






- 底层原理
Hash 散列算法,从key映射到index index = Hash(“key”)
Map 接口中键和值一一映射. 可以通过键来获取值。
put():
先计算出插入的index位置
当index重复,就用链表,采用头插法(jdk1.7前)
get()
根据key找value,得到对应的index
查看头节点,如果不是我们找到key,则接着找next
为啥采用头插法,
是因为HashMap的发明者任务,后插入的Entry被查找的可能性更大。
尾部插入,首先需要遍历到尾部。
- HashMap默认的初始长度是多少?为什么这样规定
16,每次自动扩展,或者手动初始化时,必须是2的幂。
选择16是为了服务于从key映射到index的Hash算法。为了让Hash算法均匀分布。
- 高并发情况下,为什么HashMap可能会出现死锁
key的位置被占用
因为HashMap没加线程锁!保证了效率
Rehash是HashMap在扩容时候的一个步骤
1.Hashmap在插入元素过多的时候需要进行Resize,Resize的条件是
HashMap.Size >= Capacity * LoadFactor。
2.Hashmap的Resize包含扩容和ReHash两个步骤,ReHash在并发的情况下可能会形成链表环。
在高并发场景下,我们通常用另一个集合类ConcurrentHashMap。这个集合类兼顾了线程安全和性能。
- Java8中,HashMap的结构有什么样的优化
加入了红黑树,当链表长度为8时,转为红黑树。
红黑树:
二叉查找树(二叉排序树):
1.左子树上所有结点的值均小于或等于它的根结点的值。
2.右子树上所有结点的值均大于或等于它的根结点的值。
3.左、右子树也分别为二叉排序树。
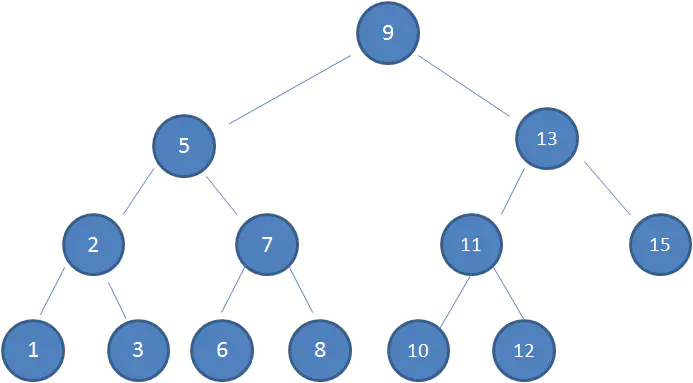
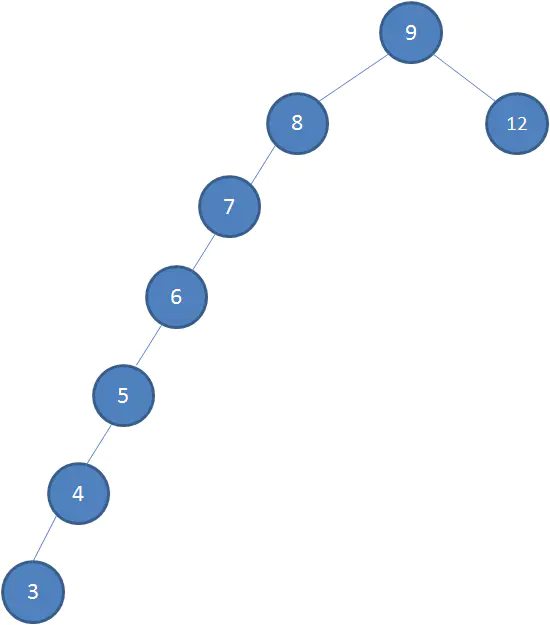
利用了二分法,容易查找,最大查找次数等于二叉查找树的高度。但是插入的时候:
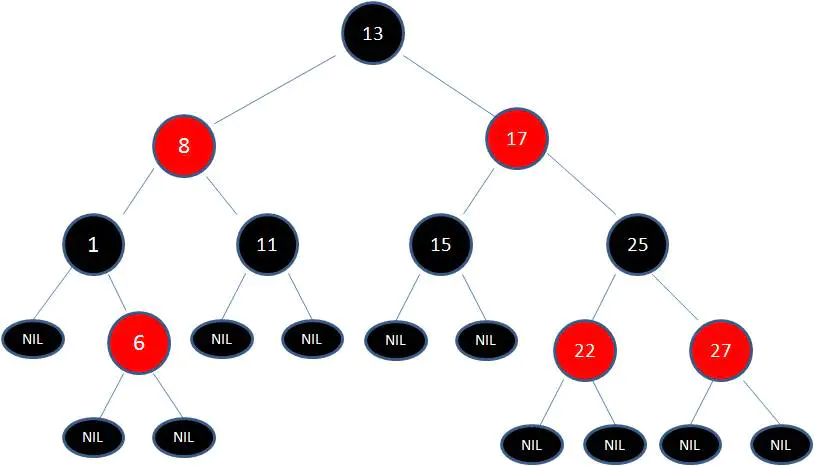
红黑树:是一种自平衡的二叉查找树。从根到叶子的最长路径不会超过最短路径的2倍。除了符合二叉查找树的基本特征外,它还有下列特性:
1.节点是红色或黑色。
2.根节点是黑色。
3.每个叶子节点都是黑色的空节点(NIL节点)。
4 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
5.从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
特性和优势
什么情况下需要变色
什么情况下需要旋转(左旋转,右旋转)
是在链表最后插入的,不仅仅是谁先取的问题,map的key是唯一的,是要顺着链表比较的。















 1832
1832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









