







 本文是机器学习笔记的第三篇,重点介绍了支持向量机(SVM)的SMO算法,包括算法背景、简化版SMO处理小规模数据集以及完整版Platt SMO的加速优化。SMO算法通过分解大问题为小问题求解,优化目标函数,寻找最优的alpha和b。文章详细阐述了SMO算法的工作原理,并对比了简化版与完整版在选择alpha策略上的区别,展示了算法在不同数据集上的应用和效果。
本文是机器学习笔记的第三篇,重点介绍了支持向量机(SVM)的SMO算法,包括算法背景、简化版SMO处理小规模数据集以及完整版Platt SMO的加速优化。SMO算法通过分解大问题为小问题求解,优化目标函数,寻找最优的alpha和b。文章详细阐述了SMO算法的工作原理,并对比了简化版与完整版在选择alpha策略上的区别,展示了算法在不同数据集上的应用和效果。
机器学习笔记3:支持向量机的SMO高效优化算法
1. SMO算法背景
根据上一篇的支持向量机SVM的基础知识介绍,算法的根本目标就是实现对优化目标函数在约束条件下的求解问题。SMO算法表示序列最小优化(Sequential Minimal Optimization),将大优化问题分解为多个小优化问题来求解,小优化问题便于求解,同时对它们进行顺序求解的结果与作为整体求解的结果完全一致,并且SMO算法的求解时间要短很多。
SMO算法的目标就是求出一系列的alpha与b,一旦求出这些alpha,就很容易计算出权重向量w并得到分隔超平面。
SMO算法的工作原理是:每次循环中选择两个alpha,增大其中的一个同时减少另外一个,所谓的合适就是两个alpha符合一定的条件,条件之一就是两个alpha必须要在间隔边界之外,而第二个条件则是这两个alpha还没有进行过区间化处理或者不在边界上。
2.简化版SMO算法处理小规模数据集
简化版的SMO算法虽然执行速度较慢,Platt SMO算法中的外循环确定要优化的最佳alpha对,简化版跳过了这个部分,简化版的SMO算法首先在数据集上遍历每一个alpha,然后在剩下的alpha集合中随机选择另一个alpha,从而建立alpha对。这一点非常重要,同时改变两个alpha,因为我们有一个约束条件:
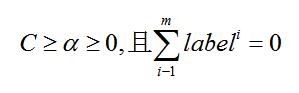
由于改变一个alpha可能会导致该约束条件失效,因此我们同时改变两个alpha。因此,代码整体如下,部分重要部分进行注释。
# coding=utf-8
'''
Date: August 14 2017
Author:Chenhao
Description: simplified SMO Algorithm
'''
from numpy import *
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
#读取文档内数据,数据格式为三列,前两列包含二维数据,第三列为label
def loadDataSet(fileName):
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat,labelMat
#用于在区间范围内选择一个整数
#输入函数i代表第一个alpha的下标,m是所有alpha的数目
def selectJrand(i,m):
j=i #we want to select any J not equal to i
while (j==i):
j = int(random.uniform(0,m))
return j
#用于在数值太大的情况下进行调整
#用于调整大于H小于L的alpha值
def clipAlpha(aj,H,L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
#简化版的SMO算法
def smoSimple(dataMatIn, classLabels, C, toler, maxIter): #五个输入参数对应表示数据集,类别标签,常数C,容错率,退出前最大循环次数
dataMatrix = mat(dataMatIn); labelMat = mat(classLabels).transpose() #将输入数据转化为matrix的形式,将类别标签进行转置
b = 0; m,n = shape(dataMatrix) #将常数b进行初始化,m,n分别表示数据集的行和列
alphas = mat(zeros((m,1))) #将alpha初始化为m行1列的全零矩阵
iter = 0 #该变量用于存储是在没有任何alpha改变的情况下遍历数据集的次数
while (iter < maxIter): #当遍历数据集的次数超过设定的最大次数后退出循环
alphaPairsChanged = 0 #该参数用于记录alpha是否已进行优化,每次循环先将其设为0
for i in range(m): #将数据集中的每一行进行测试
#multiply是numpy中的运算形式,将alpha与标签相乘的结果的转置与对应行的数据相乘再加b
#fxi表示将该点带入后进行计算得到的预测的类别,若Ei=0,则该点就在回归线上
fXi = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:].T)) + b
Ei = fXi - float(labelMat[i])#if checks if an example violates KKT conditions
#label[i]*Ei代表误差,如果误差很大可以根据对应的alpha值进行优化,同时检查alpha值使其不能等于0或C
if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) and (alphas[i] > 0)):
j = selectJrand(i,m) #随机选取另外一个数作为j,也就是选取另外一行数据
fXj = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,:].T)) + b
Ej = fXj - float(labelMat 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 909
909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









