







最近在做关于跨模态的医学图像生成,所以今天就跟大家聊一聊如何用自己的数据集训练CycleGAN吧~
首先,我们来聊聊什么是CycleGAN?
CycleGAN的一个重要应用领域是Domain Adaptation(域迁移:可以通俗的理解为画风迁移),比如可以把一张普通的风景照变化成梵高化作,或者将游戏画面变化成真实世界画面等等(如图1)。

图1 效果预览
CycleGAN特点就是通过一个循环,首先将图像从一个域转换到另一个域,然后,再转回来,如果两次转换都很精准的话,那么,转换后的图像应该与输入的图像基本一致。通过这样的的一个循环,CycleGAN将转换前后图片的配对,类似于有监督学习,提升了转换效果。
其中,在跨模态医疗图像生成中,大多会用到CycleGAN来完成。比如说,T2转T1等等。
接下来废话不多说,我来教教大家如何用自己的数据集训练CycleGAN。文末会附上资源(代码和论文)。
第一步,下载代码。解压后应该是图2这样。

图2 代码构成
第二步,数据准备。我这边是做的核磁共振T2转T1。大家在datasets文件夹中创建一个horse2zebra文件夹(如图3)。
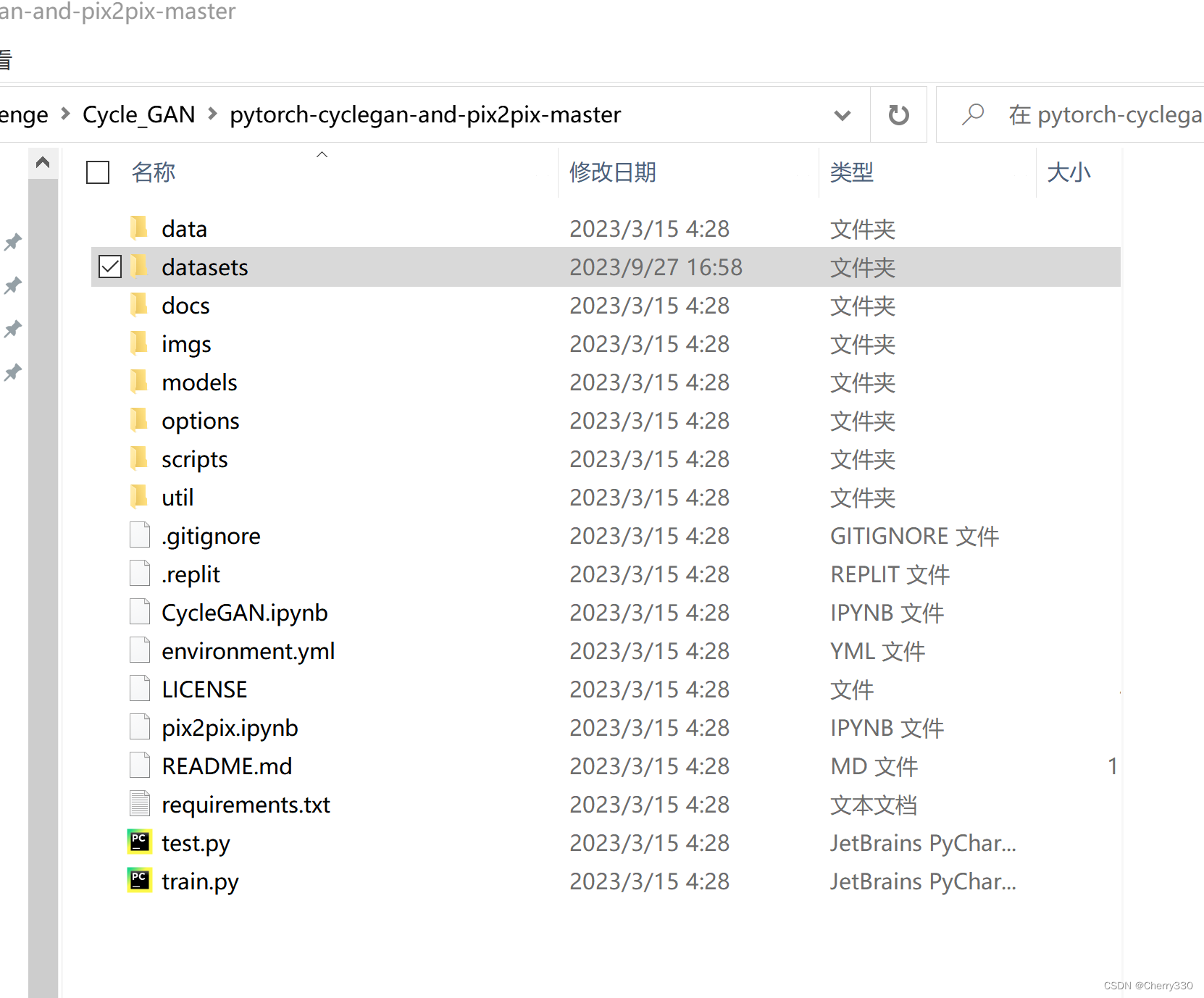
图3 horse2zebra文件夹
horse2zebra文件夹构成如下(图4)。大家将对应的图片放入文件夹中。数据集就完成啦~
需要注意的是,trainA和trainB是训练的数据集,testA和testB是测试的数据集,大家记得按照自己需求进行分配哦~ trainA和testA是需要转换的图片,就是我做的这个的T2图片,trainB和testB是风格图片,就是我的任务中的T1图片。如图5。
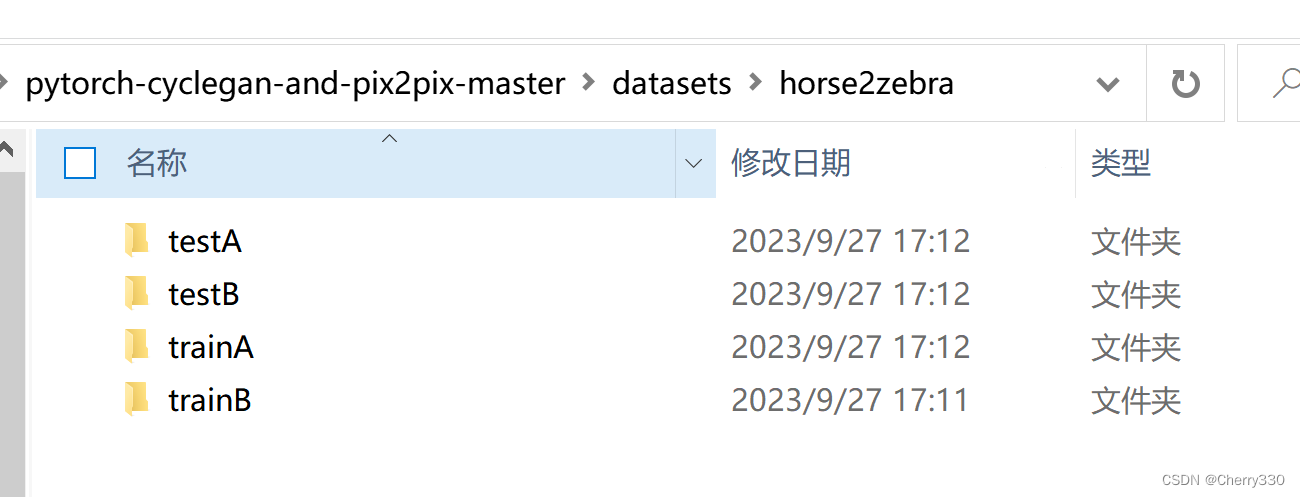
图4 horse2zebra文件夹构成
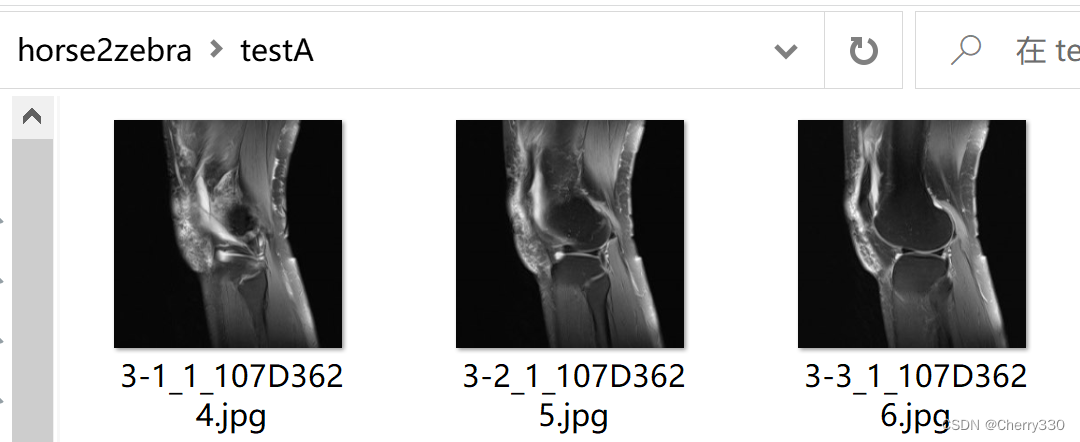

图5 数据集构成
第三步,开始训练数据集啦!我是用的学校服务器,通过命令行执行代码。
需要调整的参数有epoch和batch_size。大家在根据图6找到这几个参数,并根据自己的情况进行修改即可。
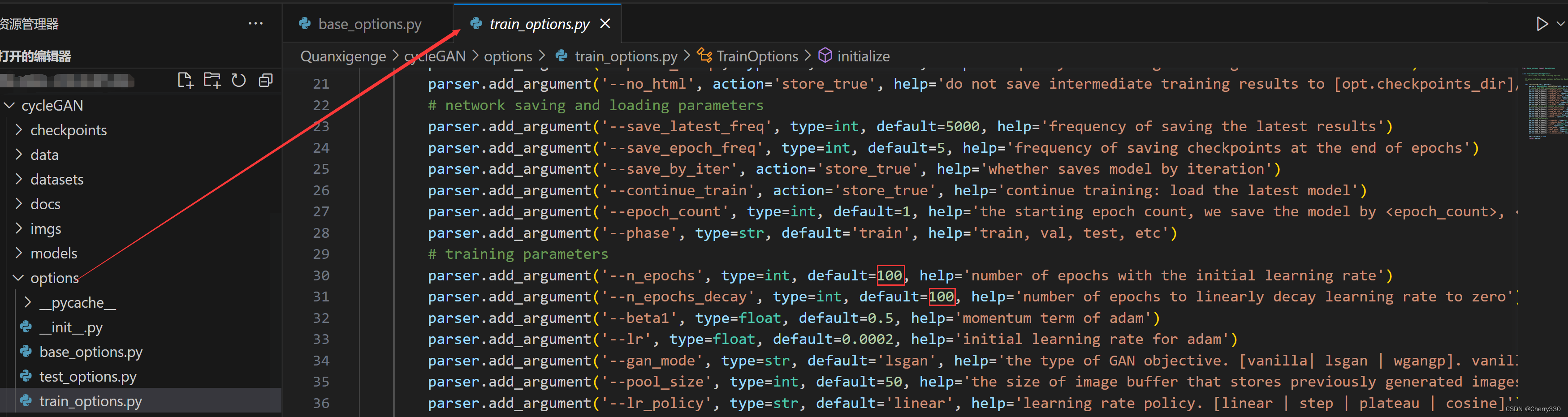
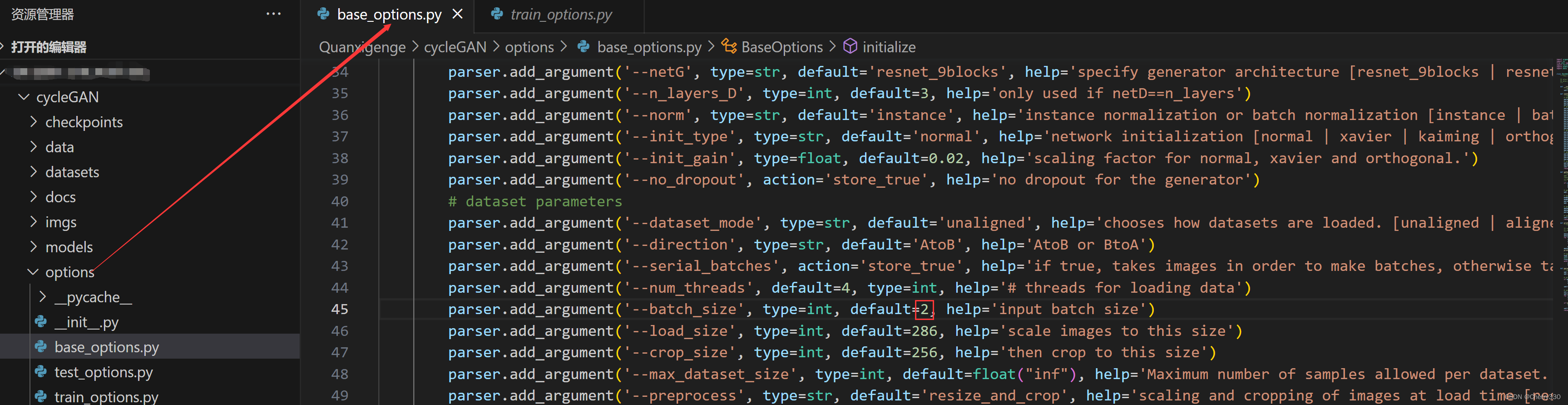
图6 参数位置
在命令行中输入下述代码,执行就可以开始训练啦!
nohup python train.py --dataroot ./datasets/horse2zebra --name horse2zebra_cyclegan --model cycle_gan &在nohup.out文件中会出现运行结果(如图7)。
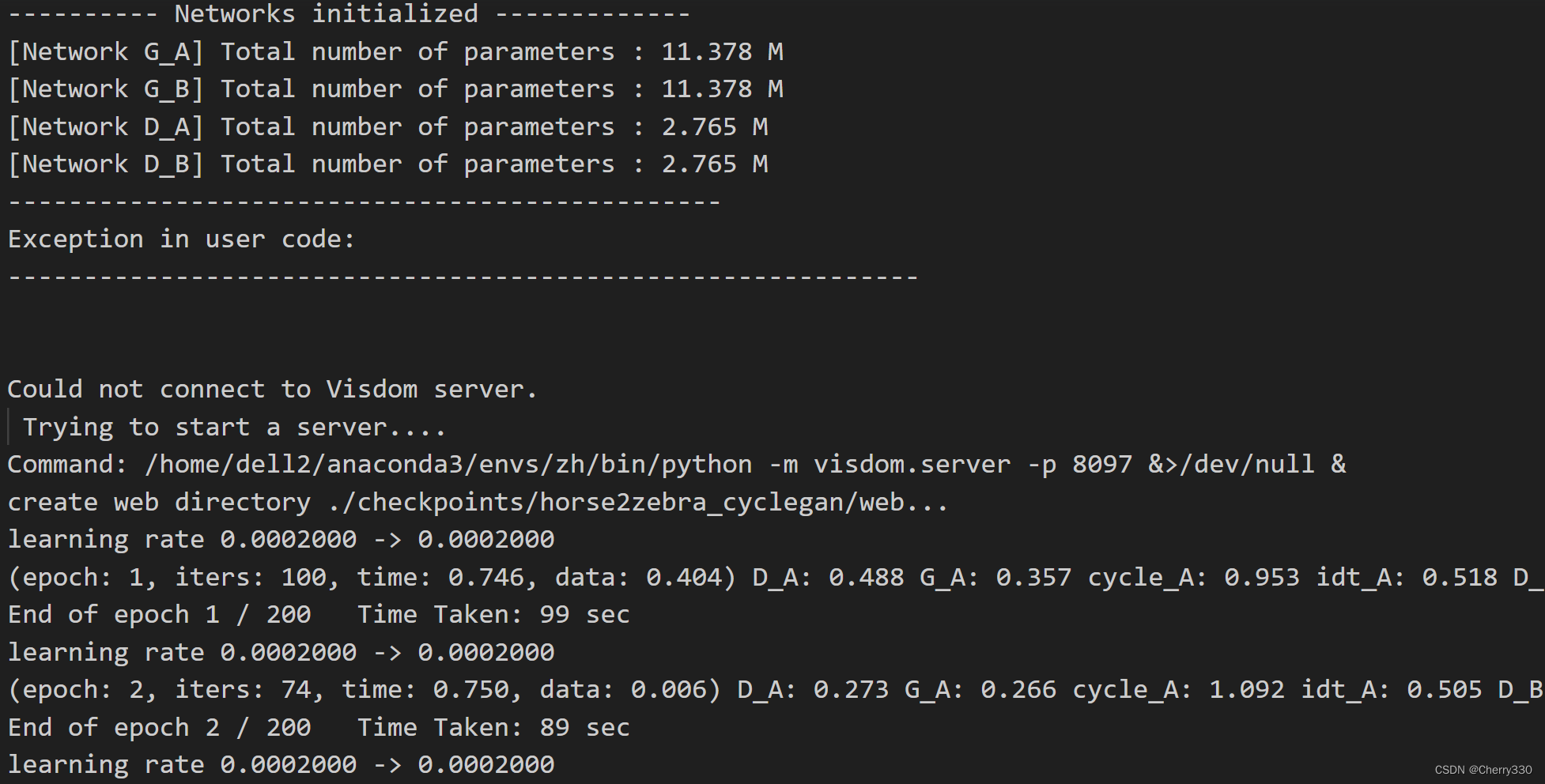
图7 训练结果
如果出现报错,大家根据报的错进行修改,一般来说,应该只会出现某个库没有下载的问题,这种情况大家用“pip install xxx”缺哪个库补哪个库就行。
第四步,进行测试!训练结束之后就可以开始测试了,测试用的是我们文件夹testA中的数据。
在checkpoints文件夹的horse2zebra_cyclegan文件夹中存有所有的权重。我们找到latest_net_D_A.pth。如图8。

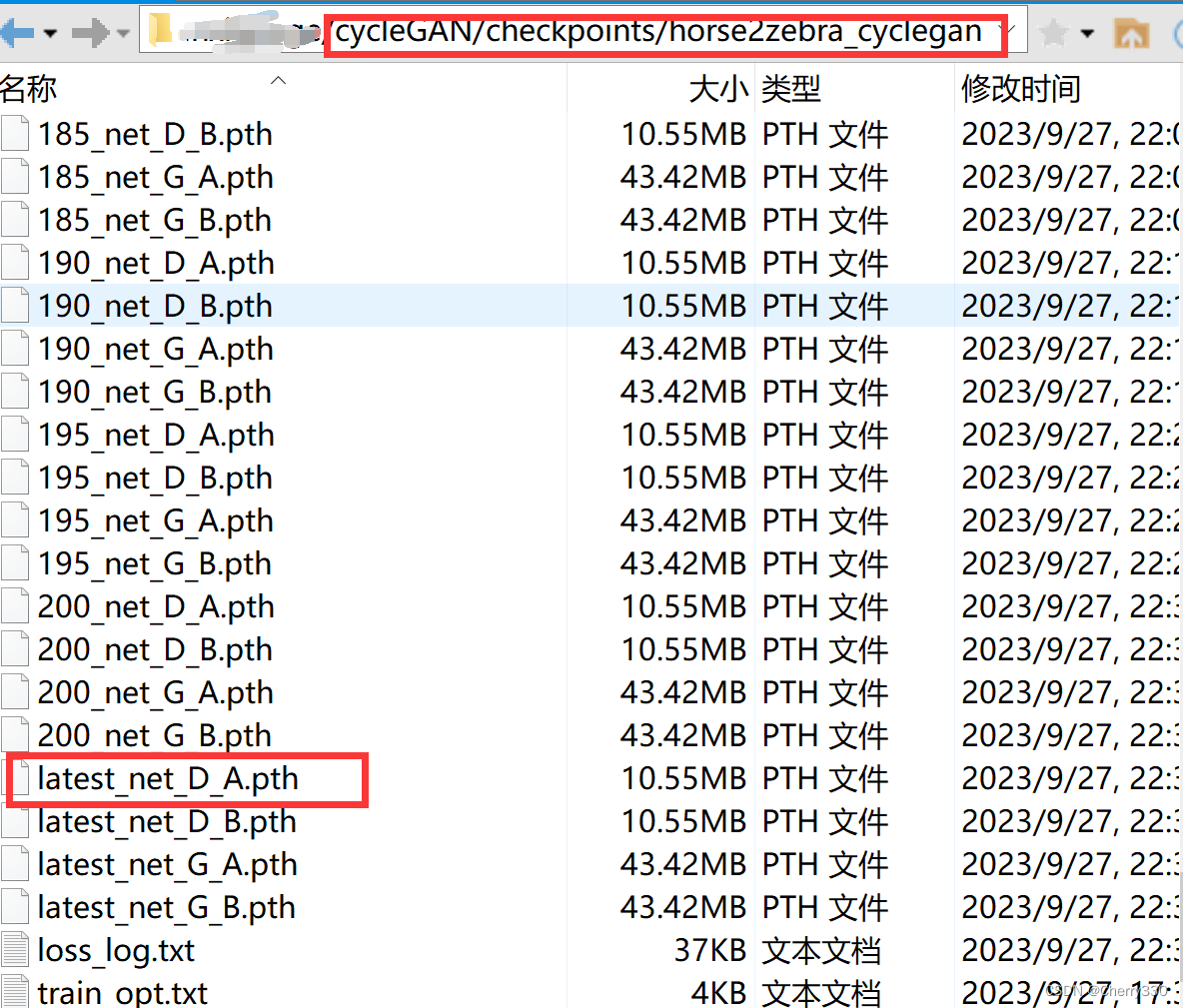
图8 训练权重位置
我们在checkpoints文件夹中创建一个horse2zebra_pretrained文件夹,并将latest_G_A.pth复制到horse2zebra_pretrained文件夹中,并改名为latest_net_G.pth。如图9。
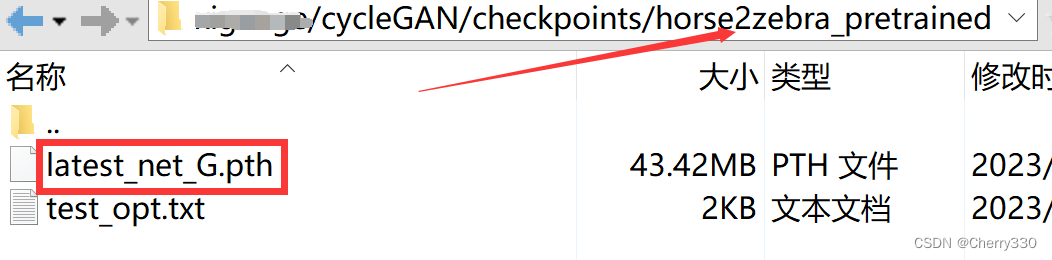
图9 测试权重准备
在命令行输入下述代码,即可开始测试!
nohup python test.py --dataroot datasets/horse2zebra/testA --name horse2zebra_pretrained --model test --no_dropout &测试的结果会保存在reults文件夹中。如图10。
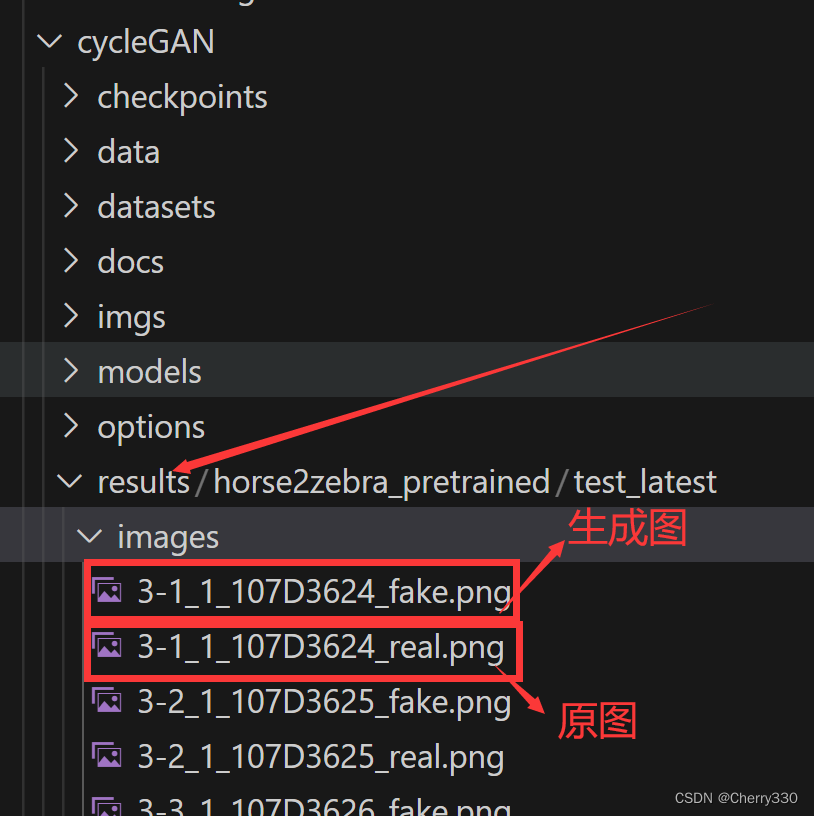
图10 测试结果位置
测试结果如图11。
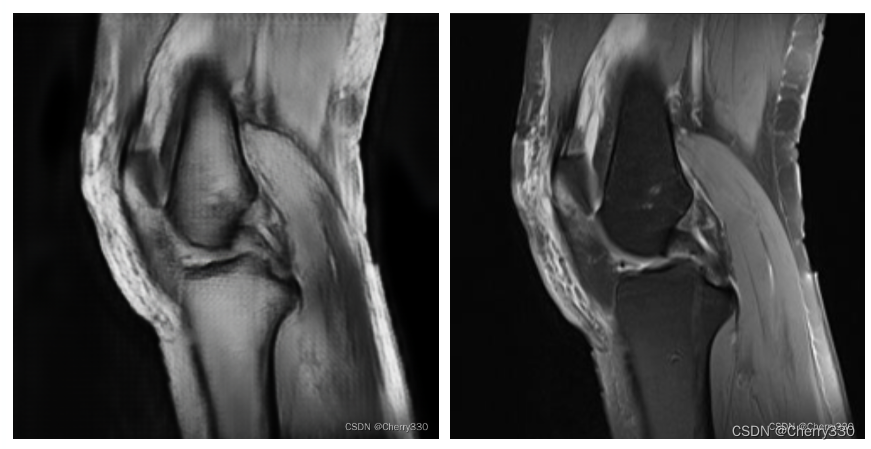
图11 测试结果(左:生成图,右:原图)
这样,整个训练和测试就结束啦!
CycleGAN可以应用于很多领域的图像生成,风格迁移,甚至是AI画图。大家可以用自己的数据集做一下,说不定效果会很不错哦~
最后附上相关资源(代码+论文),希望对各位小伙伴有所帮助鸭!
风格变换用CycleGAN跑自己的数据集code+训练教程+论文资源-CSDN文库
大家如果有什么好的想法也可以发在评论区,大家一起讨论,一起学习鸭!祝大家科研愉快,中秋快乐呀~



















 6523
6523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











