







 决策树是一种直观的分类方法,通过递归地选择最佳特征进行数据划分。本文介绍了决策树的工作原理,包括信息熵、信息增益和Gini不纯度在选择最佳划分特征中的作用,以及过拟合问题和相应的剪枝策略。最后,总结了决策树的优缺点及其在机器学习中的应用。
决策树是一种直观的分类方法,通过递归地选择最佳特征进行数据划分。本文介绍了决策树的工作原理,包括信息熵、信息增益和Gini不纯度在选择最佳划分特征中的作用,以及过拟合问题和相应的剪枝策略。最后,总结了决策树的优缺点及其在机器学习中的应用。
写在前面:决策树是一种常用的分类方法,也是我开始学习数据挖掘后接触的第一个算法,它的原理非常好理解,但在学习过程中也有一些容易忽略的细节,今天就来总结一下。
决策树
工作原理
相信大家小的时候一定都玩过这样一个游戏,你在心里想一个人名,对方提一些只能用“是”或“否”来回答的问题(例如,TA是男人吗?TA是歌手吗?),在你回答这些问题后,由对方来猜你心中所想的人名。决策树的工作原理与这个游戏很相似,顾名思义,它的模型是树状的,在每个结点处进行“决策”,将数据集按照最具有“决定性”的特征进行划分,直到每个分支下的数据属于同一类型或具有相同的特征。
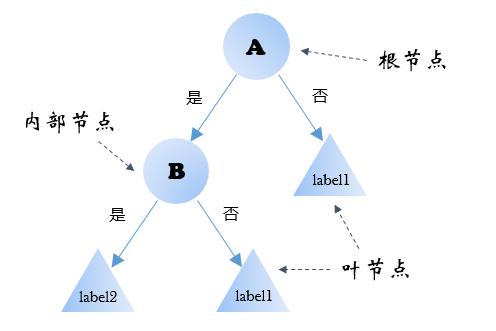
如图所示,决策树中包含三种结点:根节点,内部节点,叶节点。首先依据特征A将数据集划分成两部分,其中右侧子数据集拥有相同的类标签label1,因此不需要继续划分。再将左侧子数据集依据特征B划分成两部分,得到的两个子数据集都各自拥有统一的类标签,不需要继续划分。至此,一个最简单的决策树模型就构造成功了,接下来,就可以用它来对未知类别的数据进行预测:由根节点出发,在每个非终止节点处按照该节点对应的特征决定数据的走向,直到达到终止节点,分类结果便是该节点的类标签。
决策树的建立是一个递归的过程:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1014
1014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









