




 本文深入探讨了LSTM(长短期记忆网络)如何解决基本RNN(循环神经网络)在处理长期依赖问题时遇到的梯度消失难题。通过引入遗忘门、输入门和输出门机制,LSTM能够有效地控制信息的流动,从而在序列预测任务中取得更佳效果。
本文深入探讨了LSTM(长短期记忆网络)如何解决基本RNN(循环神经网络)在处理长期依赖问题时遇到的梯度消失难题。通过引入遗忘门、输入门和输出门机制,LSTM能够有效地控制信息的流动,从而在序列预测任务中取得更佳效果。
LSTM(Long Short-Term Memory)
前面的两篇博客介绍了基本的循环神经网络RNN(recurrent neural network):
但是基本的RNN(之所以强调是基本的RNN,是因为LSTM本质上也是一种RNN,下面在说RNN就代指基本的RNN)也存在一些缺点,举个例子,比如我们有个句子生成的任务,有下面两句话(摘自ng deep learning课《sequence model》):
1、The cat, which already ate …, was full.
2、The cats, which already ate …, were full.
假如我们到动词部分,我们要根据前面的cat是单数还是复数来生成对应的was还是were,但是遗憾的是,基本的RNN是无法捕获这种长期依赖的,原因就在一旦需要长期依赖,RNN就会产生梯度消失。关于RNN为什么会梯度消失,这一点和深度网络中梯度消失原因是一样的,在博客RNN(recurrent neural network)(一)——基础知识里也解释过了。知乎上有篇文章从数学公式上解释了RNN梯度消失和爆炸的原理,可参考文章:RNN梯度消失和爆炸的原因。总结来看基本的RNN的缺点是:
无法处理长期依赖的问题(原因在于 梯度消失)
因此,LSTM被提出以解决这个问题。有一点需要注意的是:LSTM只能极大的缓解RNN的梯度消失,但不能从根本上解决,所幸的是大多数的任务场景下实验表明,LSTM都能够取得很好的结果。那么LSTM究竟是如何缓解梯度消失的呢?这里我们先把这个问题留在这,等我们介绍完LSTM的原理,再来回头解答这个问题,这样会比较清楚。
一、LSTM的结构
先来看看单个LSTM单元的结构图,以及处理序列展开后的LSTM结构图,这样大家会有一个直观的认识。
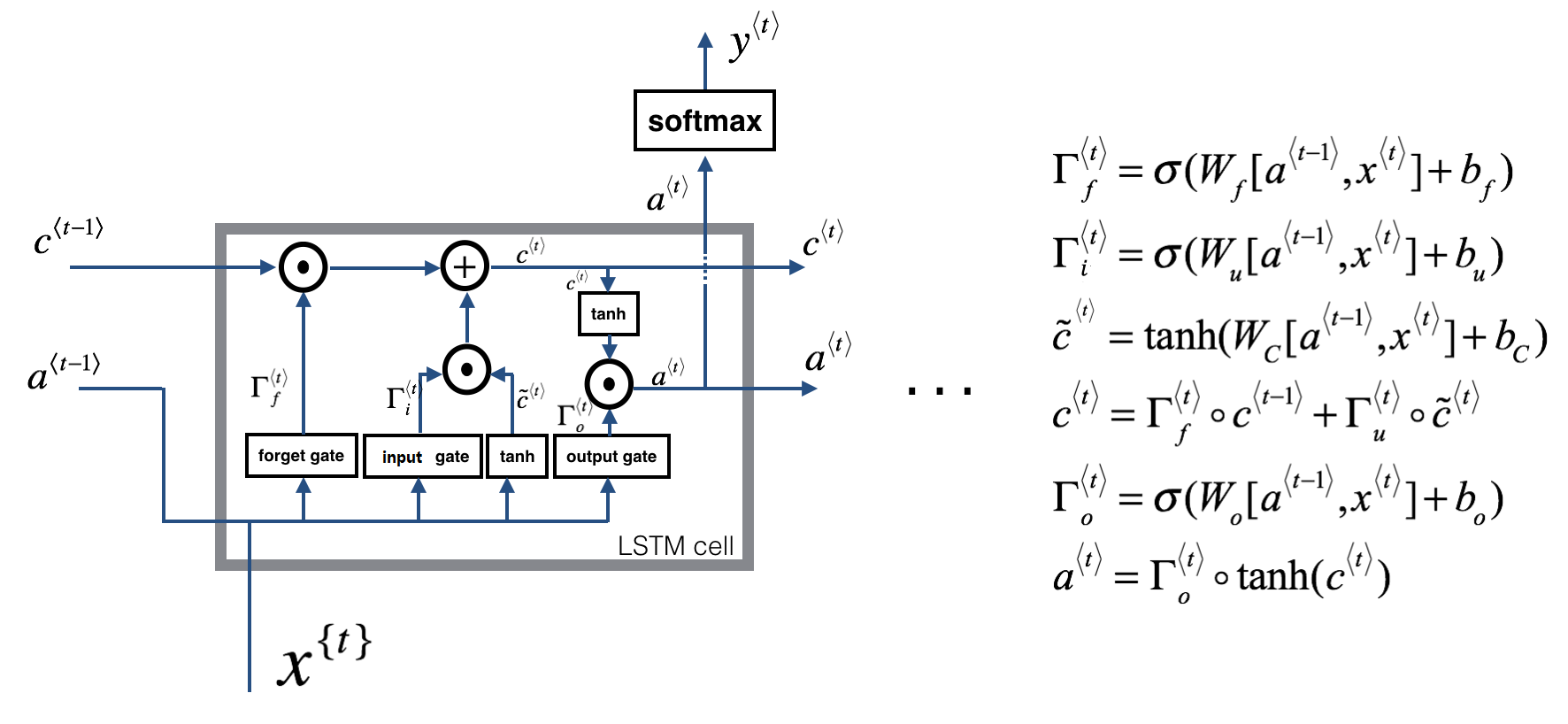
其中 Γ f \Gamma _{f} Γf表示遗忘门, Γ i \Gamma _{i} Γi表示输入门, Γ o \Gamma _{o} Γo表示输出门。其中,个人认为最重要的就是遗忘门。那么这几个门分别起到了什么作用?我们来看下:
-
forget gate(遗忘门):举个例子来解释下遗忘门的作用(参考ng deep learning课):
lets assume we are reading words in a piece of text, and want use an LSTM to keep track of grammatical structures, such as whether the subject is singular or plural. If the subject changes from a singular word to a plural word, we need to find a way to get rid of our previously stored memory value of the singular/plural state.
遗忘门的公式为 Γ f < t > = σ ( W f [ a < t − 1 > , x < t > ] + b f ) \Gamma_{f}^{<t>} = \sigma (W_{f}[a^{<t-1>},x^{<t>}] + b_f) Γf<t>=σ(Wf[a<t−1>,x<t>]+bf), σ \sigma σ为sigmoid函数,因此 Γ f \Gamma _{f} Γf的值在0到1之间,也就是说遗忘门通过看上一个隐藏状态( a < t − 1 > a^{<t-1>} a<t−1>)和当前的输入( x < t > x^{<t>} x<t>)来得到一个值( Γ f \Gamma _{f} Γf),然后用 Γ f \Gamma _{f} Γf去点乘 C < t − 1 > C^{<t-1>} C<t−1>(上一个memory cell)去决定上一个memory cell的信息是否保留,0表示丢弃,1表示保留。 -
input gate(输入门):这个有的也叫update gate。输入门的作用是为了更新cell state的时候,来决定哪些值需要被更新。
-
output gate(输出门):决定cell state里哪些值应该被输出(即下一个cell state的值)。
再上一张更加清晰地LSTM cell图,来自斯坦福的CS224D:
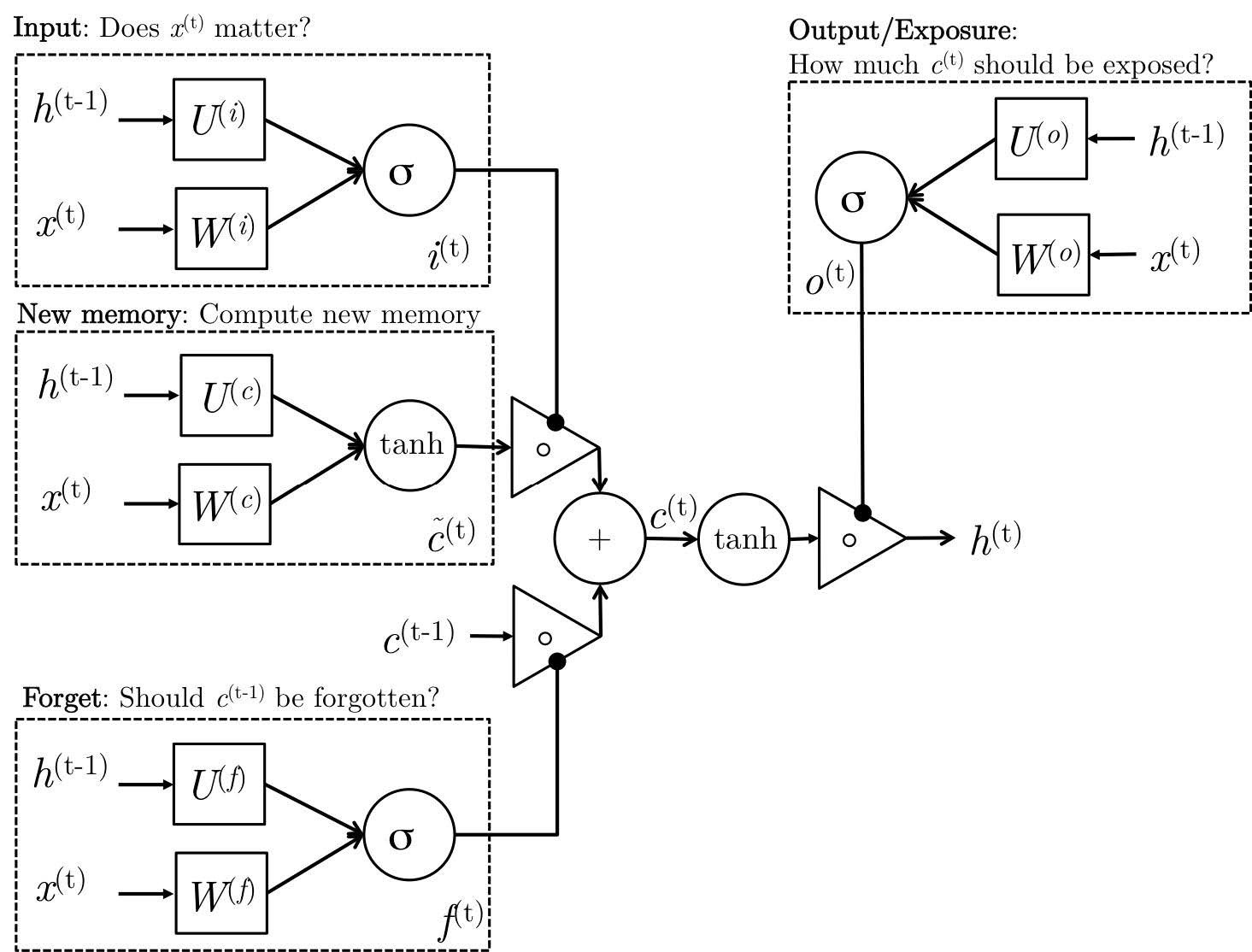
LSTM展开图如下所示:

二、LSTM的计算流程
关于LSTM的计算过程,博客 Understanding LSTM Networks中给出了详细了过程,建议大家认真看一下。我这里只简要的写一下流程(参考了上面的博客):
1、首先计算得到
Γ
f
<
t
>
=
σ
(
W
f
[
a
<
t
−
1
>
,
x
<
t
>
]
+
b
f
)
\Gamma_{f}^{<t>} = \sigma (W_{f}[a^{<t-1>},x^{<t>}] + b_f)
Γf<t>=σ(Wf[a<t−1>,x<t>]+bf)
2、计算
Γ
i
<
t
>
=
σ
(
W
i
[
a
<
t
−
1
>
,
x
<
t
>
]
+
b
i
)
\Gamma_{i}^{<t>} = \sigma (W_{i}[a^{<t-1>},x^{<t>}] + b_i)
Γi<t>=σ(Wi[a<t−1>,x<t>]+bi) 和
C
~
<
t
>
=
tanh
(
W
c
[
a
<
t
−
1
>
,
x
<
t
>
]
+
b
c
)
\widetilde{C}^{<t>} = \tanh (W_{c}[a^{<t-1>},x^{<t>}] + b_c)
C
<t>=tanh(Wc[a<t−1>,x<t>]+bc)
3、得到新的cell state:
C
<
t
>
=
Γ
f
<
t
>
⊙
C
<
t
−
1
>
+
Γ
i
<
t
>
⊙
C
~
<
t
>
C^{<t>} = \Gamma_{f}^{<t>}\odot C^{<t-1>} + \Gamma_{i}^{<t>}\odot \widetilde{C}^{<t>}
C<t>=Γf<t>⊙C<t−1>+Γi<t>⊙C
<t>,其中
Γ
f
<
t
>
⊙
C
<
t
−
1
>
\Gamma_{f}^{<t>}\odot C^{<t-1>}
Γf<t>⊙C<t−1>遗忘门决定上一个memory cell里有多少信息被保留下来,
Γ
i
<
t
>
⊙
C
~
<
t
>
\Gamma_{i}^{<t>}\odot \widetilde{C}^{<t>}
Γi<t>⊙C
<t>表示哪些新的信息被添加到当前的memory cell里。
4、计算
Γ
o
<
t
>
=
σ
(
W
o
[
a
<
t
−
1
>
,
x
<
t
>
]
+
b
o
)
\Gamma_{o}^{<t>} = \sigma (W_{o}[a^{<t-1>},x^{<t>}] + b_o)
Γo<t>=σ(Wo[a<t−1>,x<t>]+bo)
5、决定当前memory cell中哪些信息被输出:
a
<
t
>
=
Γ
o
<
t
>
⊙
t
a
n
h
(
c
<
t
>
)
a^{<t>} = \Gamma_{o}^{<t>}\odot tanh(c^{<t>})
a<t>=Γo<t>⊙tanh(c<t>)
关于LSTM的简单介绍到这就介绍完了,现在回过头去回答上面提出的问题:“LSTM是如何缓解梯度消失的?”
RNN产生梯度消失的根本原因在于连乘导致(梯度小于1,将->0,大于1,将->无穷,梯度爆炸),这点可以从bp的公式推导得到,这里不就推导了,博客漫谈LSTM系列的梯度问题做了推导,可以参考这一篇。而LSTM的魅力在于把连乘变成了相加,公式推导同样参考上面的文章。这里从上面的文章中摘取最重要的一部分:

下面是一些个人认为对理解LSTM比较好的文章博客,建议大家仔细看一看:
[1]: Understanding LSTM Networks
[2]: 漫谈LSTM系列的梯度问题
[3]: http://cs224d.stanford.edu/lecture_notes/notes4.pdf

















 1028
1028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









