







介绍
最近在看一篇论文,基于CNN和RNN实现岩石描述的文本生成,里面用到LSTM和attention mechanism。有对这篇论文感兴趣的朋友请戳这里。
在恶补相关知识和查阅相关资料后,在此分享我对LSTM的理解。文章内容借鉴知乎大牛YJango的专栏。
梯度消失和梯度爆炸
如下图所示,循环神经网络用相同的方式来处理每个时刻的数据。我们希望循环神经网络可以将过去时刻发生的状态信息传递给当前时刻的计算中,但普通的RNN结构却难以传递相隔较远的信息。
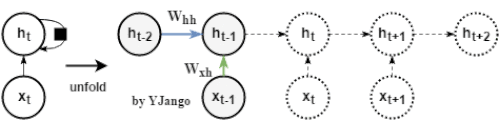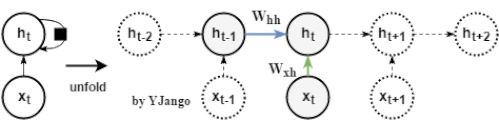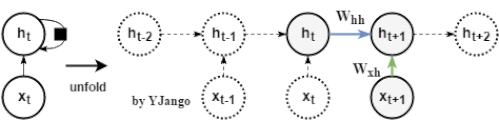
数学公式:
h t = ϕ ( W x h ⋅ x t + W h h ⋅ h t − 1 + b ) h_t= \phi(W_{xh} \cdot x_t + W_{hh} \cdot h_{t-1} + {b}) ht=ϕ(Wxh⋅xt+Whh⋅ht−1+b)
考虑:
-
若只看上图蓝色箭头线的、隐藏状态的传递过程,不考虑非线性部分,那么就会得到一个简化的式子:
h t = W h h ⋅ h t − 1 h_t= W_{hh} \cdot h_{t-1} ht=Whh⋅ht−1 (1) -
如果将起始时刻的隐藏状态信息h_0向第t时刻传递,会得到式子
h t = ( W h h ) t ⋅ h 0 h_t= (W_{hh})^t \cdot h_{0} ht=(Whh)t⋅h0(2) -
其中,W_{hh}会被乘以多次,若允许矩阵W_{hh}进行特征分解,则
h t = ( W h h ) t ⋅ h 0 h_t= (W_{hh})^t \cdot h_{0} ht=(Whh)t⋅h0(3) -
此时,式子(2)会变成
h t = Q ⋅ Λ t ⋅ Q T ⋅ h 0 h_t= Q \cdot \Lambda ^t \cdot Q^T \cdot h_{0} ht=Q⋅Λt⋅QT⋅h0(4)当特征值小于1时,不断相乘的结果是特征值的 t t t次方向 0 衰减; 当特征值大于1时,不断相乘的结果是特征值的 t t t次方向 ∞ \infty ∞扩增。 这时想要传递的 h 0 h_0 h0中的信息会被掩盖掉,无法传递到 h t h_t ht。
类比:
设想 y y = a t ∗ x yy=a^t*x yy=at∗x,如果 a a a等于0.1, x x x在被不断乘以0.1一百次后会变成多小?如果 a a a等于5, x x x在被不断乘以5一百次后会变得多大?若想要x所包含的信息既不消失,又不爆炸,就需要尽可能的将 a a a的值保持在1。
long short Term Memory(LSTM)
上面的现象可能并不意味着无法学习,但是即便可以,也会非常非常的慢。为了有效的利用梯度下降法学习,我们希望使不断相乘的梯度的积(the product of derivatives)保持在接近1的数值。
一种实现方式是建立线性自连接单元(linear self-connections)和在自连接部分数值接近1的权重,叫做leaky units。但Leaky units的线性自连接权重是手动设置或设为参数,而目前最有效的方式gated RNNs是通过gates的调控,允许线性自连接的权重在每一步都可以自我变化调节。LSTM就是gated RNNs中的一个实现。
关于门(gate)
理解Gated RNNs的第一步就是明白gate到底起到什么作用。
-
物理意义
输入:gate的输入是控制依据;
输出:gate的输出是值域为(0,1)的数值,表示该如何调节其他数据的数级的控制方式。 -
使用
gate所产生的输出会用于控制其他数据的数级,相当于过滤器的作用。例如:当用gate来控制向量 [ 20 5 7 8 ] \left[\begin{matrix}20 & 5& 7 & 8 \\\end{matrix}\right] [20578],若gate的输出为 [ 0.1 0.2 0.9 0.5 ] \left[\begin{matrix}0.1 & 0.2& 0.9 & 0.5 \\\end{matrix}\right] [0.10.20.90.5]时,原来的向量就会被对应元素相乘(element-wise)后变成:
[ 20 5 7 8 ] ⊙ [ 0.1 0.2 0.9 0.5 ] = [ 20 ∗ 0.1 5 ∗ 0.2 7 ∗ 0.9 8 ∗ 0.5 ] = [ 2 1 6.3 4 ] \left[\begin{matrix}20 & 5& 7 & 8 \\\end{matrix}\right]\odot \left[\begin{matrix}0.1 & 0.2& 0.9 & 0.5 \\\end{matrix}\right]=\left[\begin{matrix}20*0.1 & 5*0.2& 7*0.9 & 8*0.5 \\\end{matrix}\right]=\left[\begin{matrix}2 & 1& 6.3 & 4 \\\end{matrix}\right] [20578]⊙[0.10.20.90.5]=[20∗0.15∗0.27∗0.98∗0.5]=[216.34] -
控制依据
明白了gate的输出后,剩下要确定以什么信息为控制依据,即什么是gate的输入。即便是LSTM也有很多个变种。一个变种方式是调控门的输入。例如下面两种gate:
(1) g = s i g m o i d ( W x g ⋅ x t + W h g ⋅ h t − 1 + b ) g= sigmoid(W_{xg} \cdot x_t + W_{hg} \cdot h_{t-1} + {b}) g=sigmoid(Wxg⋅xt+Whg⋅ht−1+b):
此时gate的输入有当前的输入 x t x_t xt和上一时刻的隐藏状态 h t − 1 h_{t-1} ht−1, gate是将这两个信息流作为控制依据而产生输出的。
(2) g = s i g m o i d ( W x g ⋅ x t + W h g ⋅ h t − 1 + W c g ⋅ c t − 1 + b ) g= sigmoid(W_{xg} \cdot x_t + W_{hg} \cdot h_{t-1} +W_{cg} \cdot c_{t-1}+ {b}) g=sigmoid(Wxg⋅xt+Whg⋅ht−1+Wcg⋅ct−1+b):
这种方式的LSTM叫做peephole connections。此时gate的输入有当前的输入 x t x_t xt和上一时刻的隐藏状态 h t − 1 h_{t-1} ht−1,以及上一时刻的cell状态 c t − 1 c_{t-1} ct−1, 表示gate是将这三个信息流作为控制依据而产生输出的。
关于LSTM
给出LSTM中的关键数学公式如下:

-
gates
在LSTM中,网络首先构建了3个gates来控制信息的流通量,有了这3个gates后,接下来要考虑的就是如何用它们装备在普通的RNN上来控制信息流。依据3个gates所用与控制信息流通的地点,它们被分为:
(1)更新门 i t i_t it:控制有多少信息可以流入memory cell( c t c_t ct)。
(2)遗忘门 f t f_t ft:控制有多少上一时刻的memory cell中的信息可以累积到当前时刻的memory cell中。
(3)输出门 o t o_t ot:控制有多少当前时刻的memory cell中的信息可以流入当前隐藏状态 h t h_t ht中。可能你已经注意到gates在上面计算公式中的构成式子是一样的,但是实际上3个gates式子 W W W和 b b b的下角标并不相同。它们有各自的物理意义,在网络学习过程中会产生不同的权重。
注意:gates并不提供额外信息,gates只是起到限制信息的量的作用。因为gates起到的是过滤器作用,所以所用的激活函数是sigmoid而不是tanh。 -
信息流
信息流的来源有三处:
(1)当前的输入 x t x_t xt,
(2)上一时刻的隐藏状态 h t − 1 h_{t-1} ht−1,
(3)上一时刻的cell状态 c t − 1 c_{t-1} ct−1。其中 c t − 1 c_{t-1} ct−1是额外制造出来、可线性自连接的单元。真正的信息流来源可以说只有当前的输入 x t x_t xt,上一时刻的隐藏状态 h t − 1 h_{t-1} ht−1两处。从上面的数学公式可以看出三个gates的控制依据,以及数据的更新都是来源于这两处。
-
历史信息积累
在分析了gates和信息流后,我们来看看LSTM是如何累计历史消息的。由公式: c t = f t ⊙ c t − 1 + i t ⊙ t a n h ( W x c x t + W h c h t − 1 + b c ) c _t = f_t \odot c_{t - 1} + i_t \odot tanh(W_{xc} x_t + W_{hc}h_{t-1} + b_c) ct=ft⊙ct−1+it⊙tanh(Wxcxt+Whcht−1+bc)
可以看出历史信息的累积是并不是靠隐藏状态h自身,而是依靠memory cell这个自连接来累积。在累积时,靠遗忘门来限制上一时刻的memory cell的信息,即 c t = f t ⊙ c t − 1 c _t = f_t \odot c_{t - 1} ct=ft⊙ct−1。 靠输入门来限制新信息,即 i t ⊙ t a n h ( W x c x t + W h c h t − 1 + b c ) i_t \odot tanh(W_{xc} x_t + W_{hc}h_{t-1} + b_c) it⊙tanh(Wxcxt+Whcht−1+bc)。其中 n e w = t a n h ( W x c x t + W h c h t − 1 + b c ) new=tanh(W_{xc} x_t + W_{hc}h_{t-1} + b_c) new=tanh(Wxcxt+Whcht−1+bc)是本次要累积的信息来源。
-
当前隐藏状态的计算
如此大费周章的最终仍然同普通RNN一样要计算当前隐藏状态。由公式: h t = o t ⊙ t a n h ( c t ) h_t = o_t \odot tanh(c_t) ht=ot⊙tanh(ct)
可以看出当前隐藏状态 h t h_t ht是从 c t c_t ct计算得来的,因为 c t c_t ct是以线性的方式自我更新的,所以先将其加入带有非线性功能的 t a n h ( c t ) tanh(c_t) tanh(ct)。 随后再靠输出门 o t o_t ot的过滤来得到当前隐藏状态 h t h_t ht。
普通RNN和LSTM的比较
公式
(1)普通RNN:
h
t
=
t
a
n
h
(
W
x
h
⋅
x
t
+
W
h
h
⋅
h
t
−
1
+
b
)
h_t= tanh(W_{xh} \cdot x_t + W_{hh} \cdot h_{t-1} + {b})
ht=tanh(Wxh⋅xt+Whh⋅ht−1+b)
(2) LSTM:
h
t
=
o
t
⊙
t
a
n
h
(
f
t
⊙
c
t
−
1
+
i
t
⊙
t
a
n
h
(
W
x
c
x
t
+
W
h
c
h
t
−
1
+
b
c
)
)
h _t = o_t \odot tanh(f_t \odot c_{t - 1} + i_t \odot tanh(W_{xc} x_t + W_{hc}h_{t-1} + b_c))
ht=ot⊙tanh(ft⊙ct−1+it⊙tanh(Wxcxt+Whcht−1+bc))
(3)比较:二者的信息来源都是
t
a
n
h
(
W
x
h
⋅
x
t
+
W
h
h
⋅
h
t
−
1
+
b
)
tanh(W_{xh} \cdot x_t + W_{hh} \cdot h_{t-1} + {b})
tanh(Wxh⋅xt+Whh⋅ht−1+b), 不同的是LSTM靠3个gates将信息的积累建立在线性自连接的权重接近1memory cell之上,并靠其作为中间物来计算当前
h
t
h_t
ht 。
示图–图片来自Understanding LSTM,强烈建议一并阅读。
-
普通RNN:
-
LSTM:加号圆圈表示线性相加,乘号圆圈表示用gate来过滤信息。
-
LSTM详解
LSTM的关键是细胞状态 C C C,一条水平线贯穿于图形的上方,这条线上只有些少量的线性操作,信息在上面流传很容易保持。
第一层是个忘记层,决定细胞状态中丢弃什么信息。把 h t − 1 ht−1 ht−1和 x t xt xt拼接起来,传给一个 s i g m o i d sigmoid sigmoid函数,该函数输出0到1之间的值,这个值乘到细胞状态 C t − 1 Ct−1 Ct−1上去。sigmoid函数的输出值直接决定了状态信息保留多少。比如当我们要预测下一个词是什么时,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。
上一步的细胞状态 C t − 1 Ct−1 Ct−1已经被忘记了一部分,接下来本步应该把哪些信息新加到细胞状态中呢?
这里又包含2层:一个 t a n h tanh tanh层用来产生更新值的候选项 C t C~t C t, t a n h tanh tanh的输出在[-1,1]上,说明细胞状态在某些维度上需要加强,在某些维度上需要减弱;还有一个 s i g m o i d sigmoid sigmoid层(输入门层),它的输出值要乘到 t a n h tanh tanh层的输出上,起到一个缩放的作用,极端情况下 s i g m o i d sigmoid sigmoid输出0说明相应维度上的细胞状态不需要更新。在那个预测下一个词的例子中,我们希望增加新的主语的性别到细胞状态中,来替代旧的需要忘记的主语。
现在可以让旧的细胞状态 C t − 1 Ct−1 Ct−1与 f t ft ft(f是forget忘记门的意思)相乘来丢弃一部分信息,然后再加个需要更新的部分 i t ∗ C t it∗C~t it∗C t(i是input输入门的意思),这就生成了新的细胞状态 C t Ct Ct。
最后该决定输出什么了。输出值跟细胞状态有关,把 C t Ct Ct输给一个 t a n h tanh tanh函数得到输出值的候选项。候选项中的哪些部分最终会被输出由一个 s i g m o i d sigmoid sigmoid层来决定。在那个预测下一个词的例子中,如果细胞状态告诉我们当前代词是第三人称,那我们就可以预测下一词可能是一个第三人称的动词。






















 1440
1440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









