







一、utils代码分析
1.特征onehot码处理
def encode_onehot(labels):
#创建一个无序不重复的元素集
classes=set(labels)
#创建一个字典,将值c与一个onehot码对应(随机分配,此时还不是按照labels的顺序排列)
classes_dict={c:np.identity(len(classes))[i,:] for i,c in enumerate(classes)}
#map函数做映射,onehot编码和labels中的每一个元素按照labels中元素的顺序对应
labels_onehot=np.array(list(map(classes_dict.get,labels)),dtype=np.int32)
return labels_onehot为了让我自己看明白一点,把每行代码print了一下
labels=[1,2,3,7,0,0]
classes=set(labels)
print(classes)
print('******************************************')
classes_dict={c:np.identity(len(classes))[i,:] for i,c in enumerate(classes)}
print(classes_dict)
print('******************************************')
labels_onehot=np.array(list(map(classes_dict.get,labels)),dtype=np.int32)
print(labels_onehot)输出的结果如下
##classes##
{0, 1, 2, 3, 7}
##classes_dict##
{0: array([1., 0., 0., 0., 0.]), 1: array([0., 1., 0., 0., 0.]), 2: array([0., 0., 1., 0., 0.]), 3: array([0., 0., 0., 1., 0.]), 7: array([0., 0., 0., 0., 1.])}
##labels_onehot##
[[0 1 0 0 0]
[0 0 1 0 0]
[0 0 0 1 0]
[0 0 0 0 1]
[1 0 0 0 0]
[1 0 0 0 0]]
2.数据载入及处理函数
(1)
def load_data(path="../data/cora/", dataset="cora"):
"""Load citation network dataset (cora only for now)"""
print('Loading {} dataset...'.format(dataset))
###将文件中的内容读出
###np.genfromtxt()用于 从文本文件加载数据,并按照指定处理缺失值,dtype将类型强制转换
##idx_features_labels:论文编号_特征_类别标签
idx_features_labels = np.genfromtxt("{}{}.content".format(path, dataset),
dtype=np.dtype(str))
###以稀疏矩阵(csr格式压缩),将数据中的特征存储
##每行的第2列到倒数第2列表示features
features = sp.csr_matrix(idx_features_labels[:, 1:-1], dtype=np.float32)
##每行的最后一列表示labels
labels = encode_onehot(idx_features_labels[:, -1])(2)build graph(根据引用文件生成无向图)
# build graph
###提取每篇文章的编号
idx = np.array(idx_features_labels[:, 0], dtype=np.int32)
###对文章的编号构建词典
idx_map = {j: i for i, j in enumerate(idx)}
###读取cite(引用)文件
edges_unordered = np.genfromtxt("{}{}.cites".format(path, dataset),
dtype=np.int32)
edges = np.array(list(map(idx_map.get, edges_unordered.flatten())),
dtype=np.int32).reshape(edges_unordered.shape)
###稀疏矩阵,对应的行、列分别为边的两个点,得到一个有向图
adj = sp.coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])),
shape=(labels.shape[0], labels.shape[0]),
dtype=np.float32)
###np.ones(edges.shape[0]):生成长度为edges.shape[0],全为1的array
###(edges[ : ,0],edges[ : ,1]):第 i 行,第 j 列sp.coo_matrix函数的用法:
import scipy.sparse as sp
import numpy as np
row = np.array([0, 3, 1, 0])
col = np.array([0, 3, 1, 2])
data = np.array([4, 5, 7, 9])
B = sp.coo_matrix((data, (row, col)), shape=(4, 4)).toarray()
输出为:

(3)build symmetric adjacency matrix
计算转置矩阵。将有向图转成无向图
无向图的领接矩阵是对称的,因此需要将上面得到的矩阵转换为对称的矩阵,从而得到无向图的领接矩阵
'''
论文中采用的办法和下面两个语句是等价的,仅仅是为了产生对称的矩阵
adj_2 = adj + adj.T.multiply(adj.T > adj)
adj_3 = adj + adj.T
'''
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)
举个栗子:
adj=torch.Tensor([[1,1,0],[0,0,1],[0,1,0]])
print(adj.T>adj)
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)
print(adj)
###输出结果:
tensor([[False, False, False],
[ True, False, False],
[False, False, False]])
tensor([[1., 1., 0.],
[1., 0., 1.],
[0., 1., 0.]])
(4)归一化
features = normalize(features) # 对特征做了归一化的操作
adj = normalize(adj + sp.eye(adj.shape[0])) # 对A+I归一化(不懂为什么要与单位矩阵相加)(5)
###训练,验证,测试的样本
idx_train = range(140)
idx_val = range(200, 500)
idx_test = range(500, 1500)
###将numpy的数据转换成torch格式
features = torch.FloatTensor(np.array(features.todense()))
##labels: onehot编码,输出列索引(第几列为1就代表是哪种类别的文章)
##**********************************************************************
##*举个栗子: *
##*labels=np.array([[1,0,0,0],[0,0,1,0],[1,0,0,0],[0,0,1,0],[0,0,0,1]])*
##*print(np.where(labels)[1]) *
##*结果为[0 2 0 2 3],输出的是每行中值为1的列索引 *
##**********************************************************************
labels = torch.LongTensor(np.where(labels)[1])
adj = sparse_mx_to_torch_sparse_tensor(adj)
idx_train = torch.LongTensor(idx_train)
idx_val = torch.LongTensor(idx_val)
idx_test = torch.LongTensor(idx_test)
return adj, features, labels, idx_train, idx_val, idx_tes
np.where的用法:
a = np.arange(12).reshape(3,4)
print('a:', a)
print('np.where(a > 5):', np.where(a > 5))#输出行和列索引
print('a[np.where(a > 5)]:', a[np.where(a > 5)])#输出结果
print('np.where(a > 5)[0]:', np.where(a > 5)[0])#输出行索引
print('np.where(a > 5)[1]:', np.where(a > 5)[1])#输出列索引
print(a[np.where(a > 5)[0], np.where(a > 5)[1]])#输出结果
‘****************************************************************8’
#结果如下:
a: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
np.where(a > 5): (array([1, 1, 2, 2, 2, 2], dtype=int64), array([2, 3, 0, 1, 2, 3], dtype=int64))
a[np.where(a > 5)]: [ 6 7 8 9 10 11]
np.where(a > 5)[0]: [1 1 2 2 2 2]
np.where(a > 5)[1]: [2 3 0 1 2 3]
[ 6 7 8 9 10 11]
3.特征归一化
def normalize(mx):
"""Row-normalize sparse matrix(行规范化稀疏矩阵)"""
rowsum=np.array(mx.sum(1)) #每行相加的和
r_inv=np.power(rowsum,-1).flatten() #flatten():将所有的维度展开成1维
r_inv[np.isinf(r_inv)]=0. #isinf():判断是否为无穷大,是的话置为0
r_mat_inv=sp.diags(r_inv) #sp.diags():生成对角矩阵
mx=r_mat_inv.dot(mx) #r_mat_inv与mx矩阵相乘
##最后一步生成的结果中,每个元素即为xi/sum(x1+x2+...+xi+...+xn)
return mx4. 精度计算函数
def accuracy(output,labels):
#output.max(1):输出在第1维度上比较(二维向量的话即每行进行比较)出最大值
#output.max(1)[1]:输出output.max(1)所得最大值的索引
preds=output.max(1)[1]
correct=preds.eq(labels).double() #preds.eq(labels):判断preds与labels是否相等
correct=correct.sum()
return correct/len(labels)其中,关于max的用法,举个栗子:
output=torch.Tensor([[1,7,4],[9,3,8]])
preds1=output.max(0)[0] #输出每列最大值的值
preds2=output.max(0)[1] #输出每列最大值的索引
print('output.max(0)[0]=',preds1)
print('output.max(0)[1]=',preds2)
preds1=output.max(1)[0] #输出每行最大值的值
preds2=output.max(1)[1] #输出每行最大值的索引
print('output.max(1)[0]=',preds1)
print('output.max(1)[1]=',preds2)
***********************************************
*结果为: *
*output.max(0)[0]= tensor([9., 7., 8.]) *
*output.max(0)[1]= tensor([1, 0, 1]) *
*output.max(1)[0]= tensor([7., 9.]) *
*output.max(1)[1]= tensor([1, 0]) *
***********************************************
5.稀疏矩阵→稀疏张量
def sparse_mx_to_torch_sparse_tensor(sparse_mx):
"""Convert a scipy sparse matrix to a torch sparse tensor."""
sparse_mx=sparse_mx.tocoo().astype(np.float32)
#coo指的是稀疏矩阵,最普通的稀疏矩阵
#astype():类型转换
indices=torch.from_numpy(
np.vstack((sparse_mx.row,sparse_mx.col)).astype(np.int64))
#np.vstack:按行堆叠
values=torch.from_numpy(sparse_mx.data)
#torch.from_numpy:将numpy类型转换为torch类型
shape=torch.Size(sparse_mx.shape)
return torch.sparse.FloatTensor(indices,values.shape)
#torch.sparse.FloatTensor():构造稀疏矩阵
#indices:指定矩阵的哪个位置有元素
#values:指定矩阵indices特定位置的元素的值
#shape:指定矩阵的形状举个栗子:
(1)sparse_mx = sparse_mx.tocoo().astype(np.float32)
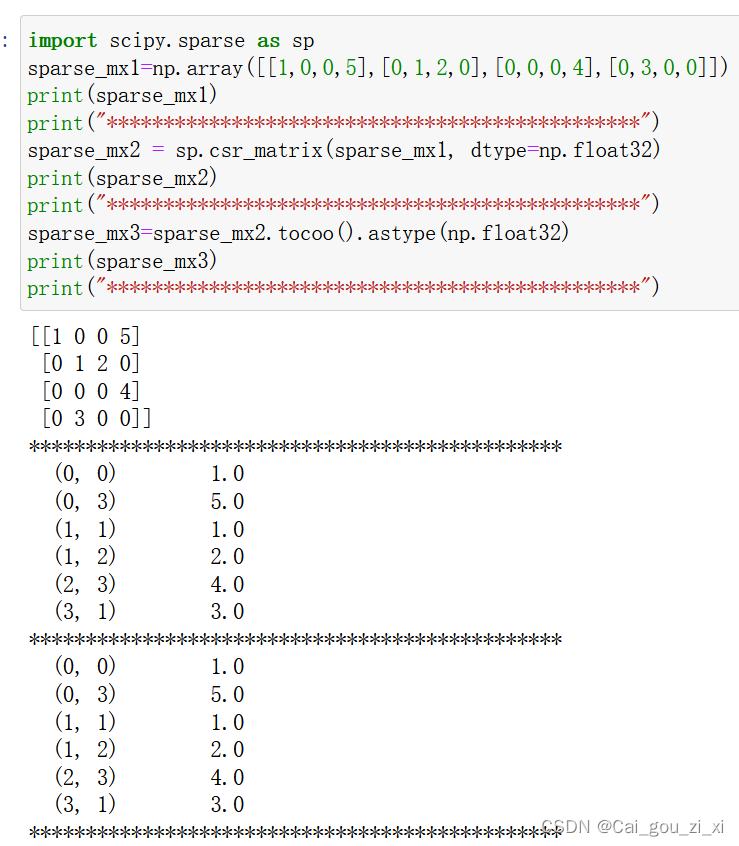
(2)indices = torch.from_numpy(
np.vstack((sparse_mx.row, sparse_mx.col)).astype(np.int64))

(3) values = torch.from_numpy(sparse_mx.data)

(4)shape = torch.Size(sparse_mx.shape)

(5) return torch.sparse.FloatTensor(indices, values, shape)

二、models代码分析
三、layers代码分析
1.属性定义
def __init__(self, in_features, out_features, bias=True):
super(GraphConvolution, self).__init__()
self.in_features = in_features
self.out_features = out_features
#torch.FloatTensor( , ):生成一个新的浮点型张量
self.weight = Parameter(torch.FloatTensor(in_features, out_features))
if bias:
self.bias = Parameter(torch.FloatTensor(out_features))
else:
self.register_parameter('bias', None)
#register_parameter()和parameter()的作用
#都是将一个不可训练的类型Tensor转换成可以训练的类型parameter
self.reset_parameters()(1)torch.FloatTensor( , )

2.参数初始化
def reset_parameters(self):
# size()函数主要是用来统计矩阵元素个数,或矩阵某一维上的元素个数的函数 size(1)为行
stdv = 1. / math.sqrt(self.weight.size(1))
#uniform():随机生成下一个实数,它在 [x, y) 范围内
self.weight.data.uniform_(-stdv, stdv)
if self.bias is not None:
self.bias.data.uniform_(-stdv, stdv)3.前馈计算
def forward(self, input, adj):
#torch.mm(a,b):最普通的矩阵相乘
support = torch.mm(input, self.weight)
#torch.spmm(a,b):我自己运行着也是最普通的矩阵相乘
#只支持 sparse 在前,dense 在后的矩阵乘法,
#两个sparse相乘或者dense在前的乘法不支持,当然两个dense矩阵相乘是支持的。
output = torch.spmm(adj, support)
if self.bias is not None:
return output + self.bias
else:
return output4.字符串表达
def __repr__(self):
return self.__class__.__name__ + '(' \
+ str(self.in_features) + '->' \
+ str(self.out_features) + ')'















 3706
3706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









