







为什么引入Numpy?
python中的list列表也可以非常灵活的处理多个元素的操作,但效率非常低下,原因在于所有的元素的数据类型相同,数据地址连续,批量操作数组元素时速更快。
Numpy底层代码使用C语言编写,内置并行计算功能,运行速度高于Python代码
Numpy
标准的 Python 发行版不会与 NumPy 模块捆绑在一起。 一个轻量级的替代方法是使用流行的 Python 包安装程序 pip 来安装 NumPy。
pip install numpy
1.NumPy - Ndarray 对象
示例1
import numpy as np
a = np.array([1,2,3])
print a输出如下:
[1 2 3]示例2
# 多于一个维度
import numpy as np
a = np.array([[1, 2], [3, 4]])
print (a)输出结果如下:
[[1 2]
[3 4]]示例3
# 最小维度
import numpy as np
a = np.array([1, 2, 3, 4, 5], ndmin = 2)
print (a)输出如下:
[[1 2 3 4 5]]示例4
# dtype 参数
import numpy as np
a = np.array([1, 2, 3], dtype = complex)
print (a)输出如下:
[1.+0.j 2.+0.j 3.+0.j]2.NumPy 数据类型
| 名称 | 描述 |
|---|---|
| bool_ | 布尔型数据类型(True 或者 False) |
| int_ | 默认的整数类型(类似于 C 语言中的 long,int32 或 int64) |
| intc | 与 C 的 int 类型一样,一般是 int32 或 int 64 |
| intp | 用于索引的整数类型(类似于 C 的 ssize_t,一般情况下仍然是 int32 或 int64) |
| int8 | 字节(-128 to 127) |
| int16 | 整数(-32768 to 32767) |
| int32 | 整数(-2147483648 to 2147483647) |
| int64 | 整数(-9223372036854775808 to 9223372036854775807) |
| uint8 | 无符号整数(0 to 255) |
| uint16 | 无符号整数(0 to 65535) |
| uint32 | 无符号整数(0 to 4294967295) |
| uint64 | 无符号整数(0 to 18446744073709551615) |
| float_ | float64 类型的简写 |
| float16 | 半精度浮点数,包括:1 个符号位,5 个指数位,10 个尾数位 |
| float32 | 单精度浮点数,包括:1 个符号位,8 个指数位,23 个尾数位 |
| float64 | 双精度浮点数,包括:1 个符号位,11 个指数位,52 个尾数位 |
| complex_ | complex128 类型的简写,即 128 位复数 |
| complex64 | 复数,表示双 32 位浮点数(实数部分和虚数部分) |
| complex128 | 复数,表示双 64 位浮点数(实数部分和虚数部分) |
实例 1
import numpy as np # 使用标量类型
dt = np.dtype(np.int32)
print(dt)
输出结果为:
int32
输出结果:
int323.NumPy 数组属性
ndarray.shape
该数组属性返回一个包含数组维度的元组,可用于调整数组大小
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
print(a.shape)
=>>>(2,3)



4.NumPy 创建数组
import numpy as np
x= np.empty([3,2], dtype = int)
print(x)
===>>[[16461 1646131]
[56456 1561641]
[16584 4651315]]np.empty([3 , 2], dtype = float,int )
numpy.zeros创建指定大小的数组,数组元素以0来填充
numpy.zeros(shape, dtype = float, order = "C")import numpy as np
x=np.zeros(5)
print(x)
==>>[0. 0. 0. 0. 0.] (默认浮点数)
y = np.zeros((5), dtype = int)
print(y)
===>>>[0 0 0 0 0]
numpy.ones(shape, dtype = None,order="C")

x=np.ones(5)
print(x)
===》》》[1 1 1 1 1]
x = np.ones([2, 2], dtype = int)
===》》》[[1 1]
[1 1]]
numpy.zeros_like(a, dtype=None, order = "K", subok=True, shape=None)

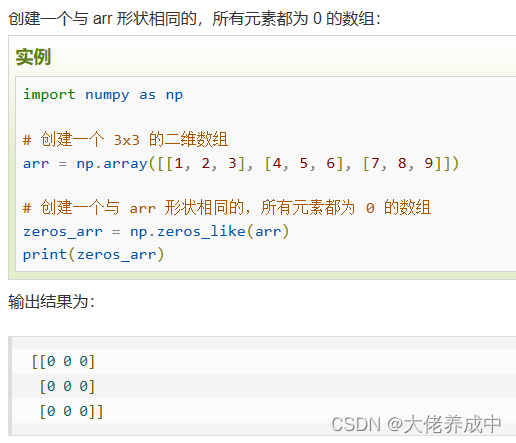

4.NumPy 从已有的数组创建数组







5.NumPy 从数值范围创建数组
np.arrange则是通过使用arrange函数来创建数值范围并返回ndarray对象,函数格式如下:




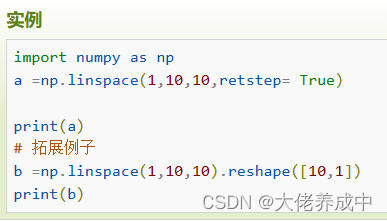
np.linspace函数用于创建一个一维数组,数组是一个等差数列构成的。
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
start 序列的起始值
stop 序列的终止值
num = 50 生成等步长的样本数量

import numpy as np
a =np.linspace(1,10,10)
print(a)
===>>>
[1 2 3 4 5 6 7 8 9 10]默认endpoint该值为true,数列中包含stop值,反之不包含,默认是True

默认endpoint设置为false,不包含终止值
import numpy as np
a = np.linspace(10, 20 ,5, endpoint =False)
print(a)
===>>>>>[10 12 14 16 18]

numpy.logspace
numpy.logspace函数用于创建等比数列,格式如下:
np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
start是序列的起始值为:base **start
stop是序列的终止值为:base **stop,如果endpoint为true,则该值包含于数列中
num是生成的等步长的样本数量,默认为50
endpoint 该值为true,数列中包含stop值,反之不包含,默认是True
base 对数log的底数
dtype 对ndarray的数据类型


2的零次方 2的一次方 2的二次方 2的三次方 2的四次方 2的五次方。。。。。。。
2的9次方
6.NumPy 切片和索引
ndarray对象的内容可以通过索引或者切片来访问和修改,与python中的list的切片操作是一样的

a=[0 1 2 3 4 5 6 7 8 9]
s=[2, 4, 6] (列表形式)
===>>>[2 4 6] (numpy形式)
可以不用slice的切片方式,直接来通过numpy数组中的冒号分隔切分参数
start : stop : step
import numpy as np
a = np.arange(10) ====》》[0 1 2 3 4 5 6 7 8 9]
b=a[2:7:2] 在生成的numpy数组中来由索引2开始到索引7停止,间隔为2
print(b) ===>>> [2 4 6]




切片操作同样适合多维数组的索引提取方法:
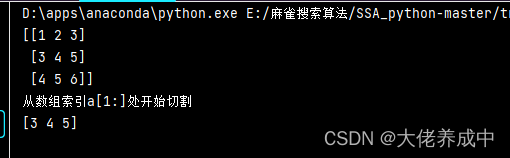
import numpy as np
a= np.array([[1,2,3],[3,4,5],[4,5,6]])
print(a)
##从某个索引处开始切割
print("从数组索引a[1:]处开始切割")
print(a[1:,])
在二维数组中,取出多行,全部列。故结果如下:

import numpy as np
a= np.array([[1,2,3],[3,4,5],[4,5,6]])
print(a)
##从某个索引处开始切割
print("从数组索引a[1:]处开始切割")
print(a[1,])取出该行全部列。和上面不同取出一行,因此降维为1维度
取出多行,就必须是二维,
切片还可以包括省略号 …,来使选择元组的长度与数组的维度相同。 如果在行位置使用省略号,它将返回包含行中元素的 ndarray。

7.NumPy 高级索引
Numpy比普通python序列提供了更多的索引方式
1.整数数组索引
整数数组索引是指使用了一个数组来访问另一个数组的元素,这个数组中的每个元素都是目标数组中某个维度上的索引值。
![]()
import numpy as np
x = np.array([[1, 2], [3, 4], [5, 6]])
y = x[[0,1,2], [0,1,0]]
###在二维数组中取出第0行,第0列
###第1行,第1列
###第2行,第0列
输出结果为
===>>>[1 4 5]
如果说你想构造,取出一个类似二维的话呢
import numpy as np
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print ('我们的数组是:' )
print (x)
print ('\n')
rows = np.array([[0,0],[3,3]])
cols = np.array([[0,2],[0,2]])
y = x[rows,cols]
print ('这个数组的四个角元素是:')
print (y)输出结果为:
[[0 1 2]
[3 4 5]
[6 7 8]
[9 10 11]]
这个数组的四个角元素是:
[[ 0 2]
[ 9 11]]
返回的结果是包含每个角元素的ndarray对象。
可以借助切片:和_与索引数组组合。
import numpy as np
a = np.array([[1,2,3], [4,5,6],[7,8,9]])
b = a[1:3, 1:3]
c = a[1:3,[1,2]]
d = a[...,1:]
print(b)
print(c)
print(d)[[5 6]
[8 9]]
[[5 6]
[8 9]]
[[2 3]
[5 6]
[8 9]]2.布尔索引
布尔数组来索引目标数组
布尔索引通过布尔运算来获取符合指定条件的元素的数组
import numpy as np
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print ('我们的数组是:')
print (x)
print ('\n')
# 现在我们会打印出大于 5 的元素
print ('大于 5 的元素是:')
print (x[x > 5])输出结果为:
我们的数组是:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
大于 5 的元素是:
[ 6 7 8 9 10 11]3.花式索引
花式索引指的是利用整数数组进行索引
花式索引根据索引数组的值作为目标数组的某个轴的下标来取值
对于使用一维整型数组作为索引,如果目标是一维数组,那么索引的结果就是对应位置的元素,如果目标是二维数组,那么对应下标的行
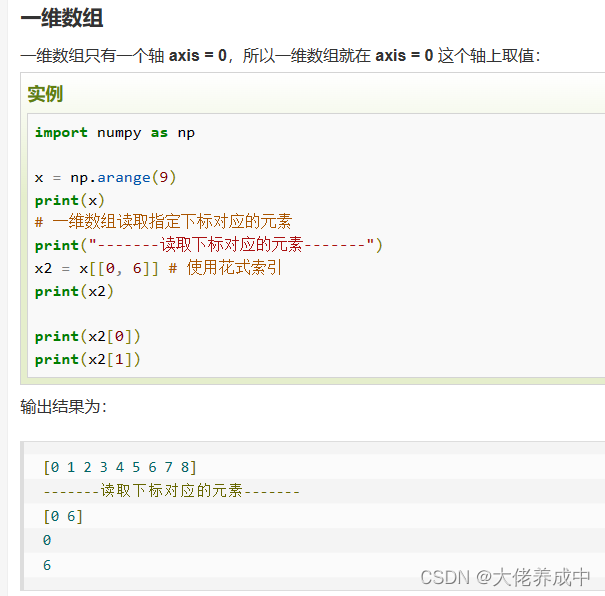
二维数组
1.


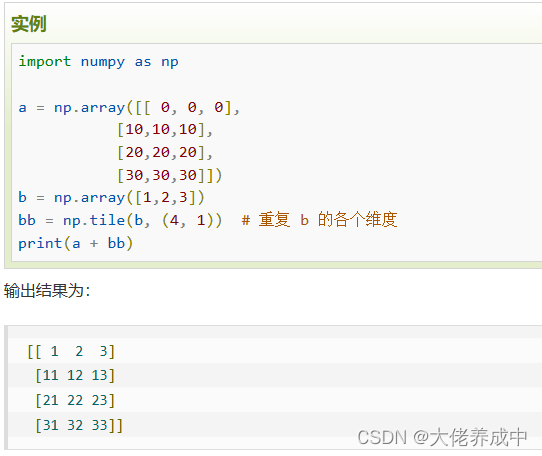
8.NumPy 广播



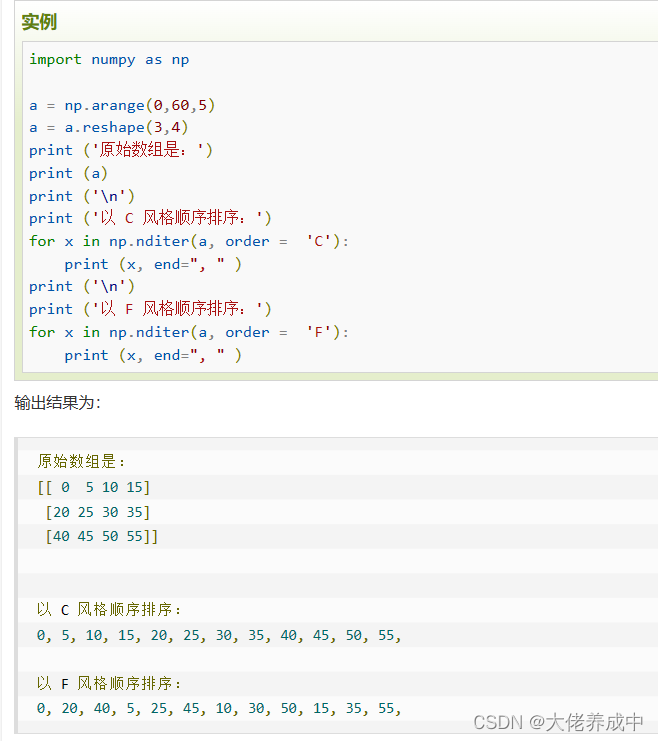
9.NumPy 迭代数组





控制遍历顺序
for x in np.nditer(a, order ="F'): Fortran order 即列序优先;
for x in np.nditer(a.T, order = "C"): C order ,即行序优先;

输出结果为:

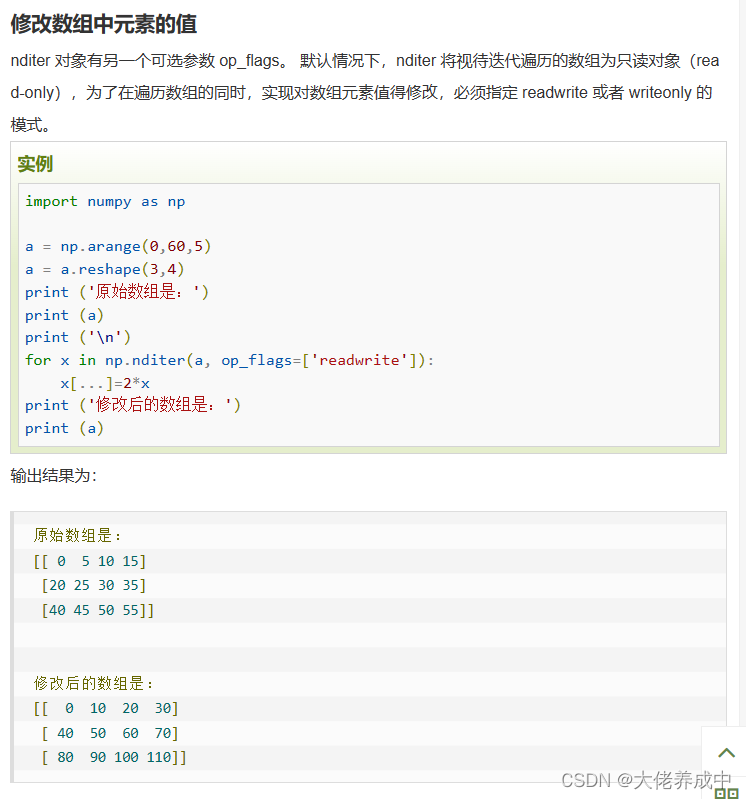



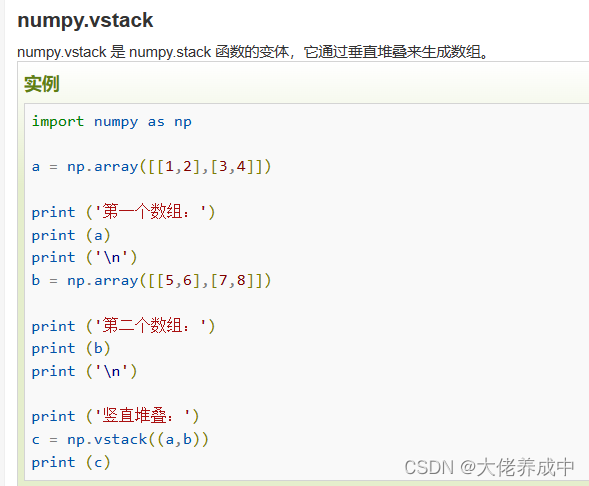
10.NumPy 数组操作


numpy.ndarray.flat是一个数组元素迭代器。








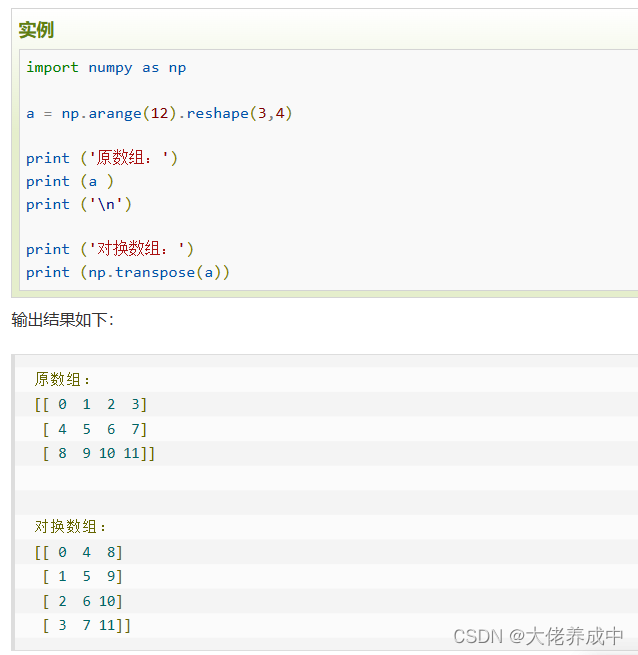



















































11. NumPy 位运算


12.NumPy 字符串函数













13.NumPy 数学函数










14. NumPy 算术函数








15. NumPy 统计函数


















16. NumPy排序、条件筛选函数

















17. NumPy 字节交换

18. NumPy 副本和视图
副本是一个数据的完整的拷贝,如果我们对副本进行修改,它不会影响到原始数据,物理内存不在同一位置。
视图是数据的一个别称或引用,通过该别称或引用亦便可访问、操作原有数据,但原有数据不会产生拷贝。如果我们对视图进行修改,它会影响到原始数据,物理内存在同一位置。








变量 a,b 都是 arr 的一部分视图,对视图的修改会直接反映到原数据中。但是我们观察 a,b 的 id,他们是不同的,也就是说,视图虽然指向原数据,但是他们和赋值引用还是有区别的。


19. NumPy 矩阵库(Matrix)











20. NumPy 线性代数












21. NumPy Matplotlib

pip3 install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
import numpy as np
from matplotlib import pyplot as plt
x = np.arange(1,11)
y = 2 * x + 5
plt.title("Matplotlib demo")
plt.xlabel("x axis caption")
plt.ylabel("y axis caption")
plt.plot(x,y)
plt.show()




























 927
927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









