







一、 深度学习现状的瓶颈:
1、 计算量巨大,消耗大量的计算资源
2、 模型内存占用大,消耗大量内存资源
3、 模型存储空间大,消耗大量存储空间
4、 只能在云端利用其大量的资源进行模型训练
5、 需要移动设备连接云端,不连接即无法使用其效果。
6、 移动端资源(CPU、GPU、内存)和云端的差距过大,无法进行类似云端的大规模分布式训练。
总结:大模型耗费大量的资源(计算、内存、存储、电)
二、 移动端优势:
1、 便携,轻量
2、 实时性强
3、 无需连接云,本地使用。
4、 移动端产品众多,贴近生活。
总结:移动+轻量化 = 未来AI
向移动端发展的手段。
对大而复杂的模型进行压缩。
三、 模型压缩:
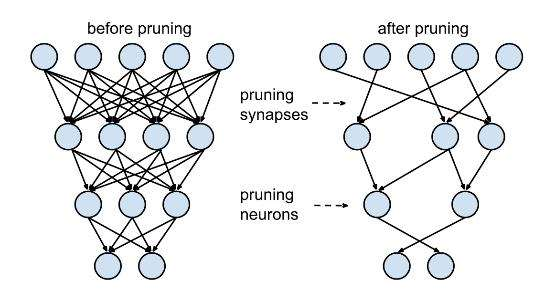
1、 Prunes the network:修枝剪叶,只保留一些重要的连接;
用于稀疏连接的重量级修剪,剪去权值低的,也就是去掉大部分几乎不可能发生的。
迭代地修剪和重新训练
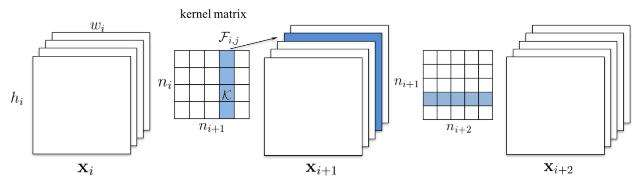
用L1正则化的通道级修剪
案例:
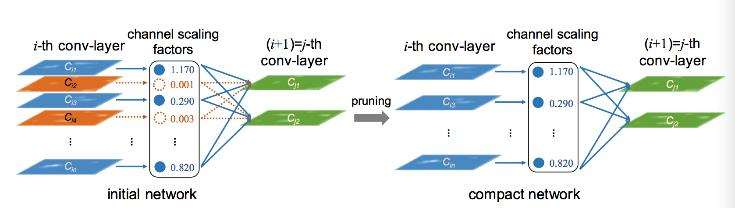
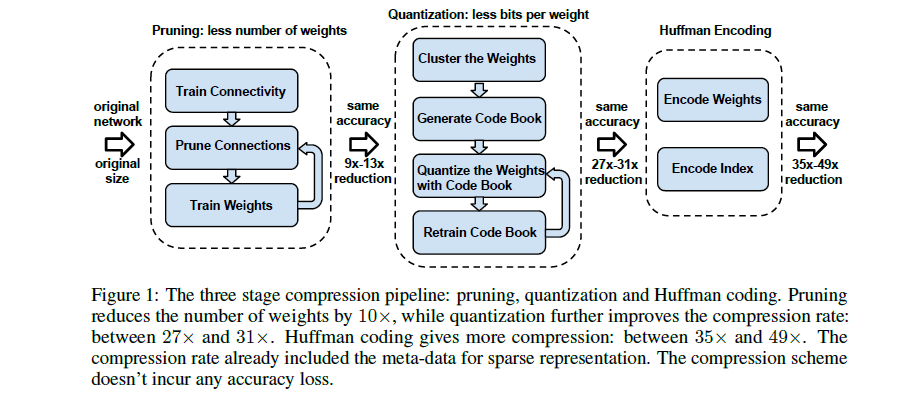
network pruning 技术已经被广泛应用到CNN模型的压缩中,通过剪枝达到了state-of-the-art 的结果,而且没有减少模型的准确率;
左边的pruning阶段可以看出,其过程是:
1)、正常的训练一个网络;
2)、把一些权值很小的连接进行剪枝:通过一个阈值来剪枝;
3)、retrain 这个剪完枝的稀疏连接的网络;
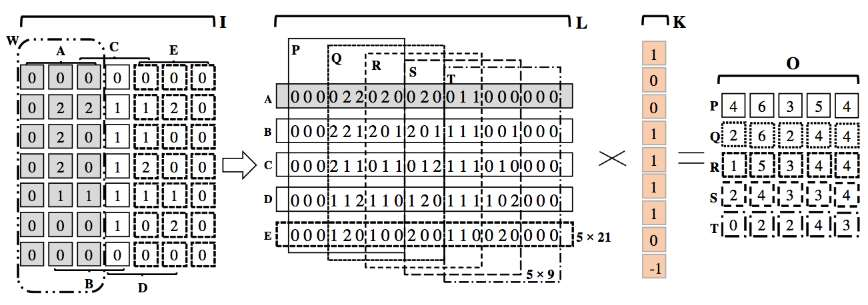
进一步压缩,对于weight的index,不再存储绝对位置的index,而是存储跟上一个有效weight的相对位置,这样index的字节数就可以被压缩了。
卷积层用 8bits 来保存这个相对位置的index,在全连接层中用 5bits 来保存;
用3bits保存相对位置为例子,当相对位置超过8(3bits)的时候,需要在相对位置为8的地方填充一个0,防止溢出;
2、 Quantize the weights:训练量化,通过权值量化来共享一些weights;
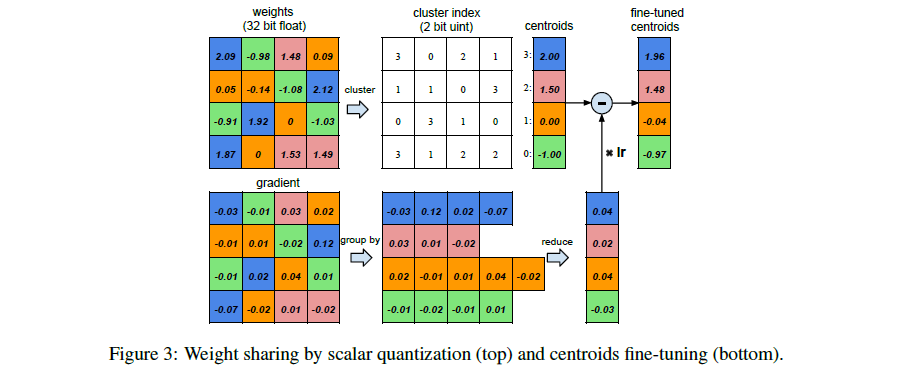
假设有一个层,它有4个输入神经元,4个输出神经元,那么它的权值就是4*4的矩阵; 图中左上是weight矩阵,左下是gradient矩阵。可以看到,图中作者把 weight矩阵 聚类成了4个cluster(由4种颜色表示)。属于同一类的weight共享同一个权值大小(看中间的白色矩形部分,每种颜色权值对应一个clusterindex);由于同一cluster的weight共享一个权值大小,所以我们只需要存储权值的index 例子中是4个cluster,所以原来每个weight需要32bits,现在只需要2bits,非常简单的压缩了16倍。而在 权值更新 的时候,所有的gradients按照weight矩阵的颜色来分组,同一组的gradient做一个相加的操作,得到是sum乘上learning rate再减去共享的centroids,得到一个fine-tuned centroids,这个过程看上图,画的非常清晰了。
对于AlexNet,卷积层quantization到8bits(256个共享权值),而全连接层quantization到5bits(32个共享权值),并且这样压缩之后的网络没有降低准确率
用非常简单的 K-means,对每一层都做一个weight的聚类,属于同一个 cluster 的就共享同一个权值大小。 注意的一点:跨层的weight不进行共享权值;
3、 Huffman coding:通过霍夫曼编码进一步压缩;
Huffman Coding 是一种非常常用的无损编码技术,它按照符号出现的概率来进行变长编码。
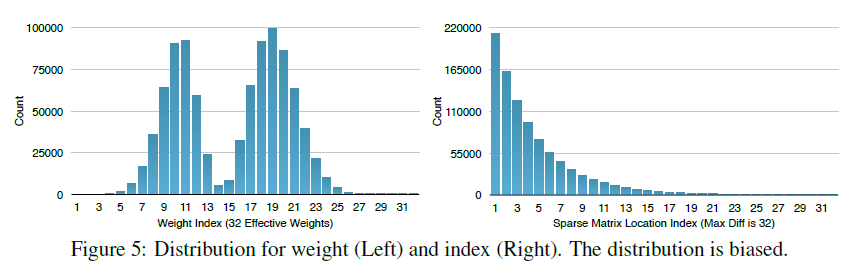
上图的权重以及权值索引分布来自于AlexNet的最后一个全连接层。
可以看出,其分布是非均匀的、双峰形状,因此我们可以利用Huffman编码来对其进行处理,最终可以进一步使的网络的存储减少20%~30%。

四、 压缩总结:
1、Pruning:把连接数减少到原来的 1/13~1/9;
2、 Quantization:每一个连接从原来的 32bits 减少到 5bits;
3、Huffman coding:网络的存储减少20%~30%
五、 设计较小的CNN架构设计
1、 SqueezeNet
SqueezeNet设计目标不是为了得到最佳的CNN识别精度,而是希望简化网络复杂度,同时达到public网络的识别精度。
三种原则:
替换3x3的卷积kernel为1x1的卷积kernel
减少输入3x3卷积的inputfeature map数量
减少pooling
压缩器:具有50x较少参数的AlexNet-level精度和< 0.5MB模型大小
2、 MobileNet
高效的卷积神经网络用于移动视觉应用
速度、模型大小上做了优化,并保持精度基本不变。
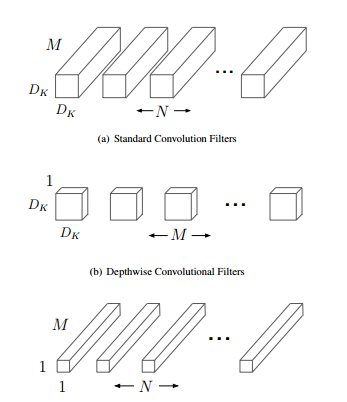
采用了depthwise separable convolutions(L. Sifre. Rigid-motionscattering for image classification, 2014. 1, 3) 的思想,在用3x3(或更大尺寸)卷积的时候并不对通道进行融合,而是采用depthwise(或叫channelwise)和1x1 pointwise的方法进行分解卷积。
mobilenet引入WidthMultiplier和Resolution Multiplier分别对网络进行瘦身和降低分辨率。
3、 ShuffleNet
一种非常高效的移动设备卷积神经网络
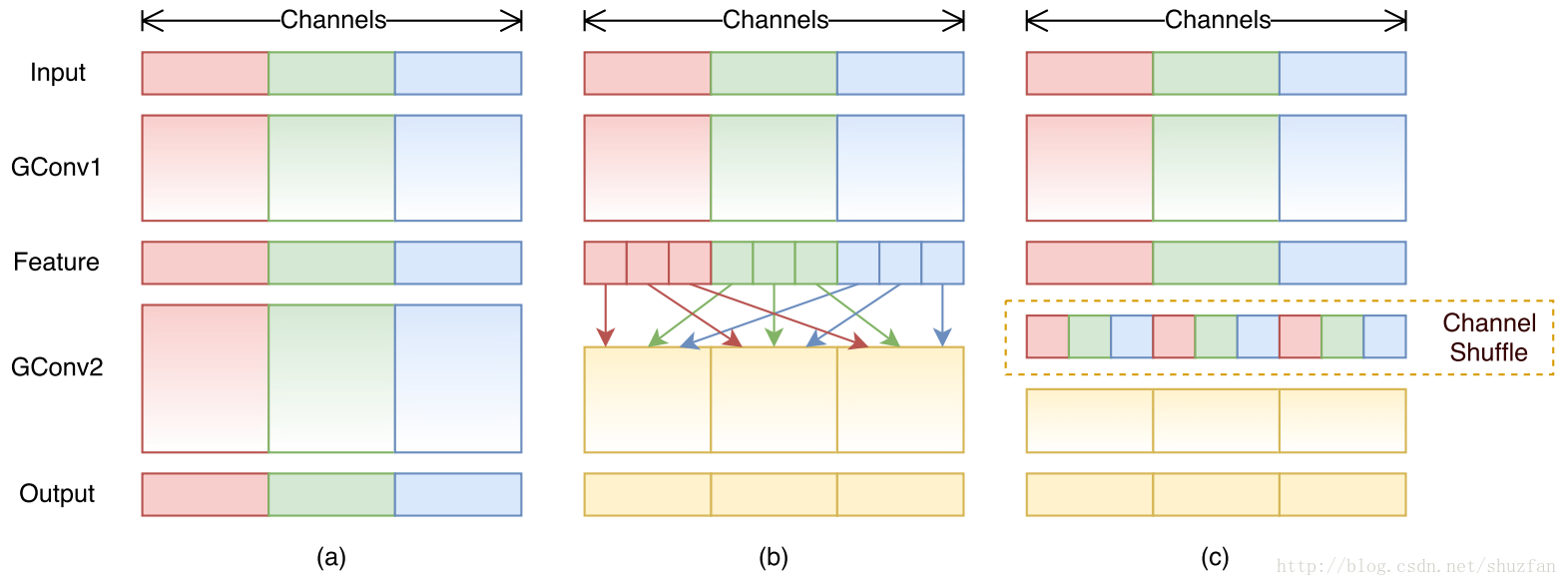
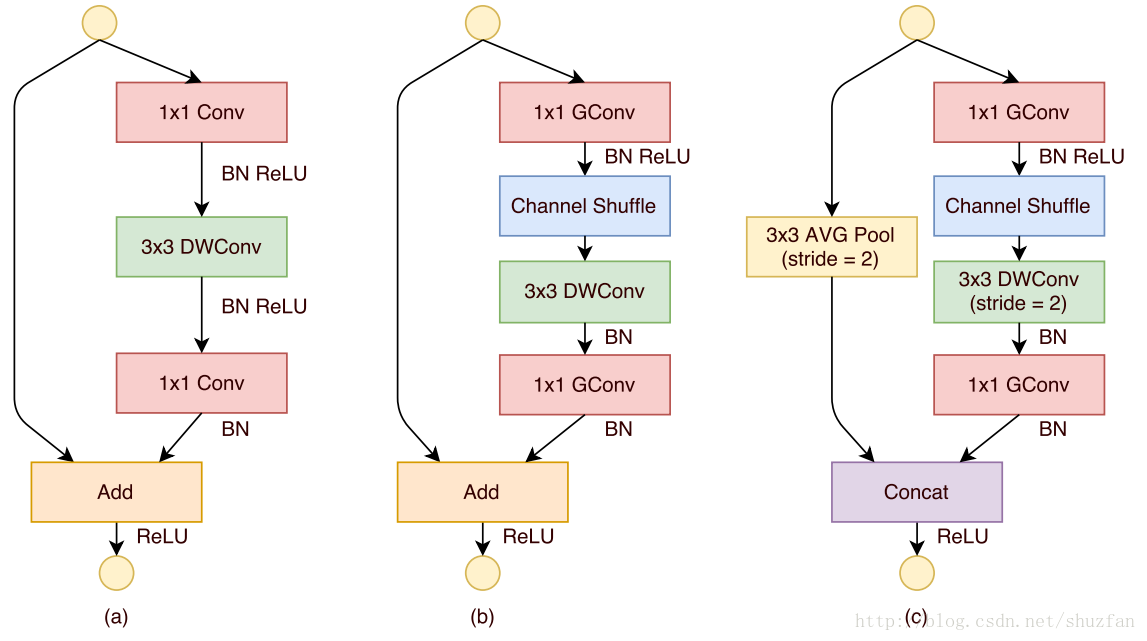
图a是一般的group convolution的实现效果。其造成的问题是,输出通道只和输入的某些通道有关,导致全局信息流通不畅,网络表达能力不足。
图b就是本文的方法啦。 即通过均匀排列,把groupconvolution后的feature map按通道进行均匀混合, 这样就可以更好的获取全局信息了。
图c是操作后的等价效果图。
ShuffleNet同样采用了类似于ResNet一样的模块化设计
图a是之前的一种ResNet网络结构模块,其参考了“MobileNet”的实现。其中的DWConv指的是 depthwise convolution。
图b是本文给出的一种模块(输出前后feature的size不变),相比于图a,只是将第一个1x1卷积改成了group convolution,同时后续增加通道 shuffle。
图c是本文给出的另一种模块(输出前后feature的size变小,但通道数增加),主要是为了应对下采样问题。 注意,最后的合并操作由原来的 “Add” 变成了 “Concat”, 目的是为了增加通道数。
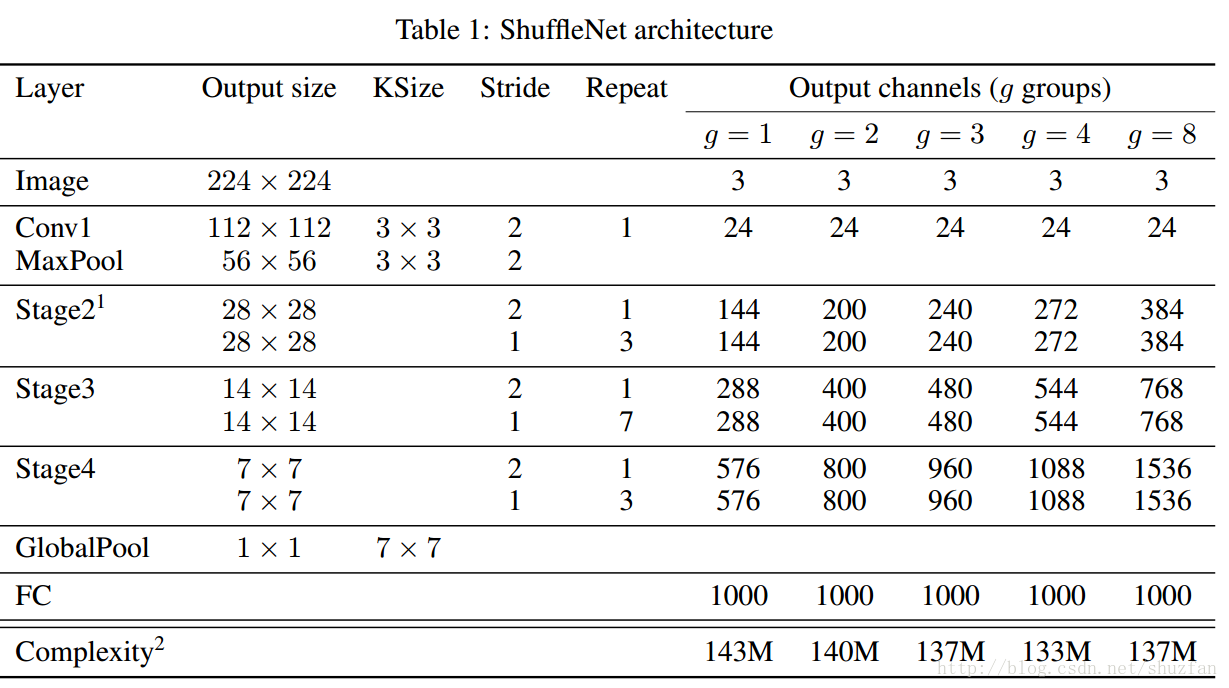
原始版本的ShuffleNet的结构如下:
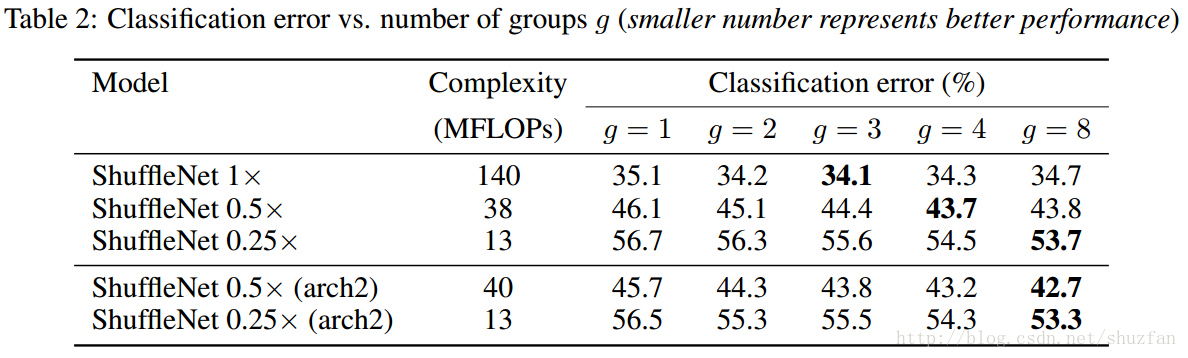
不同配置下的网络性能对比图:
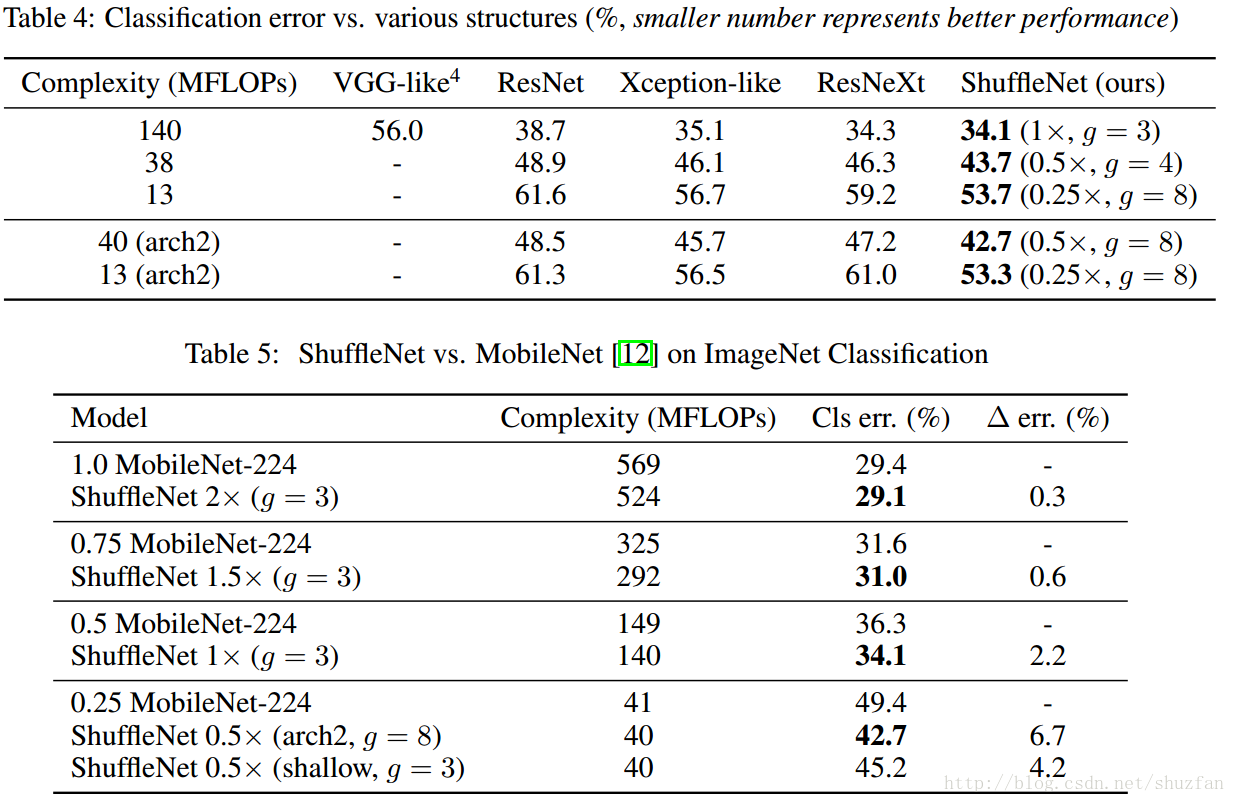
ShuffleNet 同之前一些网络的对比效果:
相比Xception和Mobilenet,ShuffleNet都获得了性能上的提升,至于速度带来的提升则不是很明显。
ShufflleNet的主要改进就只是增强了全局信息的流通。
六、 深度学习 框架:
Caffe Caffe2 MXNet Tensorflow Torch
NCNN、MDL
Tensorflow Lite
CoreML
从训练到推理
优化卷积计算:
利用im2col-based进行选择性的卷积
用于深度神经网络的内存高效卷积
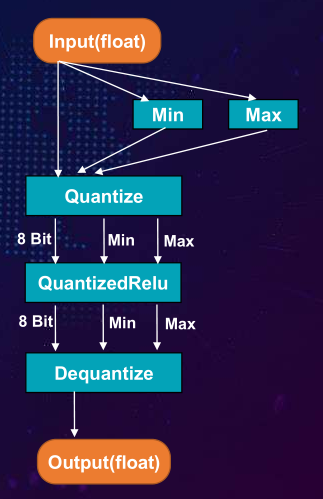
浮点运算定点化:
七、 Android端深度学习框架
NCNN vs MDL:
FrameWork
单线程
四线程
内存
NCNN
370ms
200ms
25M
MDL
360ms
190ms
30M
TensorflowLite:
Quantize MobileNet
Float Mobilenet
85ms
400ms
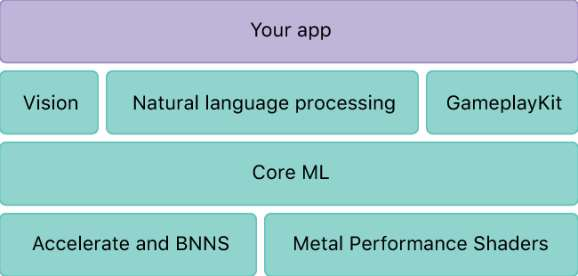
八、 iOS 上的深度学习
Core ML:
扩展性弱,仅支持IOS11及以上
MPSCNN:
充分利用GPU资源,不用抢占CPU
利用Metal开发新的层很方便
MPSCNN:
MPSImage
CNN图像的布局,宽度为3,高度为2。
在iPhone6s上MPSCNN VS NCNN :
FrameWork
Time
NCNN
110ms
MPSCNN
45ms

九、 移动深度学习与云上的深度学习结合
1、 大规模的训练需要放在云上,压缩优化后转移到移动端。
2、 部分小模型的计算即可在移动端进行计算,无需上云。
3、 实时性强的需要放在移动端
4、 网络要求严格的模型,放在移动端,防止断网造成的不必要损失。
十、 边缘计算推进移动深度学习
1、 推进边缘计算的设备主要是移动CPU,以高通、联发科、inter Y/M系列移动CPU为代表。
2、 移动CPU更新换代快,每年一次大的更新。
3、 移动CPU处理器性能直追PC的CPU
4、 移动CPU有低功耗的特点,节能。
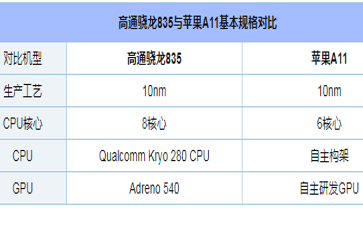
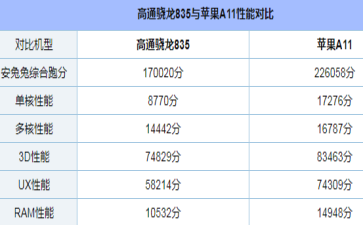
5、 现移动GPU已经逐渐走向成熟,从Apple的A11性能可以看出。
这是2017年旗舰移动CPU对比,骁龙VS Apple A11
十一、 参考资料:
http://blog.csdn.net/shuzfan/article/details/77141425
https://arxiv.org/pdf/1704.04861.pdf
https://arxiv.org/pdf/1510.00149.pdf
参考来自网络博客和以上论文。















 254
254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









