






 本文详细介绍了ScanNetv2数据集中的四个核心文件:_vh_clean_2.ply、_vh_clean_2.0.010000.segs.json、.aggregation.json和_vh_clean_2.labels.ply的功能及使用方法。解析了如何从这些文件中提取点云数据、点云标签等关键信息。
本文详细介绍了ScanNetv2数据集中的四个核心文件:_vh_clean_2.ply、_vh_clean_2.0.010000.segs.json、.aggregation.json和_vh_clean_2.labels.ply的功能及使用方法。解析了如何从这些文件中提取点云数据、点云标签等关键信息。
以下文件中包含ScanNet点云数据
< scanId >_vh_clean_2.ply
< scanId >_vh_clean_2.labels.ply
< scanId >.aggregation.json
< scanId >_vh_clean_2.0.010000.segs.json
可用官方提供的python文件选择下载获取。网上很多内容只包含了点云数据下载和提取教程,没有对这几个文件做进一步详细的解读。
_vh_clean_2.ply
|—_vh_clean_2.ply
|—scans
|—scene0000_00
|—scene0000_00_vh_clean_2.ply
|—scene0000_01
|—scene0000_01_vh_clean_2.ply
… …
|—scans_test
|—scene0707_00
|—scene0707_00_vh_clean_2.ply
|—scene0708_00
|—scene0708_00_vh_clean_2.ply
… …
|—task
… …
_vh_clean_2.ply目录中ply文件就是ScanNetv2数据集的mesh数据,解析ply文件得到的每个点包含7个值 (x,y,z,r,g,b,a), 坐标 (x,y,z),颜色 (r,g,b),透明度(a均为255)。

提取ply中的(x,y,z,r,g,b)即为所需点云数据。除了每个点的信息外,还包括每个表面所连接的三个点 (p1,p2,p3)。
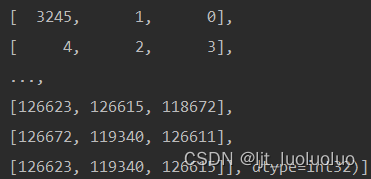
_vh_clean_2.0.010000.segs.json
|—_vh_clean_2.0.010000.segs.json
|—scans
|—scene0000_00
|—scene0000_00_vh_clean_2.0.010000.segs.json
|—scene0000_01
|—scene0000_01_vh_clean_2.0.010000.segs.json
… …
|—scans_test
|—scene0707_00(empty)
|—scene0708_00(empty)
… …
|—task
… …
|—scannetv2-labels.combined.tsv
_vh_clean_2.0.010000.segs.json中的json文件包含对应点云数据中每个点的标号,测试数据scans_test文件夹下无内容(测试数据用于打榜,不提供标注)
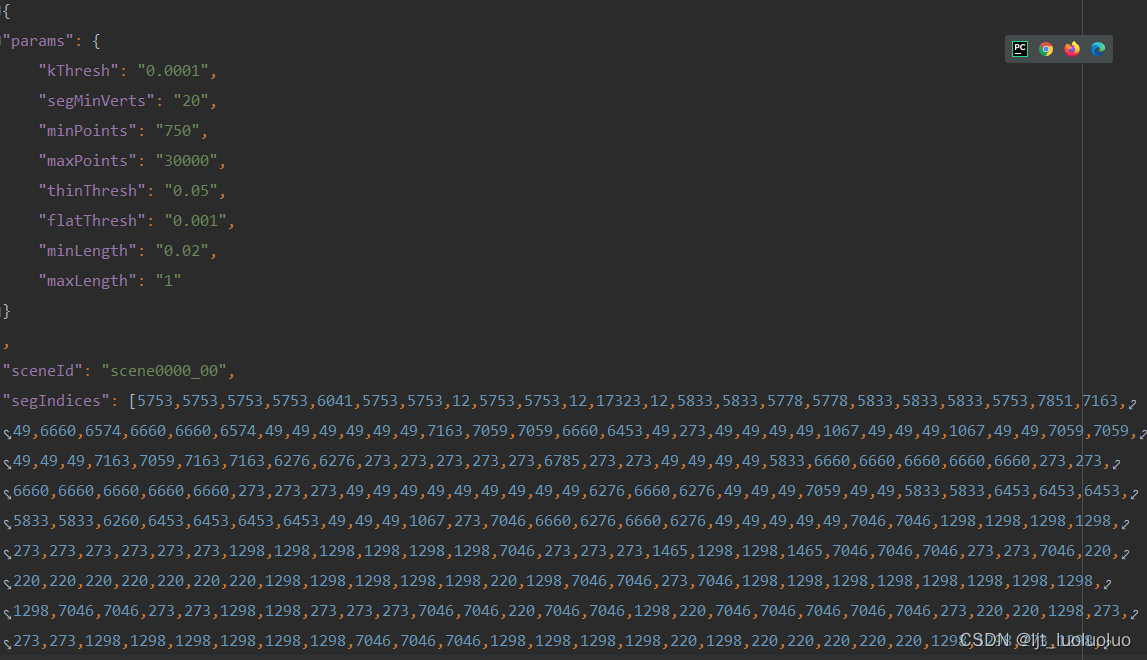
"segIndices"中的所有标号数量与对应点云的点数目相同,相同的标号指向同一个原始类别。与 .aggregation.json中的数据匹配可以划分出每个点的标签
.aggregation.json
|—.aggregation.json
|—scans
|—scene0000_00
|—scene0000_00.aggregation.json
|—scene0000_01
|—scene0000_01.aggregation.json
… …
|—scans_test
|—scene0707_00(empty)
|—scene0708_00(empty)
… …
|—task
… …
|—scannetv2-labels.combined.tsv
.aggregation包含每个点的类别信息,scans_test文件夹同样为空文件夹(用于打榜),json文件中有每个点的类别信息
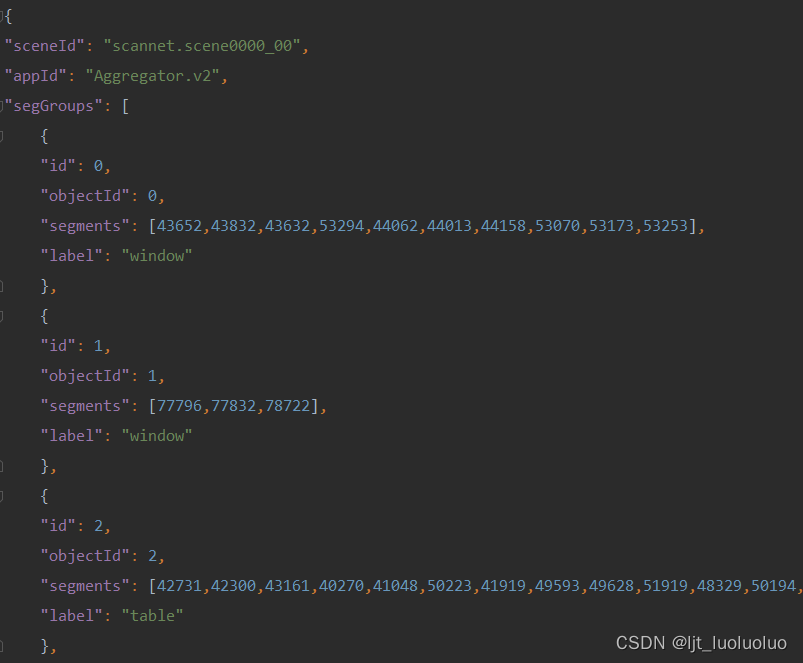
segGroup中的"segments"的数字为点云的标号(与_vh_clean_2.0.010000.segs.json中数据匹配),"label"表示原始(raw)类别。segments中所有标号指向的点都属于label类别(raw),以下是整个数据中的原始类别集合。此外,“id” 提供的序号可用于区分同一类别的不同实例
 .aggregation.json一级目录下的tsv文件为原始(raw)类别到各种标签的对应关系
.aggregation.json一级目录下的tsv文件为原始(raw)类别到各种标签的对应关系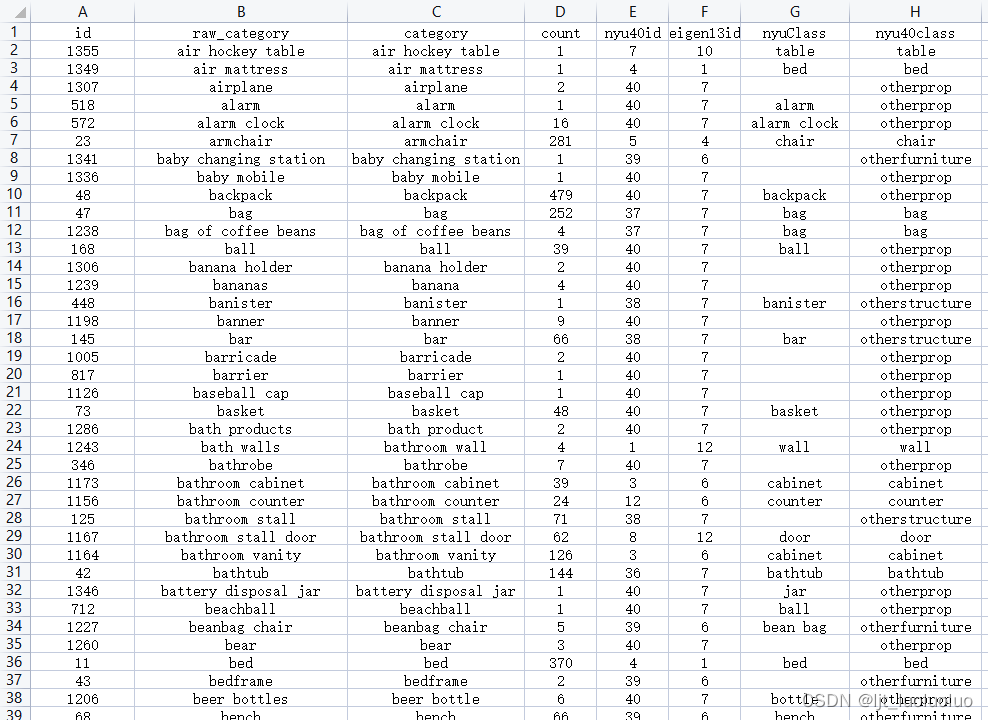
_vh_clean_2.labels.ply
|—_vh_clean_2.labels.ply
|—scans
|—scene0000_00
|—scene0000_00_vh_clean_2.labels.ply
|—scene0000_01
|—scene0000_01_vh_clean_2.labels.ply
… …
|—scans_test
|—scene0707_00(empty)
|—scene0708_00(empty)
… …
|—task
… …
|—scannetv2-labels.combined.tsv
_vh_clean_2.label.ply提供的是点云中每个点的nyu40的标签。它与 .aggregation.json不之处在于, _vh_clean_2.label.ply只能提供语义标签,无法做实例的分割。
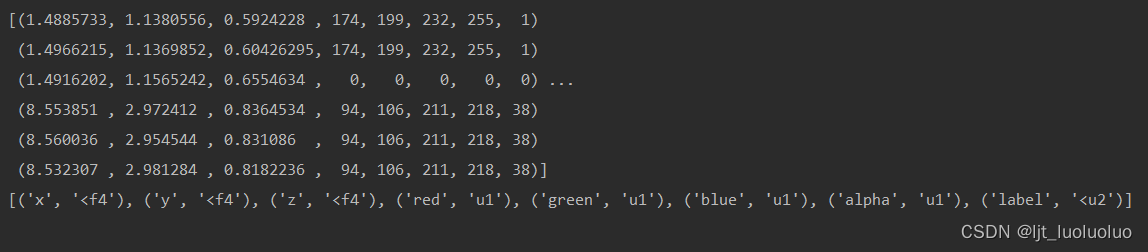
scans目录下的ply文件与 _vh_clean_2.ply中的格式基本相同,不同在于多了一个标签直接对应nyu40标签并且透明度a不再全是255。除此之外,相同标签的点也用相同颜色进行了标注。表面连接点与 _vh_clean_2.ply完全一致
亿点细节:
1.四组数据目录下的tsv文件是完全相同的;
2._vh_clean_2.label.ply标签为0的点属于未标注的点,nyu40中只有1~40;
3._vh_clean_2.0.010000.segs.json中有的点在 .aggregation.json中找不到对应原始类别,与上一条相同都属于未标注的点。
(欢迎讨论,感谢指正)

















 2917
2917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









