







准备在组会的时候讲这篇论文,详细地记录一下阅读过程及心得。
2023Findings,原文:
https://aclanthology.org/2023.findings-acl.303/
Abstract
1.目的:将 retrieval-based neural approaches 应用到 Aspect Sentiment Triplet Extraction (ASTE)中。
2.解决的问题:不同于之前检索semantic similar neighbors的工作,ASTE任务面临的挑战是,有着不同情感极性的semantic similar neighbors对解决ASTE任务起着消极的作用。
(这里感觉,作者不是通过我惯性思维里的通过ASTE任务的现存问题而引出本文,而是通过ASTE任务与现有的应用retrieval-based neural approaches的这些任务作对比,说明ASTE任务的难度在于它需要预测方面相关的情感极性。给我的感觉是,本文的目的在于,改进retrieval-based neural approaches使它更适用于ASTE任务,而不是为了解决ASTE任务提出了一种retrieval-based的方法)
3.提出的方法:Retrieval-based Aspect Sentiment Triplet Extraction via Label Interpolation (RLI)
retriever:给定一个aspect-opinion term pair,我们从 training corpus(训练语料库) 中,检索semantic相似的triplets,并将triplets的label information插到target pair的augmented representation中。
这个retriever在整个ASTE框架中被联合训练,有着相似semantics and sentiments的邻居可以在这种distant supervision的帮助下被召回。
此外,作者还为retriever设计了一种简单有效的预训练方法,该方法隐式编码标签相似度。
1 Introduction
现有ASTE方法介绍:略
ASTE现存问题:当句子中有不常见的aspect/opinion terms的时候,或者aspect 和 opinion terms相距甚远时,现有方法可能不足以理清元素间的复杂关系。
(承上启下)为了解决这些ASTE现存问题,我们应用retrieval-based models来解决ASTE,但是retrieval-based的方法应用到ASTE任务也存在着一些问题。
retrieval-based方法在解决ASTE任务时的问题:ASTE的目的是预测情感极性,并且情感极性是与aspect相关的。比如说,两个具有相同opinion term的triplet可能有着不同的情感极性。因此传统retrieval-based model的缺点:semantic相似但sentiment不同的neighbors可能是不可行的甚至适得其反。原文:the semantic similar neighbors with different sentiments may be infeasible even counterproductive.
为了克服这些挑战,作者提出了RLI,RLI可以开发neighbors的label information。
RLI:
收集来自training集的全部triplets,用这些triplets构建了一个知识库,并且检测所有候选的aspect-opinion pair。
对于每一个pair,我们从构建的库中检索semantic相似的triplets。将triplets(暂定是triplets)的label information插入到候选pair的augmented representation中,以此来预测最终的情感。
不同与只通过semantic相似性来检索neighbors的方法,作者联合训练了retriever和triplet提取器,这样就可以获取具有相似semanticss and sentiment的neighbors.
作者提出了一种简单有效的方法,来预训练提出的retriever,这个方法可以在联合训练前,利用pseudo-labeled data来对label information进行隐式编码。
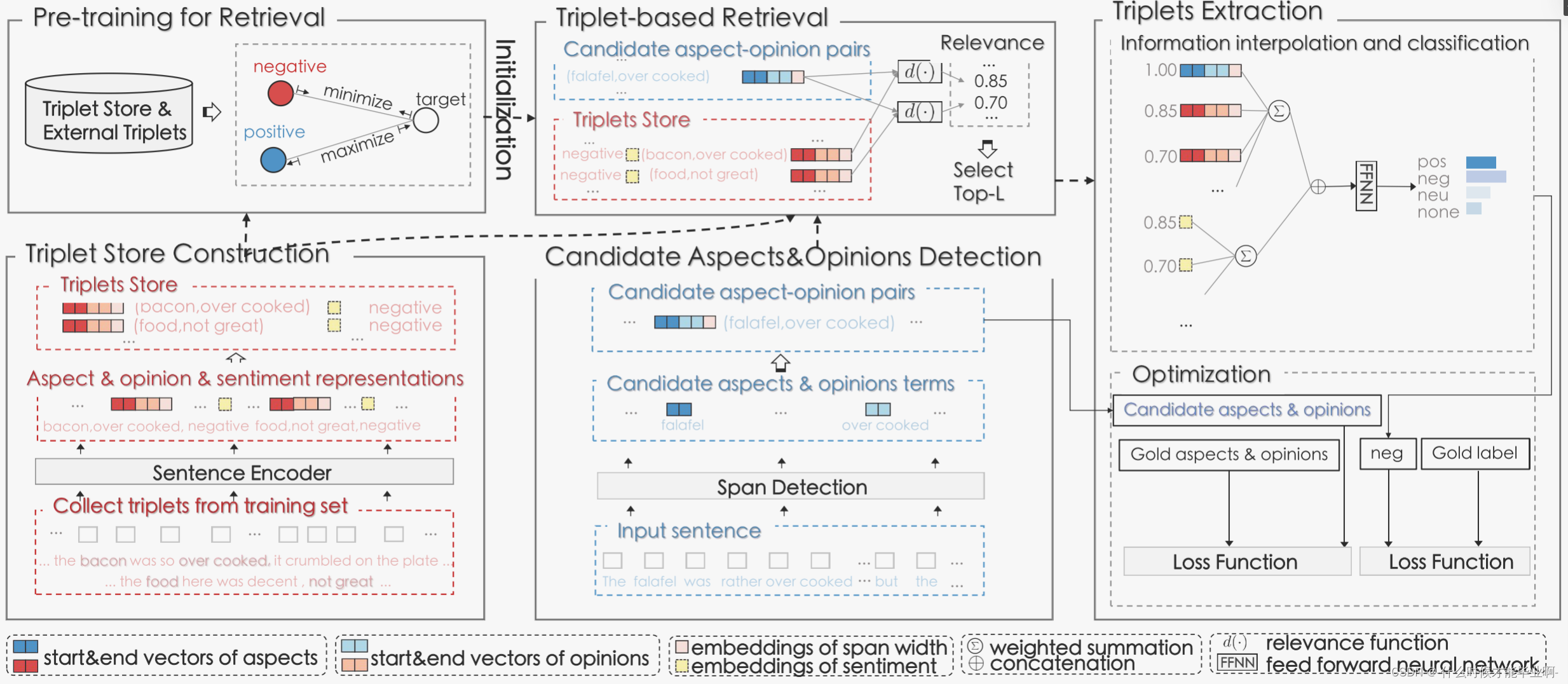
3 Methodology Overview
分为四个模块:
1.三元组存储结构:triplets store construction
2.检测候选的aspects和opinions:candidate aspects and opinions detection
3.基于三元组的检索:triplet-based retrieval (为每个候选的aspect-opinion pair检索neighbors)
4.三元组提取:triplet extraction (将第三部中检索到的triplets地representations和label information插入到候选的pair中,并预测pair的最终情感极性)
4 RLI Model
4.1 Triplets Store Construction
首先使用BERT,得到句子X的表示
aspect A和opinion O的表示如下:

其中的是一个与span的宽度相关的可训练的特征提取器。
之后,将上述的spans和一个可训练的sentiment embedding连起来,使用key-value对表示triplet
。

其中,是情感极性y的可学习转换函数。在公式(2)中,K代表的是representation information,V代表的是label information。
最终,triplet store由一组key-value对表示:
![]()
4.2 Candidate Aspects and Opinions Detection
给定句子X,首先提取所有可能的span,之后再使用classifier预测这个span S 是aspect, opinon或者是invalid span。
首先对于任意的span S,其representation
![]()
之后应用一个检测模型预测S的类型:aspect,opinion,invalid span。

其中g是一个前馈神经网络,[c]表示取类型c所对应的维数的概率。
理论上,句子X中应该有n(n+1)/2个span,但是对所有可能的span都进行预测太慢了,所以,作者限制了span的最大长度,以此来丢弃一些过长的span。
根据(3),我们选择了前K个aspect和opinion。随后,我们将这些候选的aspect和opinion组成aspect-opinion pair。假设用来表示每个候选的aspect-opinion pair,根据(2),这些aspect-opinion pair可以由
表示。
4.3 Triplet-based Retrieval
对于每个候选的aspect-opinion pair ,通过一个
和
之间的relevance function,在4.1中构建的triplet store中,检索出L个最相关的triplet。relevance function定义:
![]()
W是一个可训练的参数,,
分别表示的是
和
。
根据relevance function选择的与候选aspect-opinion pair 相关性最高的L组triplet,表示为:
![]()
![]()
将被用于下一阶段triplet的提取。
4.4 Triplet Extraction
目前我们已经得到的有:所有候选的aspect-opinon pair;通过检索获得的这些候选pair的相似triplet。
从4.3中,获得了与候选aspect-opinion pair 相关性最高的L组triplet,将这些triplet的representation information K和label information V,用来预测
的情感极性。

K代表的是的representation information,
和
分别代表
的representation information和label information,
d 定义的注意力模型,聚合每个candidate pair及其检索到的triplet的密集表示。
最终,使用一个神经模块来预测pair的最终情感极性。

F是一个前馈神经网络。
5 Training
5.1 Pre-training for Retrieval
使用外部无标记的数据来进行retriever的预训练,目的是让检索到的triplet能有相似的情感极性。
1. 在外部无标记的数据上,根据4.2来提取候选的aspect-opinion pairs。
2. 使用前馈神经网络预测这些aspect-opinion pairs是否有效,并确定他们的情感极性。
通过1,2两步,我们获得了从外部数据得到的triplets,其中y是用过神经网络获得的一个pseudo polarity。
针对每一个triplet,随机选择两个triplet
和
。
与
有着相同的情感极性,但是
与
有相反的情感极性。
通过对比学习,使有着相同情感极性的triplet之间的relevance score最大化,不同情感极性的triplet之间的relevance score最小化。

5.2 Joint Training
对于句子X,假设S(X)表示的是一个包括所有K个候选span的span pool。对于S(X)中的每个span S,真实的标签为{aspect, opinion, invalid}。对于没了aspect-opinion pair ![]() ,真实标签为{positive, negtive, neutral, none}。
,真实标签为{positive, negtive, neutral, none}。
: the candidate aspect terms and opinion terms detection
: triplet extraction model

![]()














 847
847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









