







一.抓数据(豆瓣)处理数据
见github
二.数据可视化
import pandas as pd
import numpy as np
from pyecharts import options as opts
from pyecharts.charts import Pie, Page,Geo
from pyecharts.charts import Line
from pyecharts.charts import Bar
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType, ThemeType,ChartType
# 定义函数转换推荐星级字段
def transform_star(x):
if x == '力荐':
return 5
elif x == '推荐':
return 4
elif x == '还行':
return 3
elif x == '较差':
return 2
else:
return 1
# 获取短评信息关键词
def get_comment_word(df):
import jieba.analyse
import os
# 去停用词
stop_words = set()
# 加载停用词
stop_words_path = './stopword.txt'
with open(stop_words_path, 'r', encoding='utf-8') as sw:
for line in sw.readlines():
stop_words.add(line.strip())
# 添加停用词
stop_words.add('陈思诚')
stop_words.add('一张')
stop_words.add('一部')
stop_words.add('肖央')
stop_words.add('印度')
stop_words.add('电影')
stop_words.add('电影票')
# 合并评论信息
df_comment_all = df['短评信息'].str.cat()
# 使用TF-IDF算法提取关键词
word_num = jieba.analyse.extract_tags(df_comment_all, topK=100, withWeight=True, allowPOS=())
# 做一步筛选
word_num_selected = []
# 筛选掉停用词
for i in word_num:
if i[0] not in stop_words:
word_num_selected.append(i)
else:
pass
return word_num_selected
if __name__ == '__main__':
data = pd.read_csv('./wusha_finall.csv')
data.info()
# 星级转换
data['星级'] = data.推荐星级.map(lambda x:transform_star(x))
# 转换日期类型
data['评论时间'] = pd.to_datetime(data.评论时间)
# 提取日期
data['日期'] = data.评论时间.dt.date
key_words = get_comment_word(data)
key_words = pd.DataFrame(key_words, columns=['words', 'num'])
key_words.head()
#词云
word = WordCloud(init_opts=opts.InitOpts(width='1350px', height='750px'))
word.add("", [*zip(key_words.words, key_words.num)], word_size_range=[20, 200])
word.set_global_opts(title_opts=opts.TitleOpts(title="误杀电影评论词云图"),
toolbox_opts=opts.ToolboxOpts())
word.render('误杀电影评论词云图.html')
# 评分分布
# 总体评分百分比
score_perc = data.星级.value_counts() / data.星级.value_counts().sum()
score_perc = np.round(score_perc*100, 2)
# 绘制柱形图
pie1 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))
pie1.add("", [*zip(score_perc.index, score_perc.values)], radius=["40%", "75%"])
pie1.set_global_opts(title_opts=opts.TitleOpts(title='总体评分分布'),
legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"),
toolbox_opts=opts.ToolboxOpts())
pie1.set_series_opts(label_opts=opts.LabelOpts(formatter="{c}%"))
pie1.render('总体评分分布.html')
# 评论者分布
city_num = data.城市处理.value_counts()[:15]
city_num.drop('未知', inplace=True)
c1 = Geo(init_opts=opts.InitOpts(width='1350px', height='750px'))
c1.add_schema(maptype='china')
c1.add('geo', [list(z) for z in zip(city_num.index, city_num.values.astype('str'))], type_=ChartType.EFFECT_SCATTER)
c1.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
c1.set_global_opts(visualmap_opts=opts.VisualMapOpts(),
title_opts=opts.TitleOpts(title='评论者城市分布'),
toolbox_opts=opts.ToolboxOpts())
c1.render('评论者城市分布地图.html')
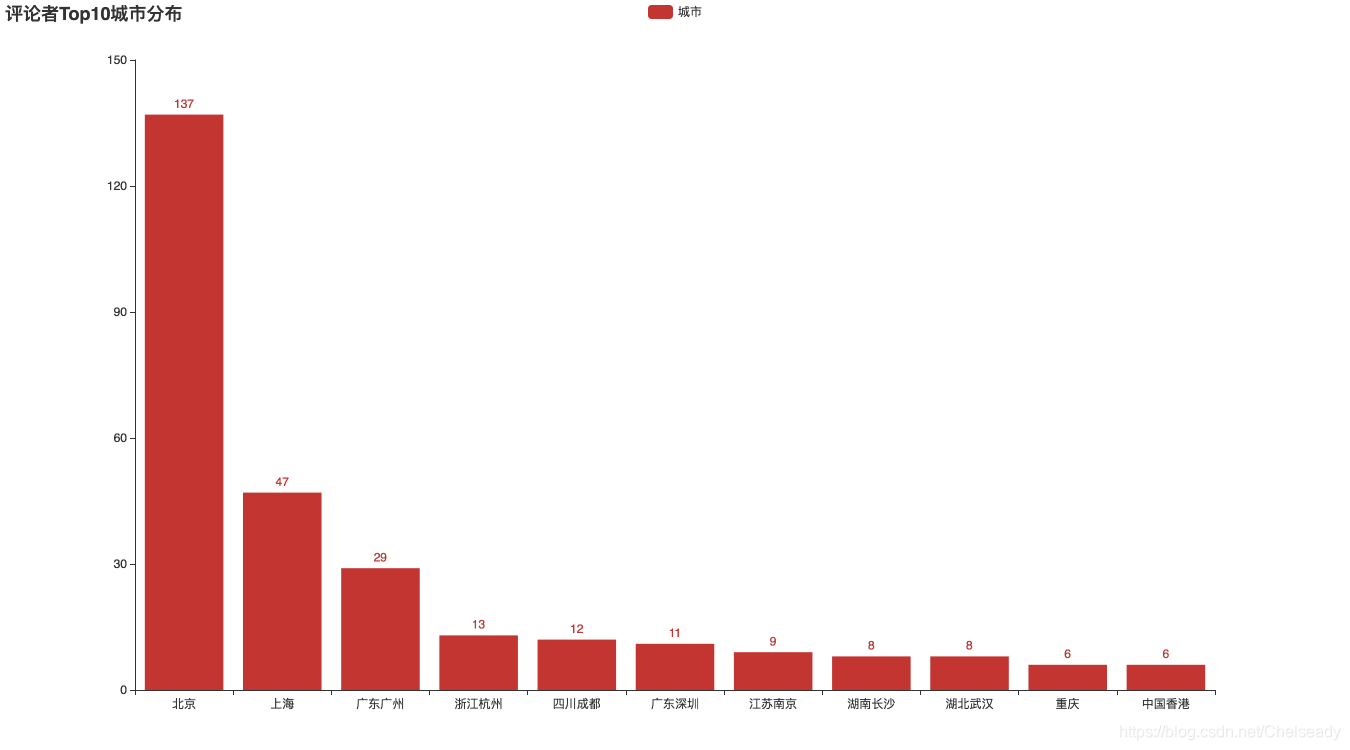
# 最多评论所在城市条形图
# 国内城市top10
city_top10 = data.城市处理.value_counts()[:12]
city_top10.drop('未知', inplace=True)
# 条形图
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(city_top10.index.tolist())
bar1.add_yaxis("城市", city_top10.values.tolist())
bar1.set_global_opts(title_opts=opts.TitleOpts(title="评论者Top10城市分布"), toolbox_opts=opts.ToolboxOpts())
bar1.render('评论者Top10城市分布条形图.html')
# 评论时间趋势
# 时间排序
time = data.日期.value_counts()
time.sort_index(inplace=True)
# 绘制时间走势图
line1 = Line(init_opts=opts.InitOpts(width='1350px', height='750px'))
line1.add_xaxis(time.index.tolist())
line1.add_yaxis('评论热度', time.values.tolist(), areastyle_opts=opts.AreaStyleOpts(opacity=0.5),
label_opts=opts.LabelOpts(is_show=False))
line1.set_global_opts(title_opts=opts.TitleOpts(title="时间走势图"), toolbox_opts=opts.ToolboxOpts())
line1.render('评论时间走势图.html')结果:
词云:

总体评分

评论者城市分布:
评论者地图分布

时间走势:















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









