









1. 基本介绍
https://github.com/baidu/AnyQ.git
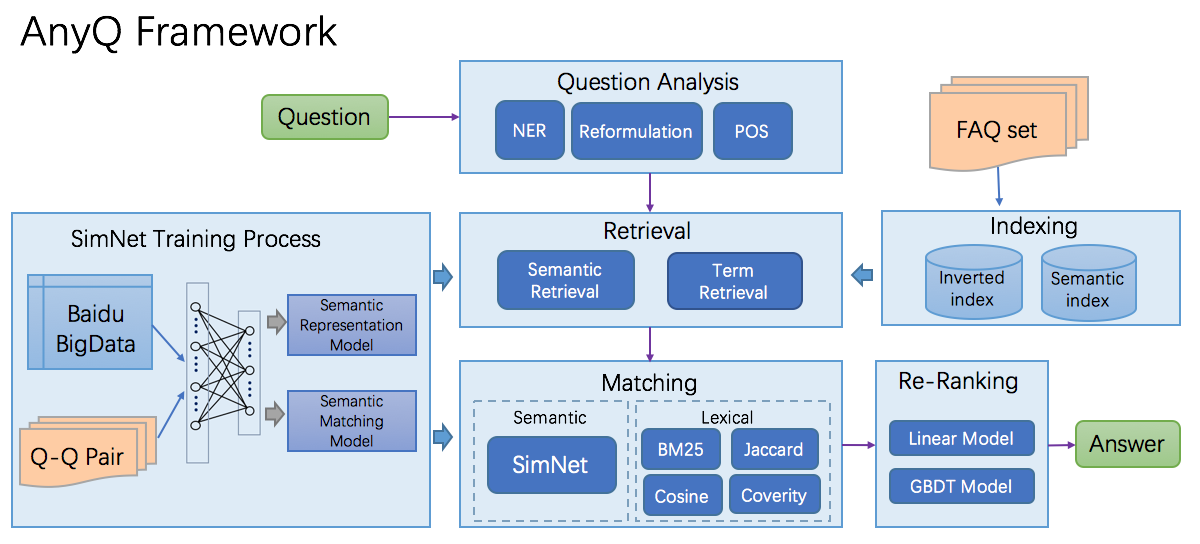
AnyQ系统框架主要由Question Analysis(问题分析 )、Retrieval、Matching、Re-Rank等部分组成(上图绿色圆角矩形Question开始,一直走到绿色圆角矩形Answer结束)。其他两部分:
- 一个是SimNet语义匹配框架的训练过程,
- 一个是问答数据集的索引(倒排索引:基于开源倒排索引Solr,加入百度开源分词;
语义检索:基于SimNet语义表示,使用ANNOY进行ANN检索)
整体流程控制的代码,参考:include/strategy/anyq_strategy.h以及对应的src/strategy/anyq_strategy.cpp
- 问题分析,包括NER命名实体识别,Reformulation,重组,POS词性标注。
- 其中,问题输入到solr里的时候,就已经进行过分词了。关于分词部分的配置,比如停用词等,可以参考:百度开源 FAQ 问答系统(AnyQ)|问题分析模块(Analysis)。
- NER,POS和Reformulation这三个任务是在问题分析中完成的,参考文件:include/analysis/analysis_strategy.h和对应的src文件src/analysis/analysis_strategy.cpp以及AnyQ系统配置教程中:config_tutorial.md#analysis部分。
- 检索(Retrieval),包括Semantic Retrieval(语义检索)和Term Retrieval(基于关键词的检索)。
- 输入的问题通过分析模块(Analysis)对问题进行分词,词向量表示等操作后,再输入到问题检索模块(Retrieval),由该模块将问题带入到FAQ数据集中进行检索,得到前N个候选问题。
- 可以查看2.2部分的截图,分析输入的query,然后找到与query相关的FAQ集合中的候选问题,candidate query。从输出的log提示中,可以知道使用的是
simnet_paddle_sim.cpp这个文件,可以点击这里了解这个文件(主要是完成语义匹配的功能)
SimNet是百度自然语言处理部于2013年自主研发的语义匹配框架,该框架在百度各产品上广泛应用,主要包括BOW、CNN、RNN、MM-DNN等核心网络结构形式,同时基于该框架也集成了学术界主流的语义匹配模型,如MatchPyramid、MV-LSTM、K-NRM等模型。SimNet使用PaddleFluid和Tensorflow实现,可方便实现模型扩展。使用SimNet构建出的模型可以便捷的加入AnyQ系统中,增强AnyQ系统的语义匹配能力
百度语义匹配模型-simnet代码整理- 看不太懂C++,伤不起。
- 总之Question Analysis中的NER(命名实体识别)、Reformulation(信息重组)、POS(position of speech)词性标注 都不是在simnet_paddle_sim这个文件中进行的。
- 计算这些候选问题的jaccard,使用的是
jaccard_sim.cpp这个文件,可以点击这里查看详细情况,其实这个文件挺简单的,就是jaccard相似度,Python里调一行的事情,换成c++加速了。Jaccard index , 又称为Jaccard相似系数(Jaccard similarity coefficient)用于比较有限样本集之间的相似性与差异性。Jaccard系数值越大,样本相似度越高。
- 将候选结果排序,找出最后选定的那个候选query。主要使用这个
rank_strategy.cpp文件,点击这里查看详细情况 - 返回上面选定的query对应的回答,作为最终的回答。主要使用这个 anyq_strategy.cpp,点击这里查看文件详情。
框架中包含的功能均通过插件形式加入,如Analysis中的中文切词,Retrieval中的倒排索引、语义索引,Matching中的Jaccard特征、SimNet语义匹配特征。
2 运行结果反推
2.1 solr分词说明
运行的第一步,运行下列shell脚本
cp ../tools/anyq_deps.sh .
sh anyq_deps.sh
这个脚本内容很少,完成的功能也很简单,下载定制版本solr。在solr-4.10.3版本基础上加入了百度开源词法分析作为中文分词插件。
之前有看过solr-4.10.3-anyq/example/solr/collection1/conf/schema.xml.bak这个文件,其实最下面一部分就是语言分词器的配置。

经过尝试不难发现,

从分词结果里可以看出,这个功能仅仅就是分词。

所以默认下载的这个solr已经集成了百度的分词工具了,如果需要自己添加别的分词工具,可以参考:Solr学习总结(八)IK 中文分词的配置和使用
可以查看/home/Anyq-master/build/solr-webapp/webapp/WEB-INF/lib这个文件夹,就可以看到libbaidusegmenter.so和libpaddle_fluid.so这两个一看就是百度的库:

关于配置的话,自己看不见就直接搜吧,参考:Linux中find常见用法示例
[root@567b3aed2b1c build]# find . -name "*schema.xml" -print
./solr-4.10.3-anyq/example/multicore/core0/conf/schema.xml
./solr-4.10.3-anyq/example/multicore/core1/conf/schema.xml
./solr-4.10.3-anyq/example/solr_config_set/common/managed-schema.xml ✅
./solr-4.10.3-anyq/example/solr/collection1/conf/managed-schema.xml
./solr-4.10.3-anyq/example/example-DIH/solr/tika/conf/schema.xml
./solr-4.10.3-anyq/example/example-DIH/solr/rss/conf/schema.xml
./solr-4.10.3-anyq/example/example-DIH/solr/solr/conf/schema.xml
./solr-4.10.3-anyq/example/example-DIH/solr/mail/conf/schema.xml
./solr-4.10.3-anyq/example/example-DIH/solr/db/conf/schema.xml
./solr-4.10.3-anyq/example/example-schemaless/solr/collection1/conf/schema.xml
vi ./solr-4.10.3-anyq/example/solr_config_set/common/managed-schema.xml这个文件,终于看到了百度分词的配置。
<fieldType name="text_multi_lang" class="solr.TextField">
<analyzer class="org.apache.lucene.analysis.baiducn.BaiduAnalyzer"/>
2.2 其他运行结果说明
# 启动solr, 依赖python-json, jdk>=1.8
cp ../tools/solr -rp solr_script
sh solr_script/anyq_solr.sh solr_script/sample_docs
#运行
./run_server
在完整的一次问答的响应的log输出中,可以看到

开始就是加载一些配置文件

然后检查网络服务怎么样,分词,和solr通信

和solr通信,找到返回的FAQ的结果,然后进行检索,还有排序策略

最后才是使用语义匹配看得分
–
2.2文件结构说明
.
├── AUTHORS
├── build # 编译生成的文件夹
│ ├── annoy_index_build_tool
│ ├── anyq_deps.sh
│ ├── CMakeCache.txt
│ ├── CMakeFiles
│ ├── cmake_install.cmake
│ ├── demo_anyq
│ ├── demo_anyq_multi
│ ├── example
│ ├── example.tar.gz
│ ├── faq
│ ├── feature_dump_tool
│ ├── libanyq.a
│ ├── logs
│ ├── Makefile
│ ├── nohup.out
│ ├── proto_build-prefix
│ ├── rpc_data
│ ├── run_server
│ ├── solr-4.10.3-anyq
│ ├── solr-4.10.3-anyq.tar.gz
│ ├── solr_script
│ ├── solr-webapp
│ └── third_party
├── cmake # cmake的脚本,指定需要的第三方库的处理方式
│ ├── external
│ └── proto_build.cmake
├── CMakeLists.txt # CMakeLists 就是cmake的脚本
├── demo
│ ├── annoy_index_build.cpp
│ ├── demo_anyq.cpp
│ ├── demo_anyq_multi.cpp
│ ├── feature_dump.cpp
│ └── run_server.cpp
├── docs
│ ├── config_tutorial.md
│ ├── images
│ ├── plugin_tutorial.md
│ └── semantic_retrieval_tutorial.md
├── include
│ ├── analysis
│ ├── common
│ ├── config
│ ├── dict
│ ├── matching
│ ├── rank
│ ├── retrieval
│ ├── server
│ └── strategy
├── LICENSE
├── proto
│ ├── anyq.proto
│ └── http_service.proto
├── README.EN.md
├── README.md
├── src
│ ├── analysis
│ ├── common
│ ├── config
│ ├── dict
│ ├── matching
│ ├── rank
│ ├── retrieval
│ ├── server
│ └── strategy
└── tools
├── anyq_deps.sh
├── common
├── ltr
├── simnet
└── solr
参考:















 1210
1210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











