







 本文介绍了K-means聚类算法的基本原理,包括算法概述、聚类质量衡量标准SSE、优化策略以及对其他聚类方法如层次聚类和DBSCAN的简要说明。强调了K-means对初始质心和k值的依赖,以及如何通过改进方法提高聚类性能。
本文介绍了K-means聚类算法的基本原理,包括算法概述、聚类质量衡量标准SSE、优化策略以及对其他聚类方法如层次聚类和DBSCAN的简要说明。强调了K-means对初始质心和k值的依赖,以及如何通过改进方法提高聚类性能。
写在前面
今天参加了我在校招季的第一次面试,发现整个过程中只有讲到自己课题的时候才特别流畅,果然熟练度是一样很难替代的东西,只有花时间实践才能不断地加强。和面试官的交流让我意识到自己学习方法的不足,以往对待任何问题,只是习惯地去看公式、敲代码,很少彻底地/从数学的角度思考:这种方法为什么能解决这个问题?所以,今天我想好好总结一下几种最基础的机器学习算法,弥补之前学习的纰漏之处。
K-means聚类
算法概述
K-means聚类是一种无监督的学习方法,它的具体步骤相信动手写过代码的人都很清楚,在这里就简单地描述一下:
首先选择k个初始质心点(k为用户设定的参数,即期望分类的簇个数),然后遍历点集,将每个点分入与质心点距离最近的一类,重复执行上一步直到质心不再发生变化。
注1“距离最近”需要用合适的邻近性度量方法,对于点集通常使用欧式距离,对文档用余弦相似性。
注2 质心通常由簇的均值计算得到。
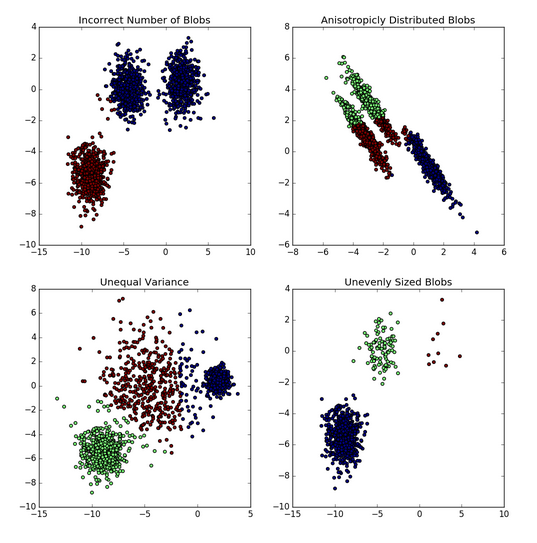
K-means的主要缺点是,聚类效果依赖于k值和初始质心的选择、对离群点敏感,同时,K-means聚类不能处理非球形簇、不同尺寸和不同密度的簇,如下图所示:
聚类质量的衡量标准
对于邻近性度量为欧式距离的情况,通常用误差平方和(SSE)作为聚类质量的衡量标准,SSE的定义如下,其中Ci为第i个簇&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6735
6735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









