






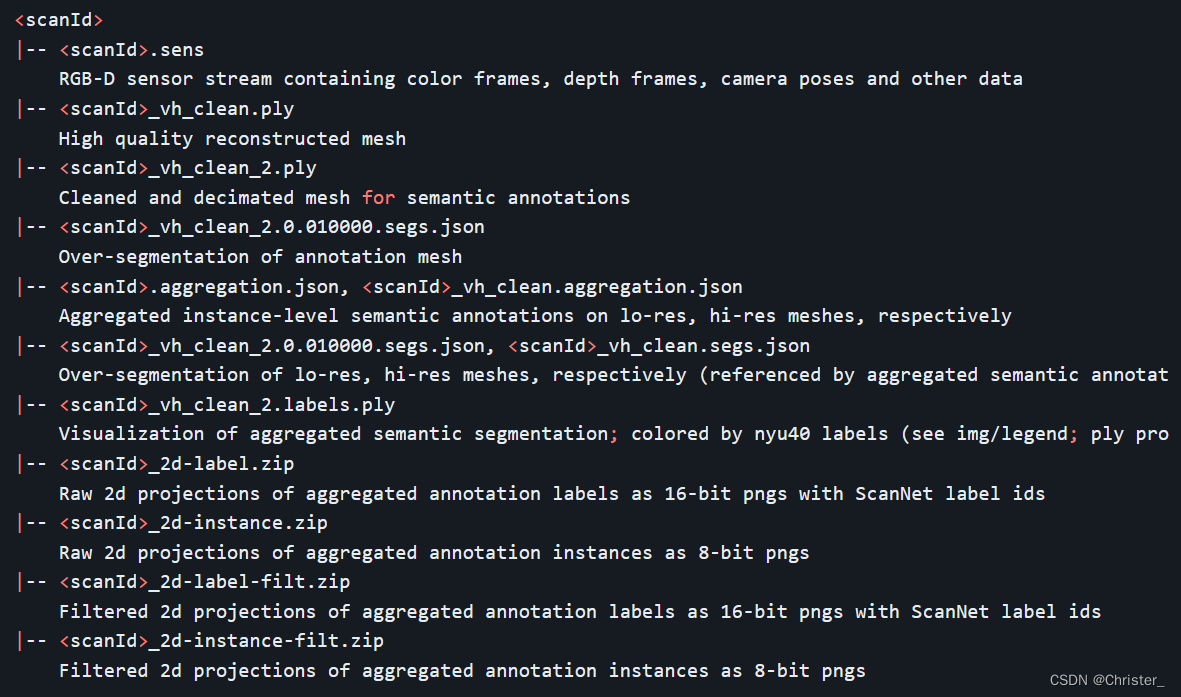
相较于上面完整的scnnet数据集,该网盘链接仅包括以下尾缀的文件,希望注意
***_vh_clean_2.ply
***_vh_clean_2.labels.ply
***_vh_clean_2.0.010000.segs.json
***.aggregation.json
网盘链接:
链接:https://pan.baidu.com/s/1aURvd6s1q3e9IhtE1xRsFw?pwd=v53n
提取码:v53n
--来自百度网盘超级会员V3的分享
转载 scannet 下载脚本,2024.3.16 依旧可用,可选择下载文件类型\场景ID:
另外,在复现 PointGroup: Dual-Set Point Grouping for 3D Instance Segmentation (CVPR2020) 时,写了一个关于 data preparation 过程中根据 train.txt 移动数据的脚本,仅供参考
import os
import shutil
def copyfile(srcfile, dstpath): # 复制函数
if not os.path.isfile(srcfile):
print ("%s not exist!"%(srcfile))
else:
fpath,fname=os.path.split(srcfile) # 分离文件名和路径
if not os.path.exists(dstpath):
os.makedirs(dstpath)
dstpath = os.path.join(dstpath, fname)
shutil.copy(srcfile, dstpath) # 复制文件
print ("copy %s -> %s"%(srcfile, dstpath))
def mov(t_data, t_files, base_dir):
for t_file in t_files:
with open(t_data+'.txt',"r") as f:
lines = f.readlines()
for line in lines:
id = line.strip('\n')
scrfile = os.path.join(base_dir, id, id + t_file)
dstpath = os.path.join(target_dir, t_data)
copyfile(srcfile=scrfile, dstpath=dstpath)
target_dir = '/data0/chenxiang/PointGroup/dataset/scannetv2'
t_data = 'train'
t_files = ['_vh_clean_2.ply', '_vh_clean_2.labels.ply',
'_vh_clean_2.0.010000.segs.json', '.aggregation.json']
base_dir = '/data0/chenxiang/data/scans'
mov(t_data=t_data, t_files=t_files, base_dir=base_dir)
t_data = 'val'
t_files = ['_vh_clean_2.ply', '_vh_clean_2.labels.ply',
'_vh_clean_2.0.010000.segs.json', '.aggregation.json']
base_dir = '/data0/chenxiang/data/scans'
mov(t_data=t_data, t_files=t_files, base_dir=base_dir)
t_data = 'test'
t_files = ['_vh_clean_2.ply']
base_dir = '/data0/chenxiang/data/scans_test'
mov(t_data=t_data, t_files=t_files, base_dir=base_dir)













 1327
1327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









