







从B站下载的字幕文件,转为观看视频软件可插入的形式。
参考链接:Python实现json字幕转换为srt字幕
思路从json提取字典列表–>转为dataframe–>秒转为时分秒–>写入文件。
import requests
subtitle_url = 'https://i0.hdslb.com/bfs/subtitle/e837950453ea3e4f6e81a5709449af173d2604dc.json' # 获取字幕的网址示例
subtitle_r = requests.get(subtitle_url)
sub_content= subtitle_r.json()['body'] # 提取弹幕内容的json
def s2hms(x): # 把秒转为时分秒
m, s = divmod(x, 60)
h, m = divmod(m, 60)
hms = "%02d:%02d:%s"%(h,m,str('%.3f'%s).zfill(6))
hms = hms.replace('.',',') # 把小数点改为逗号
return hms
with open('字幕文件.srt', 'w', encoding='utf-8') as f:
write_content = [str(n+1)+'\n' + s2hms(i['from'])+' --> '+s2hms(i['to'])+'\n' + i['content']+'\n\n' for n,i in enumerate(sub_content)] # 序号+开始-->结束+内容
f.writelines(write_content)
sub_content # 查看从B站爬的字幕json格式
>>>[{'from': 0,
'to': 3.39, # 表示3.39秒,我们需要将其转为 时:分:秒,秒的小数位 的格式
'location': 2,
'content': "之前你见过神经网络的大概图形 在本视频中\nYou've seen me draw a few pictures of your neural network in this video"},
{'from': 3.46,
'to': 6.02,
'location': 2,
'content': "我们将讨论 这些图形的具体含义\nwe'll talk about exactly what those pictures means"},
... ...
{'from': 8.77,
'to': 10.7,
'location': 2,
'content': '到底代表什么\nhave been drawing on represent'}]
打开字幕文件.srt可以看到
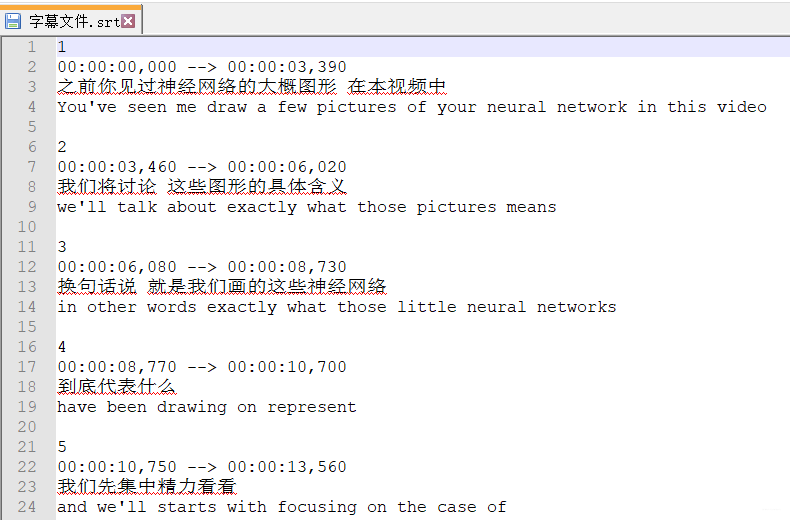
关于str字幕的格式有如下需要注意的小点:
- 将秒转为时分秒,需严格保持
两位数:两位数:两位数,三位数,后面是逗号,不是小数点。 - 一条完整的字幕结束后,需要空一行再写入下一条。
如果用的是QQ影音,则可以把字幕文件和视频放入同一个文件夹,在QQ影音设置自动导入当前文件夹下的同名字幕即可。

友情链接:
爬取B站多P视频
Github-下载B站视频软件

















 709
709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









