







实验二:搜索算法
-
实验目的
1、掌握搜索算法的基本设计思想与方法,
2、掌握 A*算法的设计思想与方法,
3、熟练使用高级编程语言实现搜索算法,
4、利用实验测试给出的搜索算法的正确性。 -
实验学时
4学时。 -
实验问题
寻路问题。以图1为例,输入一个方格表示的地图,要求用A*算法找到并输出从起点(在方格中标示字母S)到终点(在方格中标示字母T)的代价最小
的路径。有如下条件及要求:
(1)每一步都落在方格中,而不是横竖线的交叉点。
(2)灰色格子表示障碍,无法通行。
(3)在每个格子处,若无障碍,下一步可以达到八个相邻的格子,并且只可以到达无障碍的相邻格子。其中,向上、下、左、右四个方向移动的代价为1,向四个斜角方向移动的代价为√2。
(4)在一些特殊格子上行走要花费额外的地形代价。比如,黄色格子代表沙漠,经过它的代价为4;蓝色格子代表溪流,经过它的代价为2;白色格子为普通地形,经过它的代价为0。
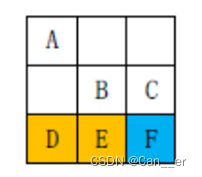
(5)经过一条路径总的代价为移动代价+地形代价。其中移动代价是路径上所做的所有移动的代价的总和;地形代价为路径上除起点外所有格子的地形代价的总和。比如,在下图的示例中,路径 A→B→C 的代价为√2+1(移动)+0(地形),而路径 D→E→F 的代价为2(移动)+6(地形)。
-
实验步骤
4.1 实现单向与双向的 A搜索算法
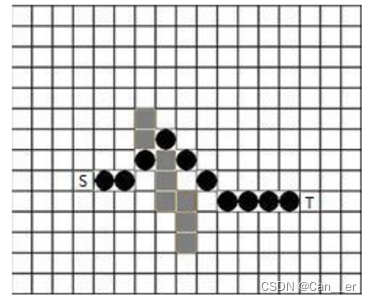
以下图为样例,实现单向和双向 A算法并测试输出。输出的路径应该与图2-1 中以圆点标示的路径一致,或者略有不同但是有一样的代价。规则和条件如第3节所述。
双向A算法应当从S点和T点同时进行A搜索。
首先进行地图的构造,使用-1表示不可达,4表示沙漠,2表示河流,如地图1的构造为:def get_Map1(): Map = np.zeros((14, 17)) # 不可达 Map[5][6] = Map[6][6] = Map[7][7] = Map[8][7] = Map[9][7] = Map[9][8] = Map[10][8] = Map[11][8] = -1 # 开始和结束 start = point(11, 4) end = point(2, 13) return Map, start, end其中,定义point表示点的行和列,其实例对象表示地图中的一个位置。然后node 类用于表示 A* 算法中的节点,包含了当前节点的位置 (row 和 col)、父节点 (parent)、代价值 (G)、启发值 (H)、总代价值 (F),以及一个标志 (reverse) 用于表示是否是反向遍历中的结点。在节点初始化时,计算 G、H 和 F 的值,其中 G 表示从起点到当前节点的实际代价,H 表示当前节点到目标节点的启发值,F 是 G 和 H 的和。其中,重写了__lt__ 方法定义了节点之间的比较规则,以便在使用堆的数据结构时能够按照总代价值进行排序。实现代码如下所示:
class node(object): def __init__(self, parent, point: point, topography: int, end: point, reverse: bool): self.row, self.col = point.row, point.col self.parent = parent self.reverse = reverse self.G = 0 self.H = 0
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2290
2290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









