead.from_pretrained("distilbert-base-cased") sequence = f"Distilled models are smaller than the models they mimic. Using them instead of the large versions would help {tokenizer.mask_token} our carbon footprint." input = tokenizer.encode(sequence, return_tensors="tf") mask_token_index = tf.where(input == tokenizer.mask_token_id)[0, 1] token_logits = model(input)[0] mask_token_logits = token_logits[0, mask_token_index, :] top_5_tokens = tf.math.top_k(mask_token_logits, 5).indices.numpy() for token in top_5_tokens: print(sequence.replace(tokenizer.mask_token, tokenizer.decode([token])))- 输出结果:
Distilled models are smaller than the models they mimic. Using them instead of the large versions would help reduce our carbon footprint. Distilled models are smaller than the models they mimic. Using them instead of the large versions would help increase our carbon footprint. Distilled models are smaller than the models they mimic. Using them instead of the large versions would help decrease our carbon footprint. Distilled models are smaller than the models they mimic. Using them instead of the large versions would help offset our carbon footprint. Distilled models are smaller than the models they mimic. Using them instead of the large versions would help improve our carbon footprint.
因果语言模型
- Causal Language Modeling: 即通过n-gram单词序列预测下一个单词的方法;
- 示例:
# PyTorch from transformers import AutoModelWithLMHead, AutoTokenizer, top_k_top_p_filtering import torch from torch.nn import functional as F tokenizer = AutoTokenizer.from_pretrained("gpt2") model = AutoModelWithLMHead.from_pretrained("gpt2") sequence = f"Hugging Face is based in DUMBO, New York City, and " input_ids = tokenizer.encode(sequence, return_tensors="pt") # get logits of last hidden state next_token_logits = model(input_ids).logits[:, -1, :] # filter filtered_next_token_logits = top_k_top_p_filtering(next_token_logits, top_k=50, top_p=1.0) # sample probs = F.softmax(filtered_next_token_logits, dim=-1) next_token = torch.multinomial(probs, num_samples=1) generated = torch.cat([input_ids, next_token], dim=-1) resulting_string = tokenizer.decode(generated.tolist()[0]) # TensorFlow from transformers import TFAutoModelWithLMHead, AutoTokenizer, tf_top_k_top_p_filtering import tensorflow as tf tokenizer = AutoTokenizer.from_pretrained("gpt2") model = TFAutoModelWithLMHead.from_pretrained("gpt2") sequence = f"Hugging Face is based in DUMBO, New York City, and " input_ids = tokenizer.encode(sequence, return_tensors="tf") # get logits of last hidden state next_token_logits = model(input_ids)[0][:, -1, :] # filter filtered_next_token_logits = tf_top_k_top_p_filtering(next_token_logits, top_k=50, top_p=1.0) # sample next_token = tf.random.categorical(filtered_next_token_logits, dtype=tf.int32, num_samples=1) generated = tf.concat([input_ids, next_token], axis=1) resulting_string = tokenizer.decode(generated.numpy().tolist()[0]) print(resulting_string)- 输出结果:
Hugging Face is based in DUMBO, New York City, and has
文本生成
- 文本生成任务, 又称为自然语言生成(Natural Language Generation, NLG)的类型给是比较多的, 比如data-to-text等, 下面给出示例是根据一段文本进行续写的任务;
- 示例:
from transformers import pipeline text_generator = pipeline("text-generation") print(text_generator("As far as I am concerned, I will", max_length=50, do_sample=False)) - 另一个根据某种意图进行续写的模型XLNet:
# PyTorch from transformers import AutoModelWithLMHead, AutoTokenizer model = AutoModelWithLMHead.from_pretrained("xlnet-base-cased") tokenizer = AutoTokenizer.from_pretrained("xlnet-base-cased") # Padding text helps XLNet with short prompts - proposed by Aman Rusia in https://github.com/rusiaaman/XLNet-gen#methodology PADDING_TEXT = """In 1991, the remains of Russian Tsar Nicholas II and his family (except for Alexei and Maria) are discovered. The voice of Nicholas's young son, Tsarevich Alexei Nikolaevich, narrates the remainder of the story. 1883 Western Siberia, a young Grigori Rasputin is asked by his father and a group of men to perform magic. Rasputin has a vision and denounces one of the men as a horse thief. Although his father initially slaps him for making such an accusation, Rasputin watches as the man is chased outside and beaten. Twenty years later, Rasputin sees a vision of the Virgin Mary, prompting him to become a priest. Rasputin quickly becomes famous, with people, even a bishop, begging for his blessing. <eod> </s> <eos>""" prompt = "Today the weather is really nice and I am planning on " inputs = tokenizer.encode(PADDING_TEXT + prompt, add_special_tokens=False, return_tensors="pt") prompt_length = len(tokenizer.decode(inputs[0], skip_special_tokens=True, clean_up_tokenization_spaces=True)) outputs = model.generate(inputs, max_length=250, do_sample=True, top_p=0.95, top_k=60) generated = prompt + tokenizer.decode(outputs[0])[prompt_length:] # TensorFlow from transformers import TFAutoModelWithLMHead, AutoTokenizer model = TFAutoModelWithLMHead.from_pretrained("xlnet-base-cased") tokenizer = AutoTokenizer.from_pretrained("xlnet-base-cased") # Padding text helps XLNet with short prompts - proposed by Aman Rusia in https://github.com/rusiaaman/XLNet-gen#methodology PADDING_TEXT = """In 1991, the remains of Russian Tsar Nicholas II and his family (except for Alexei and Maria) are discovered. The voice of Nicholas's young son, Tsarevich Alexei Nikolaevich, narrates the remainder of the story. 1883 Western Siberia, a young Grigori Rasputin is asked by his father and a group of men to perform magic. Rasputin has a vision and denounces one of the men as a horse thief. Although his father initially slaps him for making such an accusation, Rasputin watches as the man is chased outside and beaten. Twenty years later, Rasputin sees a vision of the Virgin Mary, prompting him to become a priest. Rasputin quickly becomes famous, with people, even a bishop, begging for his blessing. <eod> </s> <eos>""" prompt = "Today the weather is really nice and I am planning on " inputs = tokenizer.encode(PADDING_TEXT + prompt, add_special_tokens=False, return_tensors="tf") prompt_length = len(tokenizer.decode(inputs[0], skip_special_tokens=True, clean_up_tokenization_spaces=True)) outputs = model.generate(inputs, max_length=250, do_sample=True, top_p=0.95, top_k=60) generated = prompt + tokenizer.decode(outputs[0])[prompt_length:]- 输出结果:
print(generated) Today the weather is really nice and I am planning on anning on taking a nice...... of a great time!<eop>...............
- 目前收录的一些文本生成模型:
- GPT-2
- OpenAi-GPT
- CTRL
- XLNet
- Transfo-XL
- Reformer
命名实体识别
- 命名实体识别的一个数据集是CoNLL-2003, NER任务用于模型微调的的脚本:
- PyTorch: run_ner.py
- TensorFlow: run_tf_ner.py
- Transformers提供的默认模型是基于CoNLL-2003数据集训练的GitHub@dbmdz
- 管道调用示例:
from transformers import pipeline nlp = pipeline("ner") sequence = "Hugging Face Inc. is a company based in New York City. Its headquarters are in DUMBO, therefore very" "close to the Manhattan Bridge which is visible from the window." print(nlp(sequence))- 输出结果:
[ {'word': 'Hu', 'score': 0.9995632767677307, 'entity': 'I-ORG'}, {'word': '##gging', 'score': 0.9915938973426819, 'entity': 'I-ORG'}, {'word': 'Face', 'score': 0.9982671737670898, 'entity': 'I-ORG'}, {'word': 'Inc', 'score': 0.9994403719902039, 'entity': 'I-ORG'}, {'word': 'New', 'score': 0.9994346499443054, 'entity': 'I-LOC'}, {'word': 'York', 'score': 0.9993270635604858, 'entity': 'I-LOC'}, {'word': 'City', 'score': 0.9993864893913269, 'entity': 'I-LOC'}, {'word': 'D', 'score': 0.9825621843338013, 'entity': 'I-LOC'}, {'word': '##UM', 'score': 0.936983048915863, 'entity': 'I-LOC'}, {'word': '##BO', 'score': 0.8987102508544922, 'entity': 'I-LOC'}, {'word': 'Manhattan', 'score': 0.9758241176605225, 'entity': 'I-LOC'}, {'word': 'Bridge', 'score': 0.990249514579773, 'entity': 'I-LOC'} ] - 模型调用实例:
# PyTorch from transformers import AutoModelForTokenClassification, AutoTokenizer import torch model = AutoModelForTokenClassification.from_pretrained("dbmdz/bert-large-cased-finetuned-conll03-english") tokenizer = AutoTokenizer.from_pretrained("bert-base-cased") label_list = [ "O", # Outside of a named entity "B-MISC", # Beginning of a miscellaneous entity right after another miscellaneous entity "I-MISC", # Miscellaneous entity "B-PER", # Beginning of a person's name right after another person's name "I-PER", # Person's name "B-ORG", # Beginning of an organisation right after another organisation "I-ORG", # Organisation "B-LOC", # Beginning of a location right after another location "I-LOC" # Location ] sequence = "Hugging Face Inc. is a company based in New York City. Its headquarters are in DUMBO, therefore very" \ "close to the Manhattan Bridge." # Bit of a hack to get the tokens with the special tokens tokens = tokenizer.tokenize(tokenizer.decode(tokenizer.encode(sequence))) inputs = tokenizer.encode(sequence, return_tensors="pt") outputs = model(inputs).logits predictions = torch.argmax(outputs, dim=2) # TensorFlow from transformers import TFAutoModelForTokenClassification, AutoTokenizer import tensorflow as tf model = TFAutoModelForTokenClassification.from_pretrained("dbmdz/bert-large-cased-finetuned-conll03-english") tokenizer = AutoTokenizer.from_pretrained("bert-base-cased") label_list = [ "O", # Outside of a named entity "B-MISC", # Beginning of a miscellaneous entity right after another miscellaneous entity "I-MISC", # Miscellaneous entity "B-PER", # Beginning of a person's name right after another person's name "I-PER", # Person's name "B-ORG", # Beginning of an organisation right after another organisation "I-ORG", # Organisation "B-LOC", # Beginning of a location right after another location "I-LOC" # Location ] sequence = "Hugging Face Inc. is a company based in New York City. Its headquarters are in DUMBO, therefore very" \ "close to the Manhattan Bridge." # Bit of a hack to get the tokens with the special tokens tokens = tokenizer.tokenize(tokenizer.decode(tokenizer.encode(sequence))) inputs = tokenizer.encode(sequence, return_tensors="tf") outputs = model(inputs)[0] predictions = tf.argmax(outputs, axis=2)- 输出结果:
print([(token, label_list[prediction]) for token, prediction in zip(tokens, predictions[0].numpy())]) [('[CLS]', 'O'), ('Hu', 'I-ORG'), ('##gging', 'I-ORG'), ('Face', 'I-ORG'), ('Inc', 'I-ORG'), ('.', 'O'), ('is', 'O'), ('a', 'O'), ('company', 'O'), ('based', 'O'), ('in', 'O'), ('New', 'I-LOC'), ('York', 'I-LOC'), ('City', 'I-LOC'), ('.', 'O'), ('Its', 'O'), ('headquarters', 'O'), ('are', 'O'), ('in', 'O'), ('D', 'I-LOC'), ('##UM', 'I-LOC'), ('##BO', 'I-LOC'), (',', 'O'), ('therefore', 'O'), ('very', 'O'), ('##c', 'O'), ('##lose', 'O'), ('to', 'O'), ('the', 'O'), ('Manhattan', 'I-LOC'), ('Bridge', 'I-LOC'), ('.', 'O'), ('[SEP]', 'O')]
文本综述
-
定义: 根据一段长文本生成一段总结性质的文字, 常见的应用任务如论文摘要, 新闻标题, 阅读理解等;
-
一个常见的文本综述数据集是CNN / Daily Mail dataset, 包含了长的新闻文章, 关于微调文本综述模型的方法可以参考README
- 示例: 基于CNN / Daily Mail dataset的BART 模型;
from transformers import pipeline summarizer = pipeline("summarization") ARTICLE = """ New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County, New York. A year later, she got married again in Westchester County, but to a different man and without divorcing her first husband. Only 18 days after that marriage, she got hitched yet again. Then, Barrientos declared "I do" five more times, sometimes only within two weeks of each other. In 2010, she married once more, this time in the Bronx. In an application for a marriage license, she stated it was her "first and only" marriage. Barrientos, now 39, is facing two criminal counts of "offering a false instrument for filing in the first degree," referring to her false statements on the 2010 marriage license application, according to court documents. Prosecutors said the marriages were part of an immigration scam. On Friday, she pleaded not guilty at State Supreme Court in the Bronx, according to her attorney, Christopher Wright, who declined to comment further. After leaving court, Barrientos was arrested and charged with theft of service and criminal trespass for allegedly sneaking into the New York subway through an emergency exit, said Detective Annette Markowski, a police spokeswoman. In total, Barrientos has been married 10 times, with nine of her marriages occurring between 1999 and 2002. All occurred either in Westchester County, Long Island, New Jersey or the Bronx. She is believed to still be married to four men, and at one time, she was married to eight men at once, prosecutors say. Prosecutors said the immigration scam involved some of her husbands, who filed for permanent residence status shortly after the marriages. Any divorces happened only after such filings were approved. It was unclear whether any of the men will be prosecuted. The case was referred to the Bronx District Attorney\'s Office by Immigration and Customs Enforcement and the Department of Homeland Security\'s Investigation Division. Seven of the men are from so-called "red-flagged" countries, including Egypt, Turkey, Georgia, Pakistan and Mali. Her eighth husband, Rashid Rajput, was deported in 2006 to his native Pakistan after an investigation by the Joint Terrorism Task Force. If convicted, Barrientos faces up to four years in prison. Her next court appearance is scheduled for May 18. """- 输出结果:
print(summarizer(ARTICLE, max_length=130, min_length=30, do_sample=False)) # [{'summary_text': 'Liana Barrientos, 39, is charged with two counts of "offering a false instrument for filing in the first degree" In total, she has been married 10 times, with nine of her marriages occurring between 1999 and 2002. She is believed to still be married to four men.'}]
- 另一个来自Google的T5模型:
- 代码示例:
# PyTorch from transformers import AutoModelWithLMHead, AutoTokenizer model = AutoModelWithLMHead.from_pretrained("t5-base") tokenizer = AutoTokenizer.from_pretrained("t5-base") # T5 uses a max_length of 512 so we cut the article to 512 tokens. inputs = tokenizer.encode("summarize: " + ARTICLE, return_tensors="pt", max_length=512) outputs = model.generate(inputs, max_length=150, min_length=40, length_penalty=2.0, num_beams=4, early_stopping=True) # TensorFlow from transformers import TFAutoModelWithLMHead, AutoTokenizer model = TFAutoModelWithLMHead.from_pretrained("t5-base") tokenizer = AutoTokenizer.from_pretrained("t5-base") # T5 uses a max_length of 512 so we cut the article to 512 tokens. inputs = tokenizer.encode("summarize: " + ARTICLE, return_tensors="tf", max_length=512) outputs = model.generate(inputs, max_length=150, min_length=40, length_penalty=2.0, num_beams=4, early_stopping=True)
机器翻译
- 这里注意其实文本综述里的那个T5模型也是可以用来进行机器翻译的:
- 示例一:
from transformers import pipeline translator = pipeline("translation_en_to_de") print(translator("Hugging Face is a technology company based in New York and Paris", max_length=40)) # [{'translation_text': 'Hugging Face ist ein Technologieunternehmen mit Sitz in New York und Paris.'}] - 示例二:
# PyTorch from transformers import AutoModelWithLMHead, AutoTokenizer model = AutoModelWithLMHead.from_pretrained("t5-base") tokenizer = AutoTokenizer.from_pretrained("t5-base") inputs = tokenizer.encode("translate English to German: Hugging Face is a technology company based in New York and Paris", return_tensors="pt") outputs = model.generate(inputs, max_length=40, num_beams=4, early_stopping=True) # TensorFlow from transformers import TFAutoModelWithLMHead, AutoTokenizer model = TFAutoModelWithLMHead.from_pretrained("t5-base") tokenizer = AutoTokenizer.from_pretrained("t5-base") inputs = tokenizer.encode("translate English to German: Hugging Face is a technology company based in New York and Paris", return_tensors="tf") outputs = model.generate(inputs, max_length=40, num_beams=4, early_stopping=True) print(tokenizer.decode(outputs[0])) # Hugging Face ist ein Technologieunternehmen mit Sitz in New York und Paris.
模型汇总
- Transformers库中的模型可以分为以下几类:
- 自回归(autoaggressive)模型:
- 自编码(autoencoding)模型: 破坏(corrupting)输入分词序列, 并试图将其用另一种设法重构原始序列, 一般来说这类模型都会对整个语句进行双向(bidirectional)表示, 最经典的模型就是BERT;
- sequence-to-sequence模型: 即使用transformer架构中的编码器与解码器;
- 多模式的(multimodal)模型: 将文本输入转换为其他类型的输出(如图片);
- 基于检索的(retrieval-based)模型;
自回归模型
- Original GPT: 第一个基于transformer架构的自回归模型
- GPT-2: GPT(Generate Pretrained-model)模型的改良版, 基于WebText数据集与训练得到的;
- CTRL: 在GPT基础上加入控制模块, 用于根据意图(prompt)生成一段文本, 如生成文章, 书籍, 电影的评述;
- Transformer-XL: 在GPT基础上加入针对两个连续部分(consecutive segments, 所谓segment如512个连续的tokens)的循环机制(recurrence mechanism), 这类似于带有两个连续输入的常规RNN,
- Reformer: 该模型使用了一些技巧来减少内存占用与计算时间;
- 项目地址: reformer
- 论文链接: Reformer: The Efficient Transformer
- 模型中使用的技巧:
- ① Axial posional encodings: 传统的transformer模型中, 位置编码矩阵 E ∈ N l × d E\in N^{l×d} E∈Nl×d, 其中 l l l是序列长度, d d d是隐层状态的维度, 如果输入文本过长, 则该位置编码矩阵将占用大量内存, 于是一种技巧是将矩阵 E E E分解为两个小矩阵 E 1 ∈ N l 1 × d 1 E_1\in N^{l_1×d_1} E1∈Nl1×d1和 E 2 ∈ N l 2 × d @ E_2\in N^{l_2×d_@} E2∈Nl2×d@, 其中满足 l 1 + l 2 = l l_1+l_2=l l1+l2=l和 d 1 + d 2 = d d_1+d_2=d d1+d2=d, 本质上是在做拆分;
- ② 将传统的注意力机制替换为LSH(local-sensitive hashing)注意力机制, 即在计算激活输出 s o f t m a x ( Q K t ) {\rm softmax}(QK^t) softmax(QKt)时, 只有最大的元素会起到主要的贡献, 因此对于查询矩阵 Q Q Q中的每个元素 q q q, 只需要考虑键矩阵 K K K中与 q q q邻近的元素 k k k即可, 此处会由一个哈希函数来确定 q q q与 k k k是否邻近;
- ③ 避免存储每个层的中间结果;
- ④ 前馈计算操作是按照chunk来计算而非整个batch;
- XLNet: 这不是一个常规的自回归模型, 主要是用掩码(mask)方式来进行token预测;
自编码模型
- BERT: 经典的自然语言处理领域的模型
- ALBERT: 这是一个简化的BERT模型, 减少内存和显存消耗;
- 项目地址: albert
- 论文链接: ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
- 与传统BERT模型的区别:
- ① 嵌入规模 E E E与隐层状态 H H H不同, 因为嵌入是上下文独立的(context-independent, 一个嵌入向量代表一个token), 而隐层状态时上下文依赖的(context-dependent, 一个隐层节点代表一个序列的tokens), 因此 H ≫ E H\gg E H≫E
- ② 网络层通过分组共享参数来节约内存(大约是在将相同的层复制多次, 且维持参数不变);
- ③ ALBERT并非是根据前一个句子预测句子, 而是在给定两个句子
A
A
A和
B
B
B时, 设法判断两个句子的顺序
- 难道说这是用于因果判断的模型?
- RoBERTa:
- 项目地址: roberta
- 论文链接: RoBERTa: A Robustly Optimized BERT Pretraining Approach
- 与传统BERT模型的区别:
- ① 动态掩码(dynamic masking): 在每个epoch中, 每个token都是使用的不同掩码进行掩盖, 而BERT中则是一劳永逸的;
- ② 没有做NSP(next sentence prediction)损失函数, 而只是将两个句子合并;
- ③ 更大的批训练;
- ④ 以字节(bytes)方式使用BPE(Byte-Pair Encoding)而非字符(characters)
- DistilBERT:
- ConvBERT:
- XLM: 一个多语言模型
- 项目地址: xlm
- 论文链接: Cross-lingual Language Model Pretraining
- XLM-RoBERTa:
- FlauBERT:
- ELECTRA:
- Funnel Transformer:
- 项目地址: funnel
- 论文链接: Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing
- Longformer:
序列到序列模型
- 这部分的模型大部分都是encoder-decoder结构的;
- BART:
- 项目地址: bart
- 论文链接: BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
- Pegasus: 与BART架构类似
- MarianMT: *C++*架构的代码
- T5: text-to-text的迁移学习研究, 主要是多语言迁移;
- MT5:
- MBart:
- ProphetNet: 这是一个针对未来n-gram序列的预测的模型
- XLM-ProphetNet:
多模式模型
基于检索的模型
- DPR: Dense Passage Retrieval, 问答系统模型;
- RAG: Dense Passage Retrieval, 问答系统模型;
更多的技术说明
- 全(full)注意力 v.s. 稀疏(sparse)注意力:
- LSH attention: 在Reformer模型中使用的;
- Local attention: 在Longformer模型中使用的;
数据预处理
分词器的详细使用:
- 调用
transformers.AutoTokenizer模块; - 从一个预训练模型初始化分词器对象:
tokenizer = AutoTokenizer.from_pretrained('bert-base-cased') - 对语句进行分词:
encoded_input = tokenizer("Hello, I'm a single sentence!")- 输出结果:
{'input_ids': [101, 138, 18696, 155, 1942, 3190, 1144, 1572, 13745, 1104, 159, 9664, 2107, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]} tokenizer对象可以将分词后的结果解码回正常语句序列:tokenizer.decode(encoded_input["input_ids"]) # "[CLS] Hello, I'm a single sentence! [SEP]"- 可以注意到, 这里分词器为语句添加了一些特殊的token, 这些都是BERT模型分词器中默认的分句标识符;
tokenizer对象可以接受多个语句的输入, 以列表的形式:batch_sentences = ["Hello I'm a single sentence", "And another sentence", "And the very very last one"] encoded_inputs = tokenizer(batch_sentences) print(encoded_inputs)- 输出结果:
{'input_ids': [[101, 8667, 146, 112, 182, 170, 1423, 5650, 102], [101, 1262, 1330, 5650, 102], [101, 1262, 1103, 1304, 1304, 1314, 1141, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1]]}tokenizer对象可以接受多个语句的输入时可以添加一些参数:padding: 是否将语句填充成等长, 可以同时设置max_length参数, 默认为所有语句中的最长值;- 取值范围:
{True, 'longest', 'max_length', 'False', 'do_not_pad'}
- 取值范围:
truncation: 是否将语句截断到模型可接受的最大长度;- 取值范围:
{True, 'only_first', 'only_second', 'longest_first', 'False', 'do_not_truncate'}
- 取值范围:
return_tensors: 返回成何种类型的张量;
batch = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="pt") print(batch) ''' {'input_ids': tensor([[ 101, 8667, 146, 112, 182, 170, 1423, 5650, 102], [ 101, 1262, 1330, 5650, 102, 0, 0, 0, 0], [ 101, 1262, 1103, 1304, 1304, 1314, 1141, 102, 0]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 0]])} '''
预处理一对语句
- 有时候你需要将一对语句输入到模型中, 比如需要判断两个语句的相似性, 抑或是问答系统中需要接受一个上下文和问题;
- 以BERT模型为例, 其输入格式为
[CLS] Sequence A [SEP] Sequence B [SEP] - 当然实际上你直接输入到自动分词器中即可, 它都会为你处理好的:
encoded_input = tokenizer("How old are you?", "I'm 6 years old") print(encoded_input)- 输出结果: 注意到
token_tpye_ids就是用来区分不同语句的标识;
{'input_ids': [101, 1731, 1385, 1132, 1128, 136, 102, 146, 112, 182, 127, 1201, 1385, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]} - 输出结果: 注意到
- 同理也可以将多对语句成对输入到
tokenizer中来:batch_sentences = ["Hello I'm a single sentence", "And another sentence", "And the very very last one"] batch_of_second_sentences = ["I'm a sentence that goes with the first sentence", "And I should be encoded with the second sentence", "And I go with the very last one"] encoded_inputs = tokenizer(batch_sentences, batch_of_second_sentences) print(encoded_inputs)- 输出结果: 注意这些输出的
input_ids同样可以用分词器解码成标准语句;
{'input_ids': [[101, 8667, 146, 112, 182, 170, 1423, 5650, 102, 146, 112, 182, 170, 5650, 1115, 2947, 1114, 1103, 1148, 5650, 102], [101, 1262, 1330, 5650, 102, 1262, 146, 1431, 1129, 12544, 1114, 1103, 1248, 5650, 102], [101, 1262, 1103, 1304, 1304, 1314, 1141, 102, 1262, 146, 1301, 1114, 1103, 1304, 1314, 1141, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]} - 输出结果: 注意这些输出的
关于填充与裁剪参数的说明
- 详见下表:
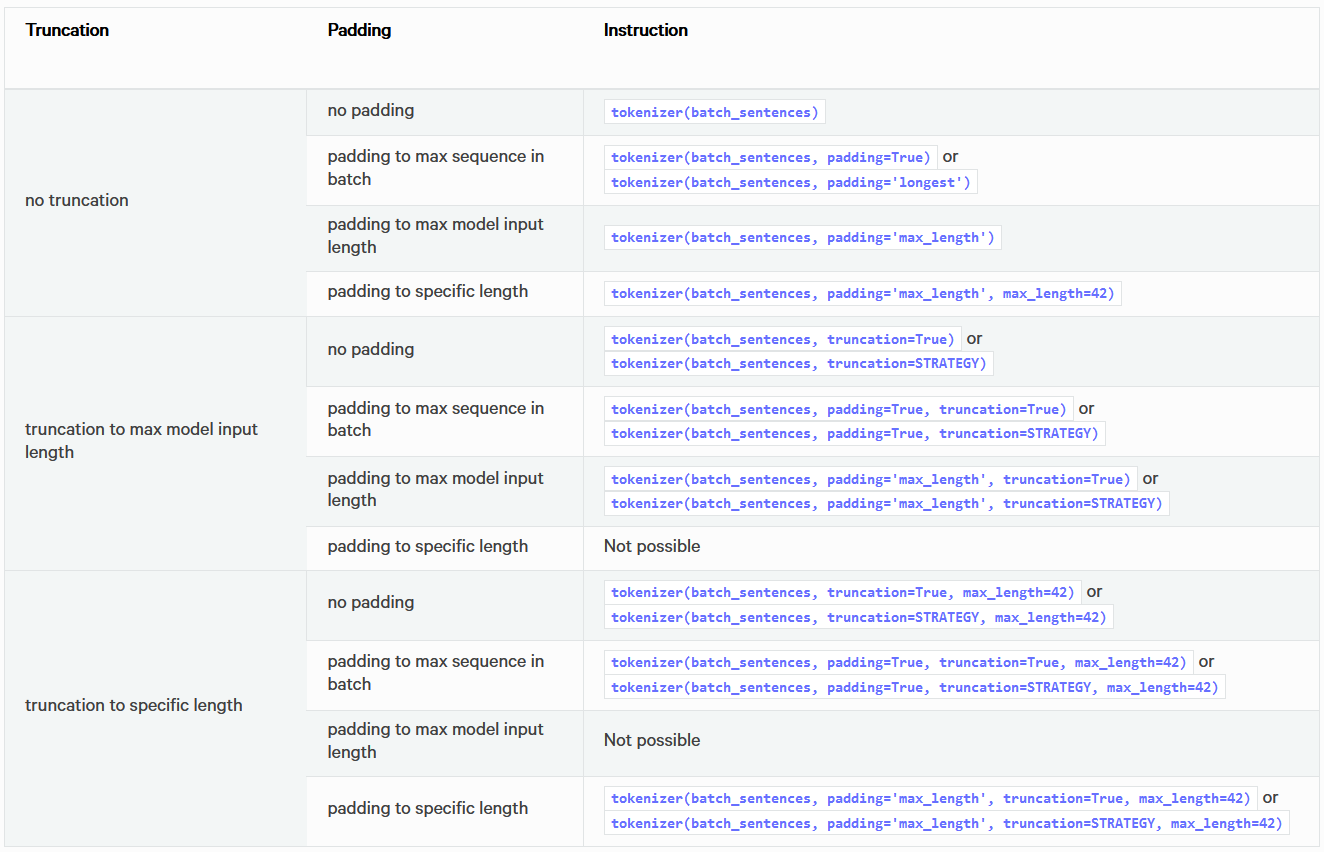
预处理好的分词
tokenizer对象接收已经做好分词的输入, 此时只做编码操作:encoded_input = tokenizer(["Hello", "I'm", "a", "single", "sentence"], is_split_into_words=True) print(encoded_input)- 输出结果:
{'input_ids': [101, 8667, 146, 112, 182, 170, 1423, 5650, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}- 其他一些参数的运用
batch_sentences = [["Hello", "I'm", "a", "single", "sentence"], ["And", "another", "sentence"], ["And", "the", "very", "very", "last", "one"]] batch_of_second_sentences = [["I'm", "a", "sentence", "that", "goes", "with", "the", "first", "sentence"], ["And", "I", "should", "be", "encoded", "with", "the", "second", "sentence"], ["And", "I", "go", "with", "the", "very", "last", "one"]] batch = tokenizer(batch_sentences, batch_of_second_sentences, is_split_into_words=True, padding=True, truncation=True, return_tensors="pt")
训练与微调
- 从Transformers库中摘取的模型本质都是PyTorch或TensorFlow训练得到的模型, 都是可以进行微调的;
PyTorch中的微调
- 以提取得到BERT模型为例:
- (1) 调取模型进入训练模式:
from transformers import BertForSequenceClassification model = BertForSequenceClassification.from_pretrained('bert-base-uncased') model.train() - (2) 初始化优化器:
from transformers import AdamW optimizer = AdamW(model.parameters(), lr=1e-5)- 可以为优化器添加更多的参数:
no_decay = ['bias', 'LayerNorm.weight'] optimizer_grouped_parameters = [ {'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01}, {'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0} ] optimizer = AdamW(optimizer_grouped_parameters, lr=1e-5) - (3) 生成模型的输入:
from transformers import BertTokenizer tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') text_batch = ["I love Pixar.", "I don't care for Pixar."] encoding = tokenizer(text_batch, return_tensors='pt', padding=True, truncation=True) input_ids = encoding['input_ids'] attention_mask = encoding['attention_mask'] - (4) 训练循环:
from torch.nn import functional as F labels = torch.tensor([1,0]) outputs = model(input_ids, attention_mask=attention_mask) loss = F.cross_entropy(outputs.logits, labels) loss.backward() optimizer.step()- 训练中关于步长的调整可以使用
Transformers:
from transformers import get_linear_schedule_with_warmup scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps, num_train_steps) loss.backward() optimizer.step() scheduler.step() - 训练中关于步长的调整可以使用
- 在Transformers中提供了
Trainer()方法, 我们强烈建议使用这样的方法去工作, 这将在本节的第三节提及;
- 冷冻编码器: Freezing the encoder;
- 可以将模型中参数的
requires_grad属性全部置False;for param in model.base_model.parameters(): param.requires_grad = False
TensorFlow2中的微调
- 直接上代码示例(因为笔者不是很关心TensorFlow实现, 太坑…):
from transformers import TFBertForSequenceClassification model = TFBertForSequenceClassification.from_pretrained('bert-base-uncased') from transformers import BertTokenizer, glue_convert_examples_to_features import tensorflow as tf import tensorflow_datasets as tfds tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') data = tfds.load('glue/mrpc') train_dataset = glue_convert_examples_to_features(data['train'], tokenizer, max_length=128, task='mrpc') train_dataset = train_dataset.shuffle(100).batch(32).repeat(2) optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5) loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True) model.compile(optimizer=optimizer, loss=loss) model.fit(train_dataset, epochs=2, steps_per_epoch=115) from transformers import BertForSequenceClassification model.save_pretrained('./my_mrpc_model/') pytorch_model = BertForSequenceClassification.from_pretrained('./my_mrpc_model/', from_tf=True)
训练器
- PyTorch版本的示例:
Trainer()方法:from transformers import BertForSequenceClassification, Trainer, TrainingArguments model = BertForSequenceClassification.from_pretrained("bert-large-uncased") training_args = TrainingArguments( output_dir='./results', # output directory num_train_epochs=3, # total # of training epochs per_device_train_batch_size=16, # batch size per device during training per_device_eval_batch_size=64, # batch size for evaluation warmup_steps=500, # number of warmup steps for learning rate scheduler weight_decay=0.01, # strength of weight decay logging_dir='./logs', # directory for storing logs ) trainer = Trainer( model=model, # the instantiated 🤗 Transformers model to be trained args=training_args, # training arguments, defined above train_dataset=train_dataset, # training dataset eval_dataset=test_dataset # evaluation dataset )
- TensorFlow版本的示例:
TFTrainer()方法:from transformers import TFBertForSequenceClassification, TFTrainer, TFTrainingArguments model = TFBertForSequenceClassification.from_pretrained("bert-large-uncased") training_args = TFTrainingArguments( output_dir='./results', # output directory num_train_epochs=3, # total # of training epochs per_device_train_batch_size=16, # batch size per device during training per_device_eval_batch_size=64, # batch size for evaluation warmup_steps=500, # number of warmup steps for learning rate scheduler weight_decay=0.01, # strength of weight decay logging_dir='./logs', # directory for storing logs ) trainer = TFTrainer( model=model, # the instantiated 🤗 Transformers model to be trained args=training_args, # training arguments, defined above train_dataset=tfds_train_dataset, # tensorflow_datasets training dataset eval_dataset=tfds_test_dataset # tensorflow_datasets evaluation dataset )
- sklearn库中计算评价指标:
from sklearn.metrics import accuracy_score, precision_recall_fscore_support def compute_metrics(pred): labels = pred.label_ids preds = pred.predictions.argmax(-1) precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='binary') acc = accuracy_score(labels, preds) return { 'accuracy': acc, 'f1': f1, 'precision': precision, 'recall': recall }
模型共享与上传
- 详见: model sharing
- 模型保存与调取:
save_pretrained()与from_pretrained()方法; - 模型共享: 使用
git上传到模型的指定仓库;
分词器汇总
详见: tokenizer summary
这部分内容在前面已经零星的提到了非常多, 即AutoTokenizer模块的使用;
多语言模型
- XLM模型: xlm
-
xlm-mlm-ende-1024: (Masked language modeling, English-German) -
xlm-mlm-enfr-1024: (Masked language modeling, English-French) -
xlm-mlm-enro-1024: (Masked language modeling, English-Romanian) -
xlm-mlm-xnli15-1024: (Masked language modeling, XNLI languages) -
xlm-mlm-tlm-xnli15-1024: (Masked language modeling + Translation, XNLI languages) -
xlm-clm-enfr-1024: (Causal language modeling, English-French) -
xlm-clm-ende-1024: (Causal language modeling, English-German) -
调用示例:
import torch from transformers import XLMTokenizer, XLMWithLMHeadModel tokenizer = XLMTokenizer.from_pretrained("xlm-clm-enfr-1024") model = XLMWithLMHeadModel.from_pretrained("xlm-clm-enfr-1024") print(tokenizer.lang2id) # {'en': 0, 'fr': 1} input_ids = torch.tensor([tokenizer.encode("Wikipedia was used to")]) # batch size of 1 language_id = tokenizer.lang2id['en'] # 0 langs = torch.tensor([language_id] * input_ids.shape[1]) # torch.tensor([0, 0, 0, ..., 0]) # We reshape it to be of size (batch_size, sequence_length) langs = langs.view(1, -1) # is now of shape [1, sequence_length] (we have a batch size of 1) outputs = model(input_ids, langs=langs) -
利用XLM的CLM的checkpoint进行文本生成的脚本: run_generation.py
- 不带语言嵌入的XLM模型:
xlm-mlm-17-1280: (Masked language modeling, 17 languages)xlm-mlm-100-1280: (Masked language modeling, 100 languages)
- BERT模型:
bert-base-multilingual-uncased: (Masked language modeling + Next sentence prediction, 102 languages)bert-base-multilingual-cased: (Masked language modeling + Next sentence prediction, 104 languages)
- XLM-RoBERTa: xlm-roberta
xlm-roberta-base: (Masked language modeling, 100 languages)xlm-roberta-large: (Masked language modeling, 100 languages)
第三部分: 高级指南
预训练模型:
- 链接中提供了所有收录模型的目录及简要介绍的列表, 不再赘述: pretrained models
样例:
- 链接中给了一些安装以及扩展的安装问题, 感觉不是很重要: examples
自定义数据集上的微调
详见: custom datasets
- 本节主要是一些使用预训练模型进行训练的样例, 区别与上一章同类章节的内容只是在数据集预处理上有所区别, 看懂之前的就够了, 本节是举了三种自定义数据集进行示例:
- (1) IMDb影评数据集上的序列分类;
- (2) W-NUT Emerging Entities中的token分类;
- (3) SQuAD 2.0上的问答系统模型;
Transformers的笔记本
详见: notebooks
主要是一些官方的jupyter notebook, 包括一些常见自然语言任务的模型微调模板, 文本生成任务, 划定模型的基线;
社区
详见: community
主要是一些论文与项目地址的汇总, 不再赘述;
转换TensorFlow模型
详见: converting tensorflow
主要是关于如何将一些在TensorFlow上训练得到的模型转换为PyTorch, 官方提供了一些转换代码和shell脚本可供使用;
第四部分: 研究
有兴趣的可以看一看, 笔者是力不能及了;
bertology
perplexity
benchmarks
第五部分: 主要类
Callbacks
Configuration*类
Logging
Models
Optimization
Model outputs
Pipelines
transformers.pipeline(task: str,
model: Optional = None,
config: Optional[Union[str, transformers.configuration_utils.PretrainedConfig]] = None,
tokenizer: Optional[Union[str, transformers.tokenization_utils.PreTrainedTokenizer]] = None,
framework: Optional[str] = None,
revision: Optional[str] = None,
use_fast: bool = True, **kwargs) → transformers.pipelines.base.Pipeline
- 参数说明:
task: 即管道适用的任务类型, 通过设置不同的task值将返回不同类型的管道对象;'feature-extraction': 返回FeatureExtractionPipeline;'sentiment-analysis': 返回TextClassificationPipeline;'ner': 返回TokenClassificationPipeline;'question-answering': 返回QuestionAnsweringPipeline;'fill-mask': 返回FillMaskPipeline;'summarization': 返回SummarizationPipeline;'translation_xx_to_yy': 返回TranslationPipeline;'text2text-generation': 返回Text2TextGenerationPipeline;'text-generation': 返回TextGenerationPipeline;'zero-shot-classification': 返回ZeroShotClassificationPipeline;'conversation': 返回ConversationalPipeline;
model: 即管道所使用的模型, 默认会从huggingface镜像中下载模型, 可以传入继承自PreTrainModel(PyTorch)或TFPreTrainModel(Tensorflow)的变量;config: 配置信息, 见transformers.PretrainedConfig
- 示例:
>>> from transformers import pipeline, AutoModelForTokenClassification, AutoTokenizer >>> # Sentiment analysis pipeline >>> pipeline('sentiment-analysis') >>> # Question answering pipeline, specifying the checkpoint identifier >>> pipeline('question-answering', model='distilbert-base-cased-distilled-squad', tokenizer='bert-base-cased') >>> # Named entity recognition pipeline, passing in a specific model and tokenizer >>> model = AutoModelForTokenClassification.from_pretrained("dbmdz/bert-large-cased-finetuned-conll03-english") >>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased") >>> pipeline('ner', model=model, tokenizer=tokenizer)
Processors
Tokenizer
Trainer
第六部分: 模型
第七部分: 帮助
杂记
关于transformers预训练模型的下载路径
- Win10系统中默认的下载路径为
C:\Users\lenovo\.cache\huggingface\transformers\, 可以通过设置环境变量PYTORCH_PRETRAINED_BERT_CACHE来改变下载路径, 详细可见E:\Anaconda3\Lib\site-packages\transformers\file_utils.py中的代码片段(line 195-197):
PYTORCH_PRETRAINED_BERT_CACHE = os.getenv("PYTORCH_PRETRAINED_BERT_CACHE", default_cache_path)
PYTORCH_TRANSFORMERS_CACHE = os.getenv("PYTORCH_TRANSFORMERS_CACHE", PYTORCH_PRETRAINED_BERT_CACHE)
TRANSFORMERS_CACHE = os.getenv("TRANSFORMERS_CACHE", PYTORCH_TRANSFORMERS_CACHE)

















 2560
2560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









