







层次聚类(Hierarchical Clustering)是聚类算法的一种,通过计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树。在聚类树中,不同类别的原始数据点是树的最低层,树的顶层是一个聚类的根节点。创建聚类树有自下而上合并和自上而下分裂两种方法。Hierarchical methods中比较新的算法有BIRCH(Balanced Iterative Reducing and Clustering Using Hierarchies)主要是在数据体量很大的时候使用,而且数据类型是numerical;ROCK(A Hierarchical Clustering Algorithm for Categorical Attributes)主要用在categorical的数据类型上;Chameleon(A Hierarchical Clustering Algorithm Using Dynamic Modeling)里用到的linkage是kNN(k-nearest-neighbor)算法,并以此构建一个graph,Chameleon的聚类效果被认为非常强大,比BIRCH好用,但运算复杂的发很高,O(n^2)。
Bisecting K-Means二分k均值聚类算法(自上而下)
Bisecting k-means聚类算法,即二分k均值算法,它是k-means聚类算法的一个变体,主要是为了改进k-means算法随机选择初始质心的随机性造成聚类结果不确定性的问题,而Bisecting k-means算法受随机选择初始质心的影响比较小。
我们考虑在欧几里德空间中,衡量簇的质量通常使用如下度量:误差平方和(Sum of the Squared Error,简称SSE),也就是要计算执行聚类分析后,对每个点都要计算一个误差值,即非质心点到最近的质心的距离。我们的最终目标是,使得最终的SSE能够最小。
Bisecting k-means聚类算法的基本思想是,通过引入局部二分试验,每次试验都通过二分具有最大SSE值的一个簇,二分这个簇以后得到的2个子簇,选择2个子簇的总SSE最小的划分方法,这样能够保证每次二分得到的2个簇是比较优的(也可能是最优的),也就是这2个簇的划分可能是局部最优的,取决于试验的次数。
Bisecting k-means聚类算法的具体执行过程,描述如下所示:
•初始时,将待聚类数据集D作为一个簇C0,即C={C0},输入参数为:二分试验次数m、k-means聚类的基本参数;
•取C中具有最大SSE的簇Cp,进行二分试验m次:调用k-means聚类算法,取k=2,将Cp分为2个簇:Ci1、Ci2,一共得到m个二分结果集合B={B1,B2,…,Bm},其中,Bi={Ci1,Ci2},这里Ci1和Ci2为每一次二分试验得到的2个簇;
•计算上一步二分结果集合B中,每一个划分方法得到的2个簇的总SSE值,选择具有最小总SSE的二分方法得到的结果:Bj={Cj1,Cj2},并将簇Cj1、Cj2加入到集合C,并将Cp从C中移除;
•重复步骤2和3,直到得到k个簇,即集合C中有k个簇。
同k-means算法一样,Bisecting k-means算法不适用于非球形簇的聚类,而且不同尺寸和密度的类型的簇,也不太适合。
Agglomerative Hierarchical Clustering,AHC 合成聚类算法(自下而上、也称为AGNES)

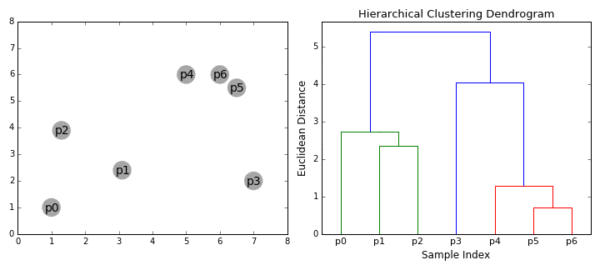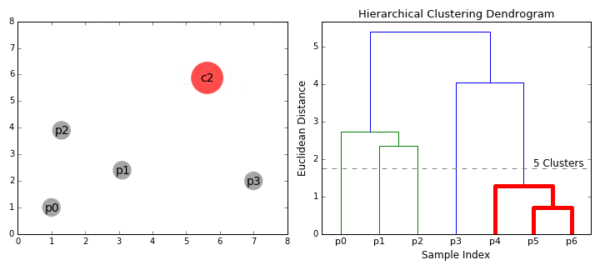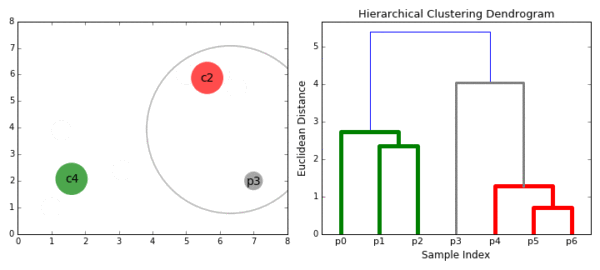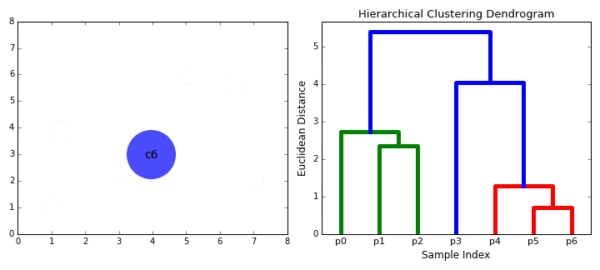
合成聚类合并算法
层次聚类的合并算法通过计算两类数据点间的相似性,对所有数据点中最为相似的两个数据点进行组合,并反复迭代这一过程。简单的说层次聚类的合并算法是通过计算每一个类别的数据点与所有数据点之间的距离来确定它们之间的相似性,距离越小,相似度越高。并将距离最近的两个数据点或类别进行组合,生成聚类树。
假设有N个待聚类的样本,基本步骤就是:
•(初始化)把每个样本归为一类,计算每两个类之间的距离,也就是样本与样本之间的相似度;
•寻找各个类之间最近的两个类,把他们归为一类(这样类的总数就少了一个);
•重新计算新生成的这个类与各个旧类之间的相似度;
•重复2和3直到所有样本点都归为一类,结束。
合成聚类
整个聚类过程其实是建立了一棵树,在建立的过程中,可以通过在第二步上设置一个阈值,当最近的两个类的距离大于这个阈值,则认为迭代可以终止。另外关键的一步就是第三步,如何判断两个类之间的相似度有不少种方法。
距离计算方法
计算两个组合数据点间距离的方法有三种,分别为Single Linkage(最小距离)、Complete Linkage(最大距离)、Average Linkage(平均距离)和 ward linkage(即最短最长平均,离差平方和)。在开始计算之前,我们先来介绍下这三种计算方法以及各自的优缺点:
Single Linkage的计算方法是将两个组合数据点中距离最近的两个数据点间的距离作为这两个组合数据点的距离。这种方法容易受到极端值的影响。两个很相似的组合数据点可能由于其中的某个极端的数据点距离较近而组合在一起。
Complete Linkage的计算方法与Single Linkage相反,将两个组合数据点中距离最远的两个数据点间的距离作为这两个组合数据点的距离。Complete Linkage的问题也与Single Linkage相反,两个不相似的组合数据点可能由于其中的极端值距离较远而无法组合在一起。
Average Linkage的计算方法是计算两个组合数据点中的每个数据点与其他所有数据点的距离。将所有距离的均值作为两个组合数据点间的距离。这种方法计算量比较大,但结果比前两种方法更合理。
我们使用Average Linkage计算组合数据点间的距离。下面是计算组合数据点(A,F)到(B,C)的距离,这里分别计算了(A,F)和(B,C)两两间距离的均值。这种聚类的方法描述起来比较简单,但是计算复杂度比较高,为了寻找距离最近/远和均值,都需要对所有的距离计算个遍,需要用到双重循环,每次迭代都只能合并两个子类,这是非常慢的。
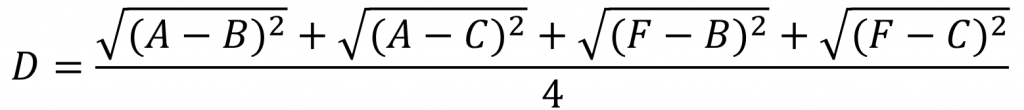

ward
ward method是要求每次合并后ESS的增量最小。
ward's method是分层聚类凝聚法的一种常见的度量cluster之间距离的方法,其基本过程:
1. 计算每个cluster的ESS
2. 计算总的ESS
3. 枚举所有二项cluster【N个cluster是N*(N-1)/2个二项集】,计算合并这两个cluster后的总ESS值
4. 选择总ESS值增长最小的那两个cluster合并
5. 重复以上过程直到N减少到1
参考:https://www.jianshu.com/p/785bb19386db
https://my.oschina.net/songjinghe/blog/508553
https://blog.csdn.net/bjfu_stat/article/details/47700041
http://blog.sciencenet.cn/blog-2827057-921772.html
















 1082
1082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











