






这次我们要讲的主要是Blending 和Bagging。
我们可不同的方式来得到不同的g。如果我们综合一下这些g,那么我们很可能会得到一个更好的g。
Blending:
形象地说,就是类似于投票,每个g有着一些票,看大家投票的结果决定最后的g。
Uniform Blending:
每个g都只有1票。
Classification:
Binary Classification:
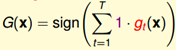
少数服从多数,感觉挺直白的。
Multiclass Classification:
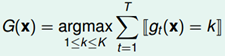
Regression:
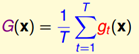
也就是g的平均值,可能会比单一的g要好。
下面是证明平均的g,会比单一的g好:

也就是说平均得到的g会比较好。
一个算法的好坏,通常是由方差和偏差决定的。我们利用取平均的办法获得g,减少了方差,获得了比较好的稳定性。
Linear Blending:
每个人可以有不同票数。
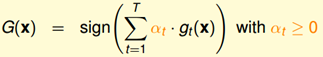


把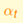
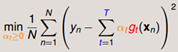
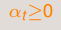
我们发现,其实目标函数特别像我们之前学过的Linear Regression+Transform的目标函数。
只不过多了一个

对于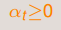
如果求出来的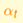
所以实际工作里,我们不用constraints,如下图。

Linear Blending versus Selection
让我们回忆一下Selection:
- 几个模型跑,选取E_in最小的那个。也就是每个模型里,选取最好的g,再在最好的g中间选取一个最好的,也就是选到了best of best,那么我们会付出比较高的复杂度代价,所以一般我们会用validation。
-
Linear blending可以通过设置a来选到 best of best。
- 由于linear blending的结果是包含best of best的,所以linear blending付出的复杂度代价更大。
- 我们要最小化E_val而不是E_in。
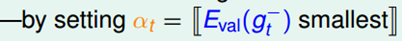
Any Blending:
也就是算 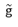

Any Blending非常powerful, 我们需要小心overfit.
总结:
我们可以从不同的model、不同的model parameter、不同的算法随机性(比如PLA)、数据的随机性来得到不同的g。
Blending就是在我们得到不同的g之后,综合不同的g来获得表现更好的g。
Blending在实际上很有用,只不过我们要付出模型复杂度上的代价,还有计算复杂度。
Bagging
维基百科上的解释挺好的了,主要就是一个Bootstrap。
















 3272
3272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









