







深度强化学习基础:策略学习
No.1 Policy Network
当有无数个状态和无数个动作时,不可能将每一个状态和动作概率记录在一张表里,这样就无法直接算策略函数,所以得做函数近似,寻出来一个函数来近似策略函数。
当用神经网络近似时,…

No.2 Policy-Based Reinforcement Learning 策略学习
 为了让策略函数越来越好,选取了J(θ)来评价,策略网络越好,J(θ)越大。
为了让策略函数越来越好,选取了J(θ)来评价,策略网络越好,J(θ)越大。
策略学习的目标:改进θ,使J(θ)越大越好。
改进θ用到梯度上升法。这里用到的是随机梯度,因为有s的随机性在。

No.3 Policy Gradient 策略梯度


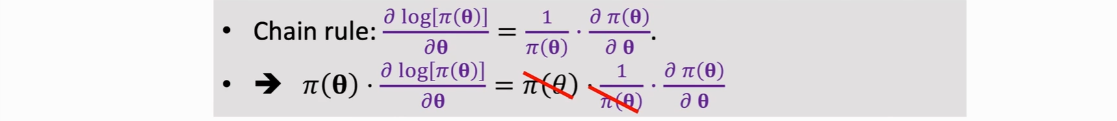
 对于离散的动作来说,
对于离散的动作来说,
 对于连续的动作来说,通过蒙特卡洛近似来估计期望
对于连续的动作来说,通过蒙特卡洛近似来估计期望


No.4 Update policy network using policy gradient
如何计算qt?

 actor-critic方法 详见下一节(价值学习与策略学习结合起来)笔记~
actor-critic方法 详见下一节(价值学习与策略学习结合起来)笔记~














 1817
1817











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









