







接上一篇文章线性回归——局部加权线性回归,我们知道如何解决线性回归中的欠拟合,现在我们介绍一下当出现过拟合时我们怎么解决。
首先回顾一下我们的标准线性回归中我们的回归系数
θ
=
(
X
T
X
)
−
1
X
T
y
\theta=(X^TX)^{-1}X^Ty
θ=(XTX)−1XTy,其中涉及到求逆矩阵,但是实际会存在这种情况,即我们的样本非常少或者特征数太多,导致样本m小于特征数n,会导致
X
T
X
X^TX
XTX不可逆。从数学角度是不可逆的,也就不能直接求解,线性上我们也可以知道这会导致过拟合,因为样本太少或模型太过复杂很容易就过拟合了。
解决过拟合我们可以增加训练集(并不一定有效)、可以减少特征、也可通过正则化。
这里我们就主要介绍正则化的使用:
正则化的一般形式就是在我们的代价函数后面加入惩罚项,通过设置惩罚项让回归系数减小。一般有如下两种正则化的方式:
L1:lasso,惩罚项为
λ
∑
i
=
1
m
∣
θ
i
∣
\lambda\sum_{i=1}^m|\theta_i|
λ∑i=1m∣θi∣
L2:ridge(岭回归),惩罚项为
λ
∑
i
=
1
m
θ
i
2
\lambda\sum_{i=1}^m\theta_i^2
λ∑i=1mθi2
1.岭回归
(1)代价函数:
J
(
θ
)
=
∑
i
=
1
m
(
f
(
x
i
)
−
y
i
)
2
+
λ
∑
i
=
1
m
θ
i
2
J(\theta)=\sum_{i=1}^m(f(x_i)-y_i)^2+\lambda\sum_{i=1}^m\theta_i^2
J(θ)=i=1∑m(f(xi)−yi)2+λi=1∑mθi2
其中
f
(
x
i
)
f(x_i)
f(xi)是我们的预测值,
f
(
x
i
)
=
θ
T
x
i
f(x_i)=\theta^Tx_i
f(xi)=θTxi。现在我们通过正规方程的解法来求解最优解,首先将我们的代价函数写矩阵的形式:
J
(
θ
)
=
(
X
θ
−
y
)
T
(
X
θ
−
y
)
+
λ
θ
T
θ
J(\theta)=(X\theta-y)^T(X\theta-y)+\lambda\theta^T\theta
J(θ)=(Xθ−y)T(Xθ−y)+λθTθ
其中,
θ
=
(
θ
1
θ
2
.
.
.
θ
n
)
\theta=\begin{pmatrix}\theta_1\\\theta_2\\...\\\theta_n\end{pmatrix}
θ=⎝⎜⎜⎛θ1θ2...θn⎠⎟⎟⎞,现在我们将其展开:
J
(
θ
)
=
(
θ
T
X
−
y
T
)
(
X
θ
−
y
)
+
λ
θ
T
θ
=
θ
T
X
T
X
θ
−
θ
T
X
y
−
y
T
X
θ
+
y
T
y
+
λ
θ
T
θ
=
θ
T
(
X
T
X
+
λ
I
)
θ
−
θ
T
X
y
−
y
T
X
θ
+
y
T
y
J(\theta)=(\theta^TX-y^T)(X\theta-y)+\lambda\theta^T\theta\\=\theta^TX^TX\theta-\theta^TXy-y^TX\theta+y^Ty+\lambda\theta^T\theta\\=\theta^T(X^TX+\lambda I)\theta-\theta^TXy-y^TX\theta+y^Ty
J(θ)=(θTX−yT)(Xθ−y)+λθTθ=θTXTXθ−θTXy−yTXθ+yTy+λθTθ=θT(XTX+λI)θ−θTXy−yTXθ+yTy
对
θ
\theta
θ求导:
δ
J
(
θ
)
δ
θ
=
(
X
T
X
+
λ
I
+
(
X
T
X
+
λ
I
)
T
)
θ
−
X
T
y
−
(
y
T
X
)
T
=
0
=
(
2
X
T
X
+
2
λ
I
)
θ
−
2
X
T
y
=
0
=
2
(
X
T
X
+
λ
I
)
θ
=
2
X
T
y
⟹
θ
=
(
X
X
T
+
λ
I
)
−
1
X
T
y
\frac{\delta J(\theta)}{\delta \theta}=(X^TX+\lambda I+(X^TX+\lambda I)^T)\theta-X^Ty-(y^TX)^T=0\\= (2X^TX+2\lambda I)\theta-2X^Ty=0\\= 2(X^TX+\lambda I)\theta=2X^Ty\\\implies \theta=(XX^T+\lambda I)^{-1}X^Ty
δθδJ(θ)=(XTX+λI+(XTX+λI)T)θ−XTy−(yTX)T=0=(2XTX+2λI)θ−2XTy=0=2(XTX+λI)θ=2XTy⟹θ=(XXT+λI)−1XTy
这里我们用到了一些常用的求导矩阵求导公式:
1.
δ
X
T
A
X
δ
X
=
(
A
+
A
T
)
X
\frac{\delta X^TAX}{\delta X}=(A+A^T)X
δXδXTAX=(A+AT)X
2. δ A X δ X = A T \frac{\delta AX}{\delta X}=A^T δXδAX=AT
3.
δ
X
T
A
δ
X
=
A
\frac{\delta X^TA}{\delta X}=A
δXδXTA=A
顺便补充一下矩阵求导的知识:矩阵求导、几种重要的矩阵及常用的矩阵求导公式
(2)python代码实现:
这里用的是《机器学习实战》里面的实现:
2.1算法实现:
from numpy import *
def ridgeRegres(xMat, yMat, lam=0.2):
xTx = xMat.T*xMat
denom = xTx + eye(shape(xMat)[1])*lam
if linalg.det(denom) == 0.0: //判断是否可逆
print("This matrix is singular, connot do inverse")
return
ws = denom.I * (xMat.T*yMat)
return ws
def ridgeTest(xArr, yArr):
xMat = mat(xArr); yMat=mat(yArr).T
#数据标准化
yMean = mean(yMat,0) #求均值
yMat = yMat - yMean #这里我也不知道为什么要对y也进行中心化
xMeans = mean(xMat,0) #求均值
xVar = var(xMat,0) #求方差
xMat = (xMat - xMeans)/xVar #标准化
numTestPts = 30
wMat = zeros((numTestPts,shape(xMat)[1]))
for i in range(numTestPts):
ws = ridgeRegres(xMat, yMat, exp(i-10)) #测试不同的lambda
wMat[i,:] = ws.T
return wMat
2.2绘制岭迹图:
上面我们得到了30个
λ
\lambda
λ值对应的回归系数,现在我们绘制出回归系数随
λ
\lambda
λ变化的曲线:
import matplotlib.pyplot as plt
import regression
abX, abY = regression.loadDataSet('data/Ch08/abalone.txt')
ridgeWeights = regression.ridgeTest(abX,abY)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(ridgeWeights)
plt.show()
结果如下:
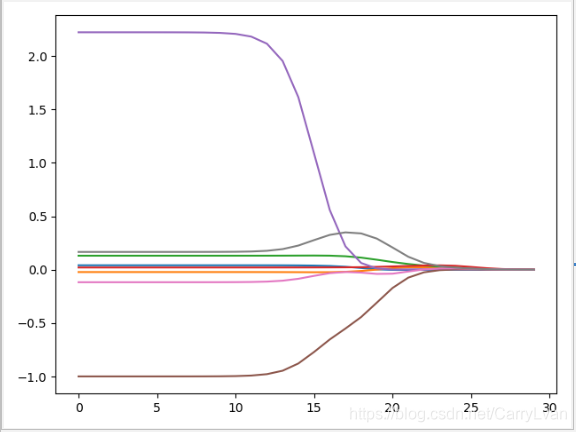
可以看到当
λ
\lambda
λ很小时,得到所有系数的原始值(与标准线性回归相同);当
λ
\lambda
λ很大时,得到所有都趋近0。如果要选出最优的回归系数,我们还需要进行交叉验证,选出对应误差最小的回归系数。
(3)岭回归的几何意义:
首先我们将我们上面的优化代价函数求回归系数的问题转换为如下形式:
{
J
(
θ
)
=
∑
i
=
1
m
(
f
(
x
i
)
−
y
i
)
2
s
.
t
.
∑
i
=
1
m
θ
i
2
≤
t
\begin{cases}J(\theta)=\sum_{i=1}^m(f(x_i)-y_i)^2\\s.t. \sum_{i=1}^m\theta_i^2\leq t\end{cases}
{J(θ)=∑i=1m(f(xi)−yi)2s.t.∑i=1mθi2≤t
然后我们考虑只有两个变量的情况,限制条件
θ
1
2
+
θ
2
2
≤
t
\theta_1^2+\theta_2^2\leq t
θ12+θ22≤t就是一个圆柱,而我们的
J
(
θ
)
J(\theta)
J(θ)就是一个抛物面,这里我们用等值线来表示,就是将这个三维的立体图映射到二维平面中,这个时候等值线与圆相切的点便是在约束条件下的最优点,因为越往外扩代价函数值就越大:
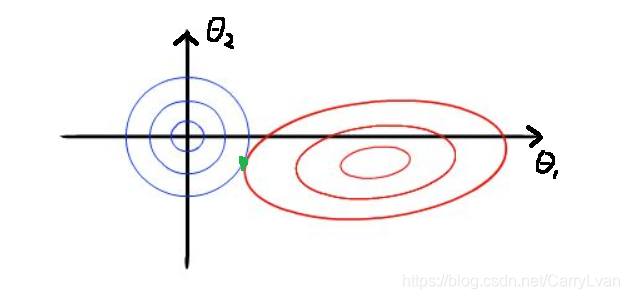
2.lasso
(1)代价函数:
J
(
θ
)
=
∑
i
=
1
m
(
f
(
x
i
)
−
y
i
)
2
+
λ
∑
i
=
1
m
∣
θ
i
∣
J(\theta)=\sum_{i=1}^m(f(x_i)-y_i)^2+\lambda\sum_{i=1}^m|\theta_i|
J(θ)=i=1∑m(f(xi)−yi)2+λi=1∑m∣θi∣
lasso的惩罚项变成了一次:
λ
∑
i
=
1
m
∣
θ
i
∣
\lambda\sum_{i=1}^m|\theta_i|
λ∑i=1m∣θi∣,使用绝对值取代了岭回归中的平方和,虽然变化不大,但是结果却大相径庭,当
λ
\lambda
λ很小时,一些系数会随着变为0,但是岭回归却很难使得某个系数恰好缩减为0,这一点我们可以通过比较他们的几何意义了解到。
(2)lasso的几何意义:
这里我们同样以两个变量的情况进行说明,画出他们的等值线,图中lasso的约束条件
∣
θ
1
∣
+
∣
θ
2
∣
≤
t
|\theta_1|+|\theta_2|\leq t
∣θ1∣+∣θ2∣≤t不同于岭回归,这里使用方形表示(两个变量的情况),
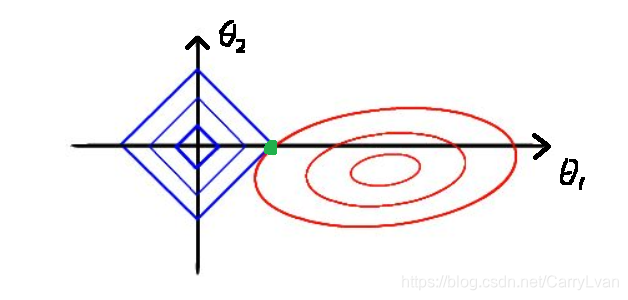
方形与我们抛物面相交就是到我们的回归系数的解,相比圆,方形的顶点更容易与抛物面相交,并且其中一旦方形的顶点与抛物线(如上图中绿色的点),就会导致
θ
2
\theta_2
θ2等于0,但是在岭回归中没有这样的点(概率很小),所以出现岭回归系数为0的概率就非常小。这也就意味着,lasso起到了很好的筛选变量的作用。
具体的代码实现就不讲了,因为可以有更简单但是效果差不多的实现方法——前向逐步回归。
3.前向逐步回归
前向逐步回归可以得到与lasso差不多的效果,但更加简单,它属于一种贪心算法,每一步都尽可能减少误差。每一步所做的决策是对某个系数增加或减少一个很小的值。
python代码实现:
from numpy import *
def regularize(xMat):#数据标准化
inMat = xMat.copy()
inMeans = mean(inMat,0) #计算均值
inVar = var(inMat,0) #计算方差
inMat = (inMat - inMeans)/inVar
return inMat
def rssError(yArr,yHatArr): #计算误差
return ((yArr-yHatArr)**2).sum()
def stageWise(xArr,yArr,eps=0.01,numIt = 100): #numIt是我们的迭代次数,eps是我们每次迭代更新的步长
xMat = mat(xArr); yMat = mat(yArr).T
yMean = mean(yMat,0)
yMat = yMat - yMean
xMat = regularize(xMat)
m,n = shape(xMat)
returnMat = zeros((numIt,n))
ws = zeros((n,1))
wsTest = ws.copy()
wsMax = ws.copy()
for i in range(numIt): #循环迭代numIt次
print(ws.T)
lowestError = inf
#每一次我们只对一个系数进行更新,因此我们需要循环每一个特征值,找出误差最小的回
#归系数作为下一次迭代进行更新
for j in range(n):
for sign in [-1,1]: #加和减两种都要计算
wsTest = ws.copy()
wsTest[j] += eps*sign
yTest = xMat*wsTest
rssE = rssError(yMat.A, yTest.A) #计算误差
if rssE < lowestError: #每次更新都与当前最小误差的进行比较
lowestError = rssE
wsMax = wsTest
ws = wsMax.copy()
returnMat[i,:]=ws.T
return returnMat
绘制结果
import matplotlib.pyplot as plt
import regression
abX, abY = regression.loadDataSet('data/Ch08/abalone.txt')
ridgeWeights = regression.stageWise(abX,abY,0.005,1000)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(ridgeWeights)
plt.show()
eps=0.005,numIt=1000的结果如下:
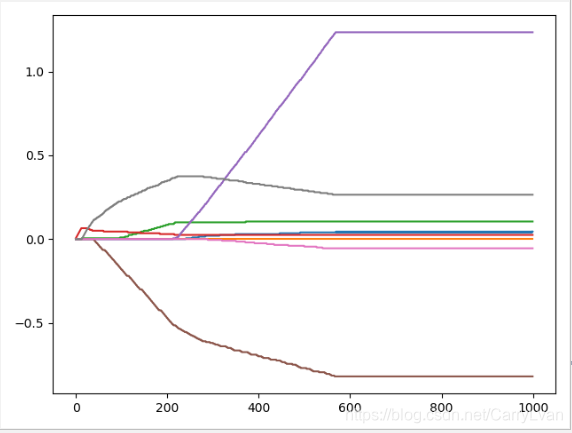

















 2294
2294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









