







 本文记录了基于Movielens数据集实现UserCF推荐算法的过程,包括数据读取、用户-电影评分矩阵构建及相似度计算。通过pandas库处理数据,创建倒排矩阵,并对热门物品进行惩罚改进。
本文记录了基于Movielens数据集实现UserCF推荐算法的过程,包括数据读取、用户-电影评分矩阵构建及相似度计算。通过pandas库处理数据,创建倒排矩阵,并对热门物品进行惩罚改进。
写在前面:今天基于Movielens数据集把《推荐系统实践》上的部分算法实现了一下,顺便巩固python和pandas库的使用,发现书本上的代码有很多不靠谱之处(也许是我水平不够),所以基本都是自己写的,不当之处,还望指正。
读取Movielens数据集
Movielens数据集有几种不同规模的,我选择的是1M-DataSet,大约包含6000多个用户对4000多部电影的一百万条评分记录,下载地址:MovieLens|GroupLens
数据集中有三个.dat文件,分别是users、movies、ratings,用Sublime Text2打开文件并观察。
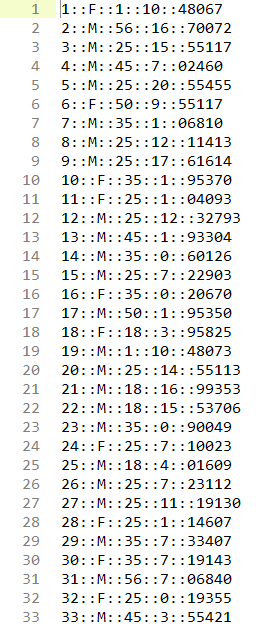
users.dat
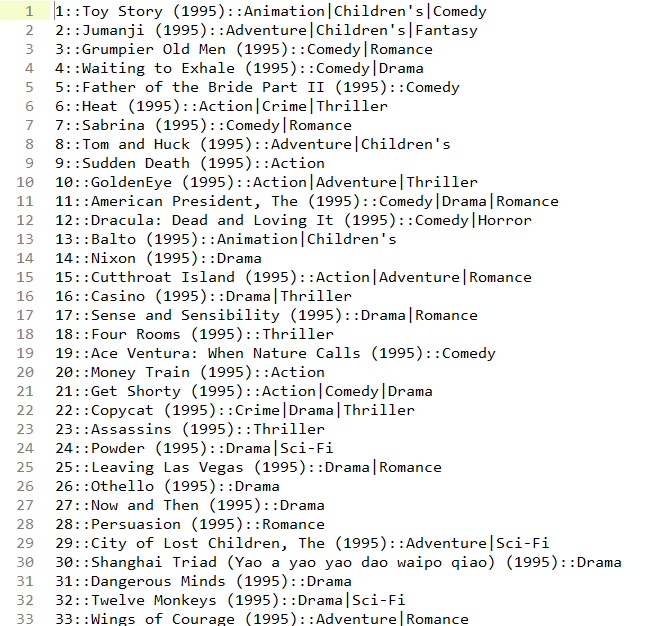
movies.dat

ratings.dat
三个文件都是用”::”分隔的表格形式文件,查看说明文档发现各列代表的信息分别如下:
users.dat:UserID::Gender::Age::Occupation::Zip-code
movies.dat:MovieID::Title::Genres
ratings.dat:UserID::MovieID::Rating::Timestamp
使用pandas库中的read_table函数读取文件,并用merge函数将三个表格合并,保存为.csv格式的文件。
unames=['user_id','gender','age','occupation', 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 964
964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









