






目录
5.1、把master虚拟机上安装的spark分发给slave1虚拟机
5.2、将master虚拟机上环境变量配置文件分发到slave1虚拟机
6.1、把master虚拟机上安装的spark分发给slave2虚拟机
6.2、将master虚拟机上环境变量配置文件分发到slave2虚拟机
一、准备工作
-
由于Spark仅仅是一种计算框架,不负责数据的存储和管理,因此,通常都会将Spark和Hadoop进行统一部署,由Hadoop中的HDFS、HBase等组件负责数据的存储管理,Spark负责数据计算。
-
安装Spark集群前,需要安装Hadoop环境
| 软件 | 版本 |
| Linux系统 | CentOS7.9版本 |
| Hadoop | 3.3.4版本 |
| JDK | 1.8版本 (jdk8u231) |
| Spark | 3.3.2版本 |
二、了解Spark的部署模式
1、Standalone模式
- Standalone模式被称为集群单机模式。该模式下,Spark集群架构为主从模式,即一台Master节点与多台Slave节点,Slave节点启动的进程名称为Worker,存在单点故障的问题。
2、Mesos模式
- Mesos模式被称为Spark on Mesos模式。Mesos是一款资源调度管理系统,为Spark提供服务,由于Spark与Mesos存在密切的关系,因此在设计Spark框架时充分考虑到对Mesos的集成。
3、Yarn模式
- Yarn模式被称为Spark on Yarn模式,即把Spark作为一个客户端,将作业提交给Yarn服务。由于在生产环境中,很多时候都要与Hadoop使用同一个集群,因此采用Yarn来管理资源调度,可以提高资源利用率。
三、搭建Spark单机版环境
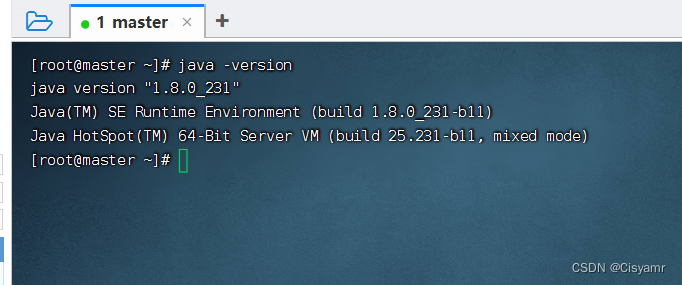
1、查看jdk版本
2、下载、安装与配置Spark
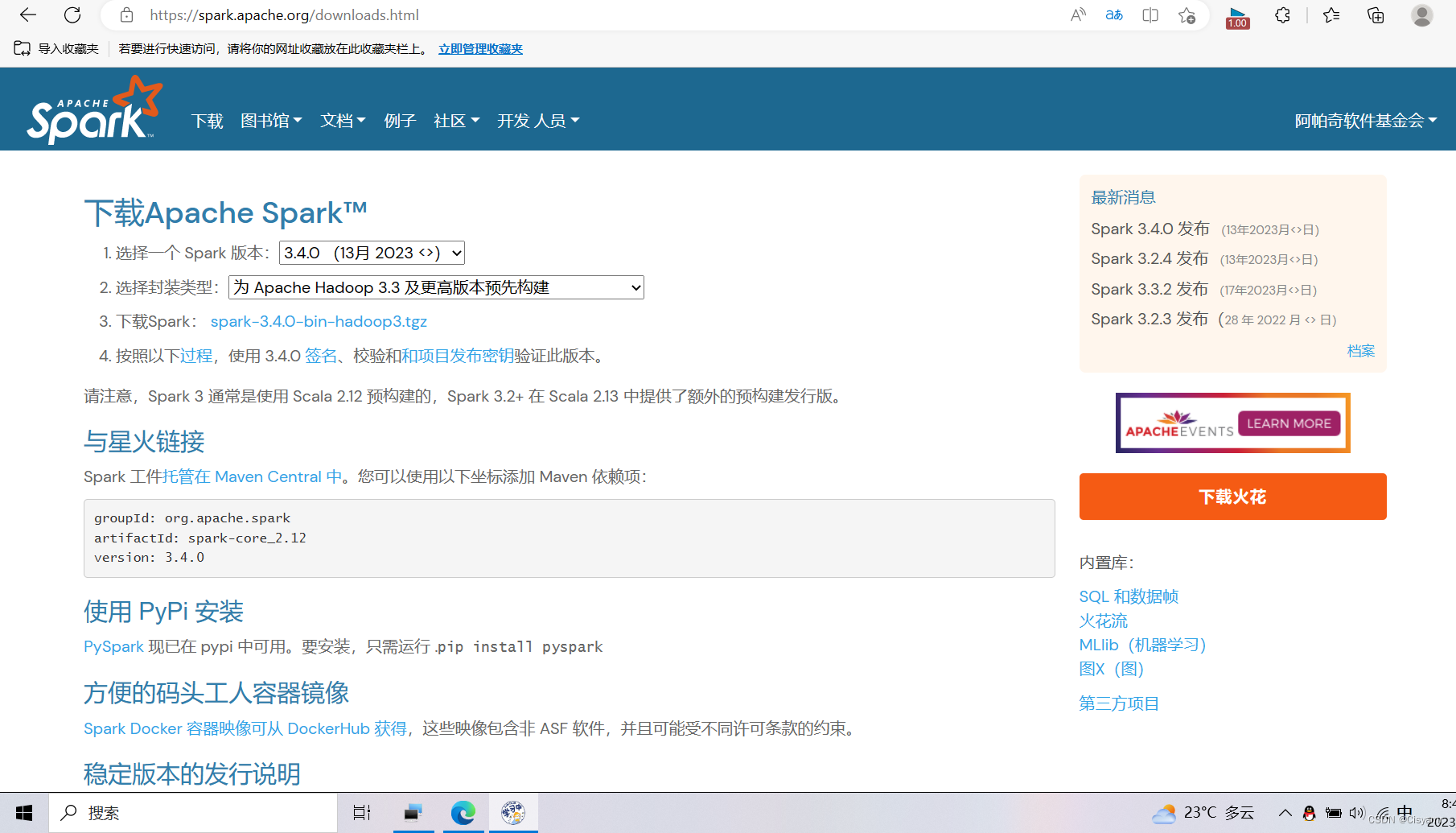
- 下载链接:Apache Downloads
- 下载到本地
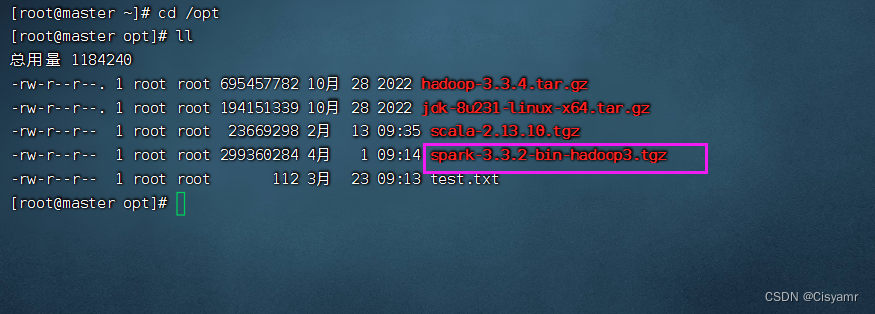
3、将Spark安装包上传到虚拟机
- 将Spark安装包上传到master虚拟机
/opt目录
4、将Spark安装包解压到指定目录
- 命令:tar -zxvf spark-3.3.2-bin-hadoop3.tgz -C /usr/local
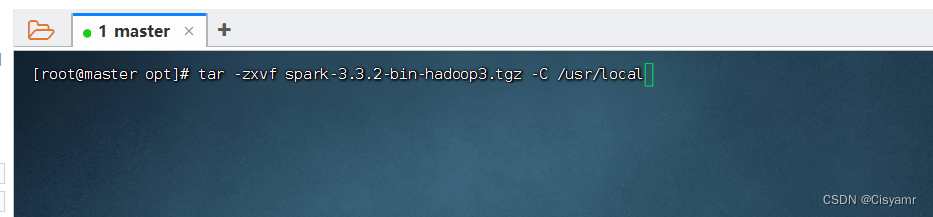
- 查看解压之后的spark目录
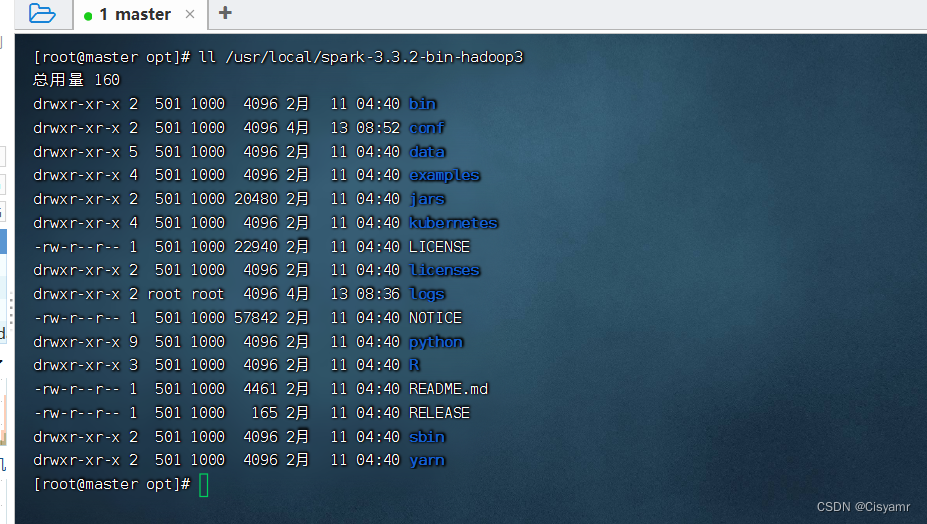
5、配置Spark环境变量
- 执行:
vim /etc/profile
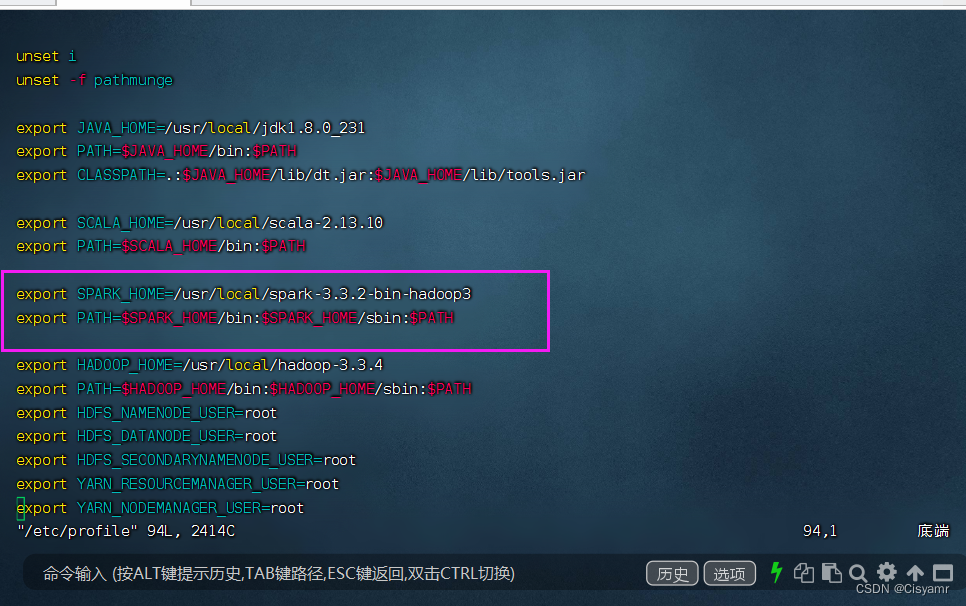
export SPARK_HOME=/usr/local/spark-3.3.2-bin-hadoop3
export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
- 存盘退出,执行命令:
source /etc/profile,让环境配置生效
6、使用Spark单机版环境
6.1、使用SparkPi来计算Pi的值
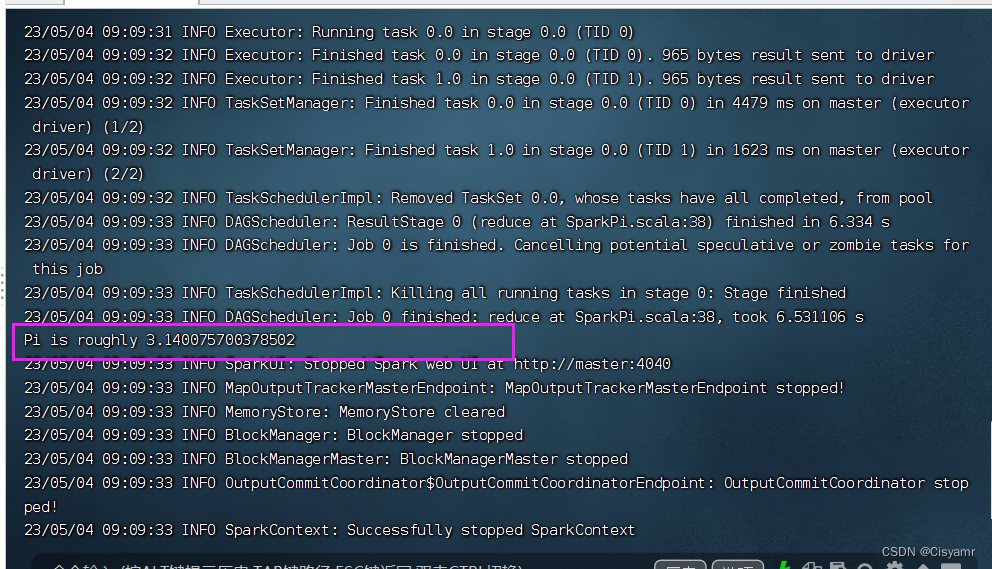
- 执行命令:
run-example SparkPi 2(其中参数2是指两个并行度) - 查看计算结果:
Pi is roughly 3.140075700378502
6.2、使用Scala版本Spark-Shell
- Spark-Shell是一个强大的交互式数据分析工具,初学者可以很好的使用它来学习相关API,用户可以在命令行下使用Scala编写Spark程序,并且每当输入一条语句,Spark-Shell就会立即执行语句并返回结果,这就是我们所说的REPL(Read-Eval-Print Loop,交互式解释器),Spark-Shell支持Scala和Python。
- 命令格式:spark-shell --master <master-url>
- --master表示指定当前连接的Master节点
- <master-url>用于指定Spark的运行模式
| 参数名称 | 参数名称 |
| local | 使用一个Worker线程本地化运行Spark |
| local[*] | 本地运行Spark,工作线程数量与本机CPU逻辑核心数量相同 |
| local[N] | 使用N个Worker线程本地化运行Spark |
| spark://host:port | Standalone模式下,连接到指定的Spark集群,默认端口7077 |
| yarn-client | 以客户端模式连接Yarn集群,集群位置可在HADOOP_CONF_DIR环境变量中配置 |
| yarn-cluster | 以集群模式连接Yarn集群,集群位置可在HADOOP_CONF_DIR 环境变量中配置 |
| mesos://host:port | 连接到指定的Mesos集群。默认接口是5050 |
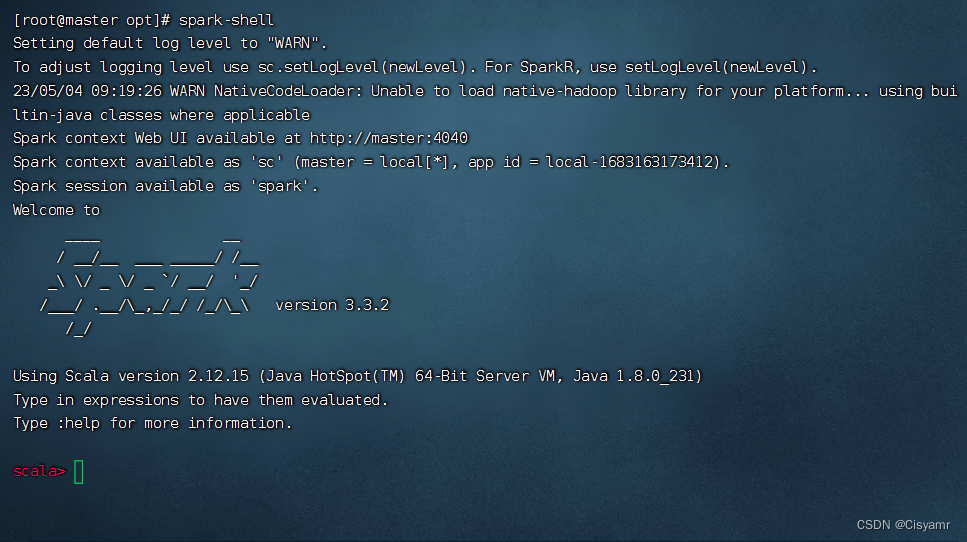
- 执行
spark-shell命令,相当于执行spark-shell --master local[*]命令,启动Scala版的Spark-Shell
- 访问Spark的Web UI界面 -
http://192.168.219.75:4040
-
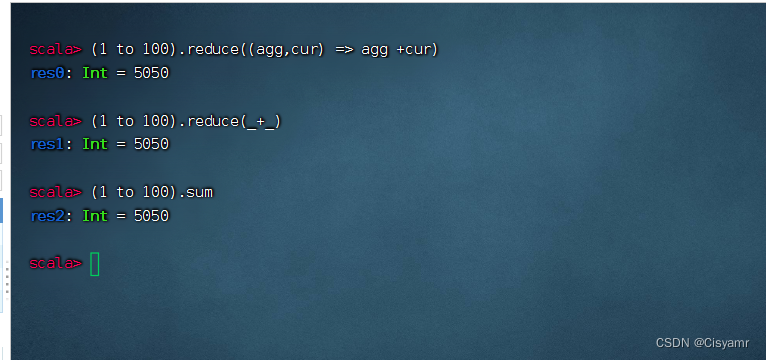
注意:Spark 3.3.2使用的Scala版本其实是2.12.15
-
计算1 + 2 + 3 + …… + 100
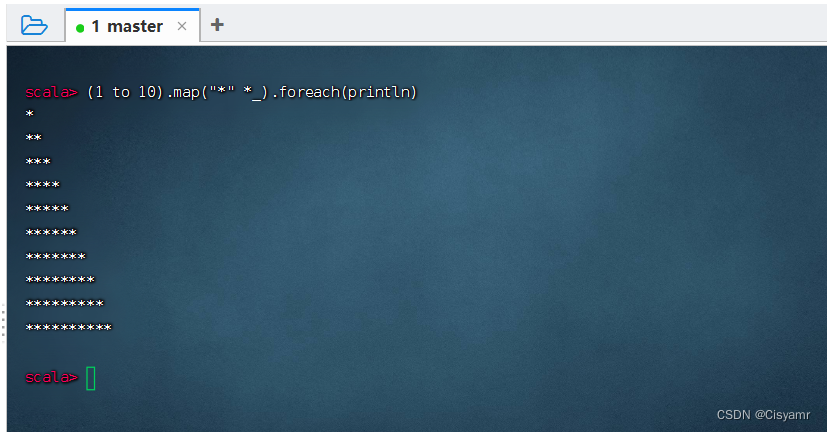
- 输出字符直角三角形
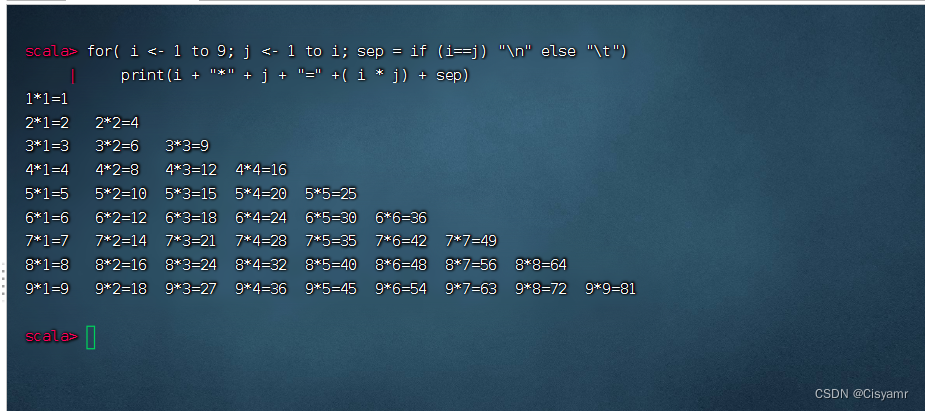
- 打印九九表
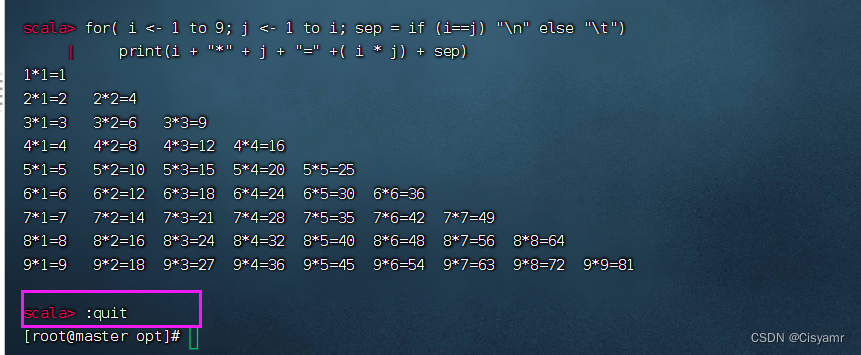
- 执行
:quit命令,退出Spark Shell交互式环境
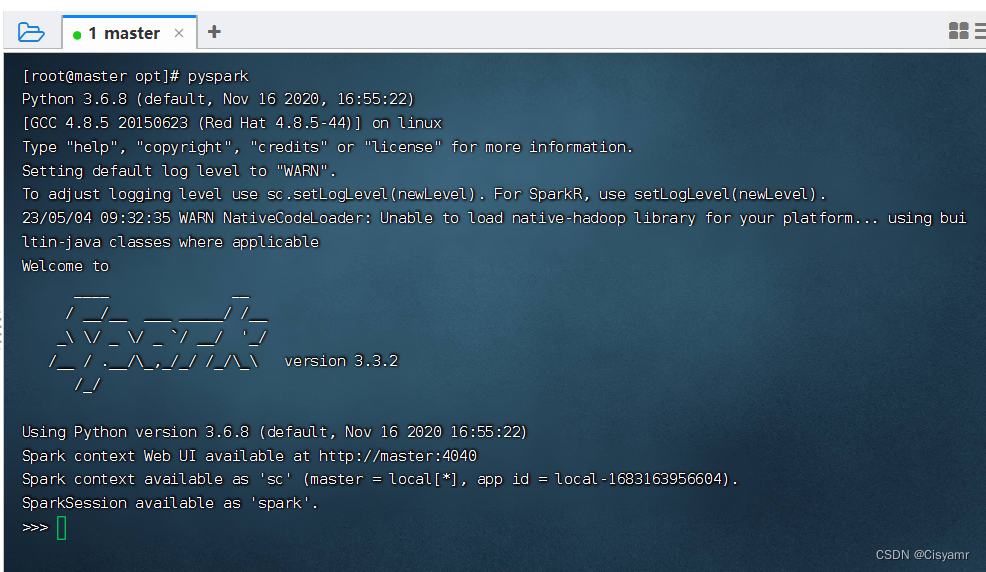
6.3、使用Python版本Spark-Shell
- 执行
pyspark命令启动Python版的Spark-Shell - 如果显示没有这个文件或目录,执行命令:yum -y install python3 进行安装
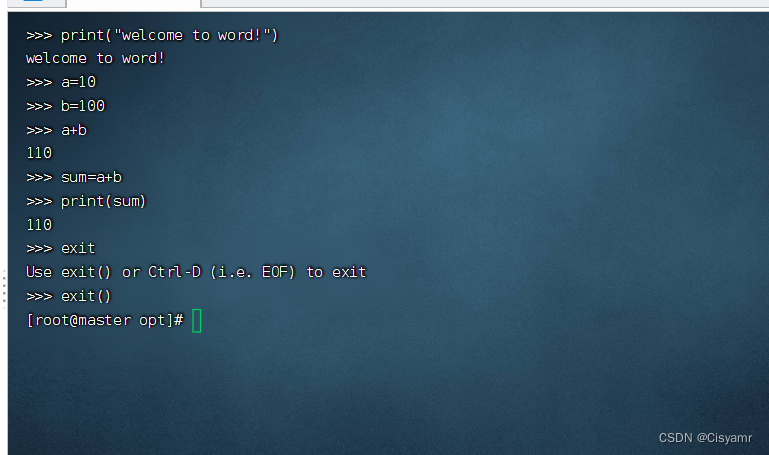
- 输出一条信息,进行加法运算,然后退出交互式环境
 6.4、初识弹性分布式数据集RDD
6.4、初识弹性分布式数据集RDD
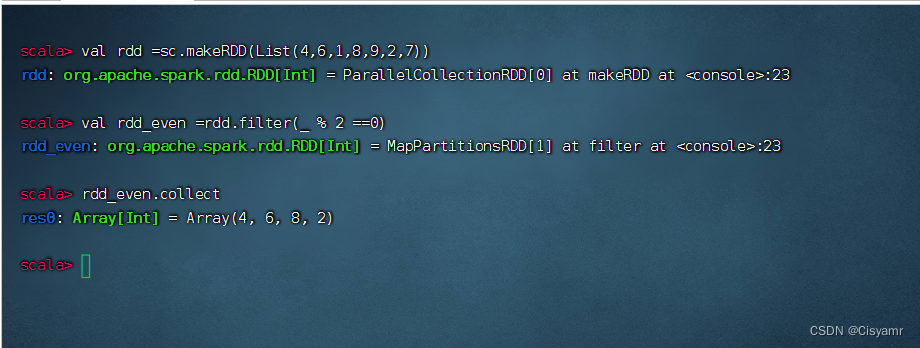
- Spark 中的RDD (Resilient Distributed Dataset) 就是一个不可变的分布式对象集合。每个RDD 都被分为多个分区,这些分区运行在集群中的不同节点上。RDD 可以包含Python、Java、Scala 中任意类型的对象,甚至可以包含用户自定义的对象。用户可以使用两种方法创建RDD:读取一个外部数据集,或在驱动器程序里分发驱动器程序中的对象集合(比如list 和set)。
- 演示利用集合创建RDD
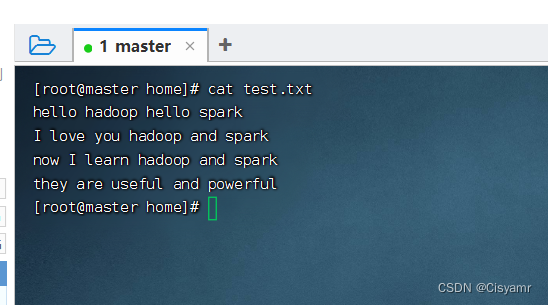
- 在
/home目录下创建test.txt文件
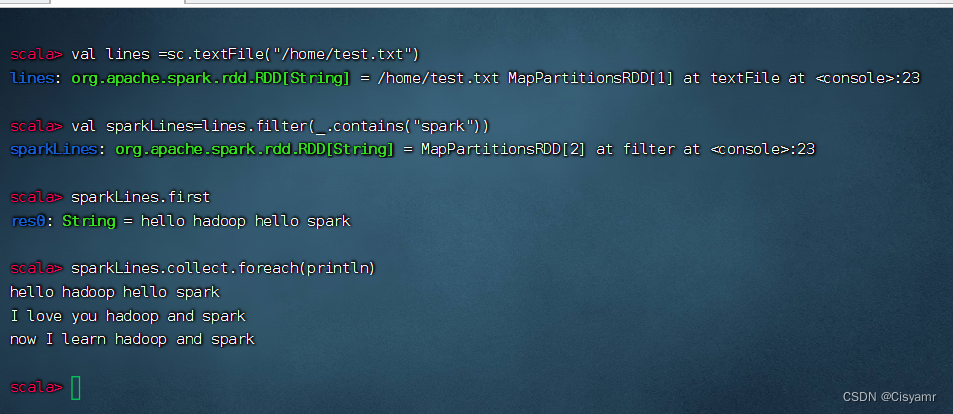
- 利用Spark RDD实现词频统计
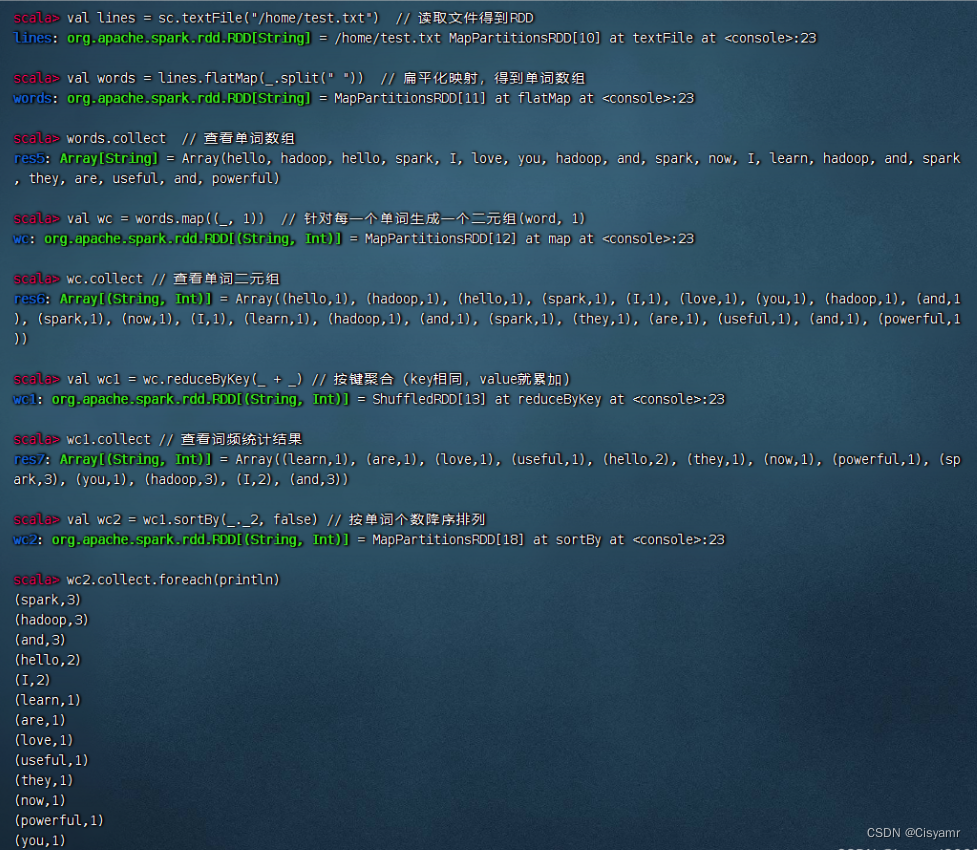
四、搭建Spark Standalone集群
1、Spark Standalone架构
- Spark Standalone模式为经典的Master/Slave(主/从)架构,资源调度是Spark自己实现的。在Standalone模式中,根据应用程序提交的方式不同,Driver(主控进程)在集群中的位置也有所不同。应用程序的提交方式主要有两种:client和cluster,默认是client。可以在向Spark集群提交应用程序时使用--deploy-mode参数指定提交方式。
1.1、client提交方式
- 集群的主节点称为Master节点,在集群启动时会在主节点启动一个名为Master的守护进程,类似YARN集群的ResourceManager;从节点称为Worker节点,在集群启动时会在各个从节点上启动一个名为Worker的守护进程,类似YARN集群的NodeManager。
- Spark在执行应用程序的过程中会启动Driver和Executor两种JVM进程。
- Driver为主控进程,负责执行应用程序的main()方法,创建SparkContext对象(负责与Spark集群进行交互),提交Spark作业,并将作业转化为Task(一个作业由多个Task任务组成),然后在各个Executor进程间对Task进行调度和监控。通常用SparkContext代表Driver。在上图的架构中,Spark会在客户端启动一个名为SparkSubmit的进程,Driver程序则运行于该进程。
- Executor为应用程序运行在Worker节点上的一个进程,由Worker进程启动,负责执行具体的Task,并存储数据在内存或磁盘上。每个应用程序都有各自独立的一个或多个Executor进程。在Spark Standalone模式和Spark on YARN模式中,Executor进程的名称为CoarseGrainedExecutorBackend,类似运行MapReduce程序所产生的YarnChild进程,并且同时与Worker、Driver都有通信。
1.2、cluster提交方式
- Standalone cluster提交方式提交应用程序后,客户端仍然会产生一个名为SparkSubmit的进程,但是该进程会在应用程序提交给集群之后就立即退出。当应用程序运行时,Master会在集群中选择一个Worker进程启动一个名为DriverWrapper的子进程,该子进程即为Driver进程,所起的作用相当于YARN集群的ApplicationMaster角色,类似MapReduce程序运行时所产生的MRAppMaster进程。
2、Spark集群拓扑
- 一个主节点,两个从节点
- Spark Standalone模式的集群搭建需要在集群的每个节点都安装Spark,集群角色分配如下表所示。
| 节点 | 角色 |
| master | Master |
| slave1 | Worker |
| slave2 | Worker |
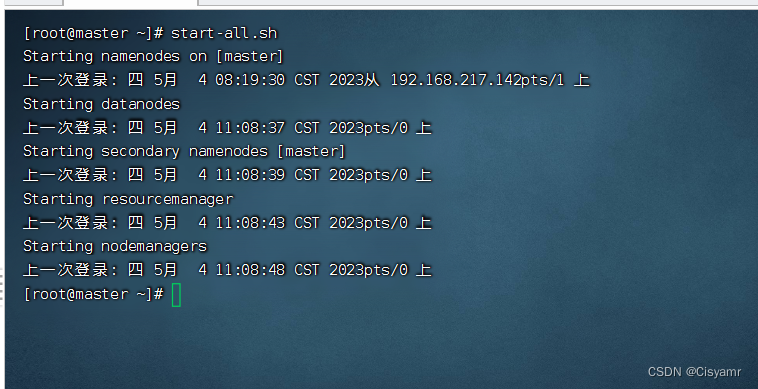
3、前提条件:安装配置了分布式Hadoop环境
- 启动hadoop集群
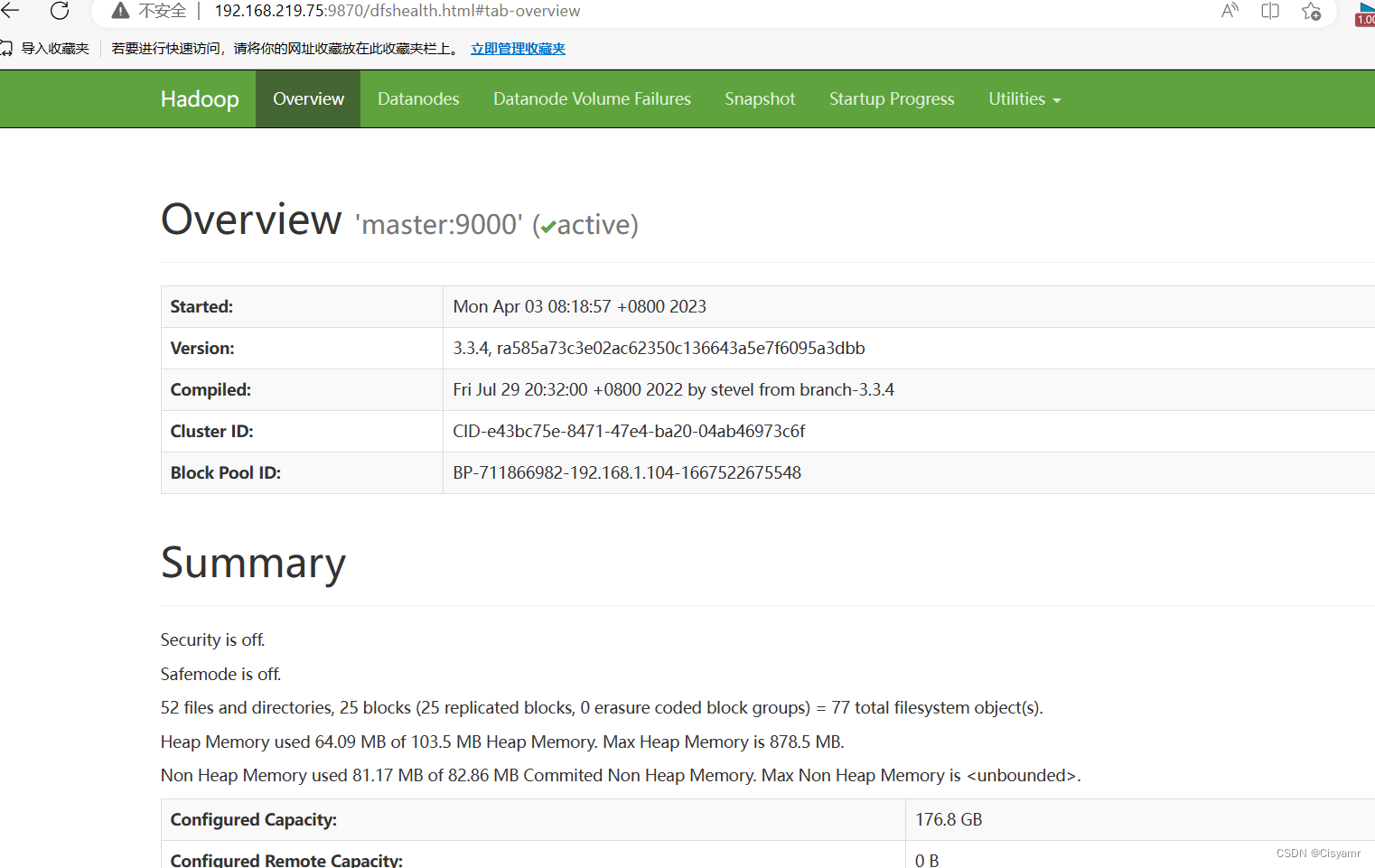
- 访问Hadoop WebUI界面
4、在master虚拟机上安装配置Spark
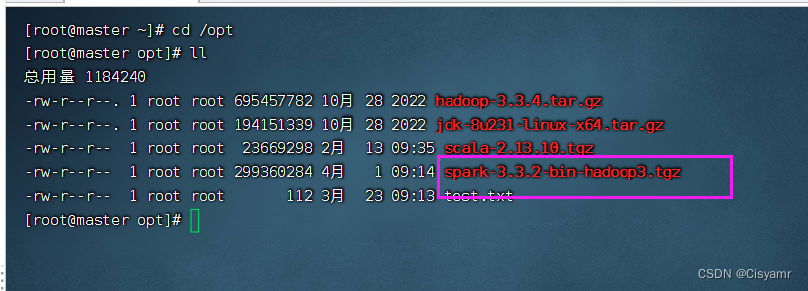
4.1、将spark安装包上传到master虚拟机
- 进入
/opt目录,查看上传的spark安装包
4.2、将spark安装包解压到指定目录
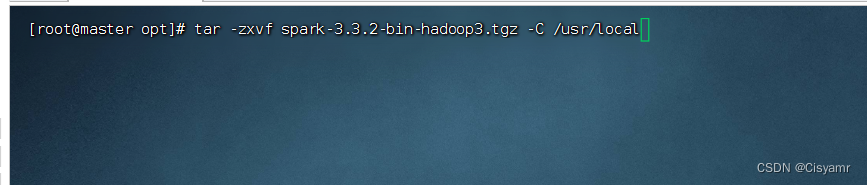
- 执行命令:
tar -zxvf spark-3.3.2-bin-hadoop3.tgz -C /usr/local
4.3、配置spark环境变量
- 执行命令:
vim /etc/profile
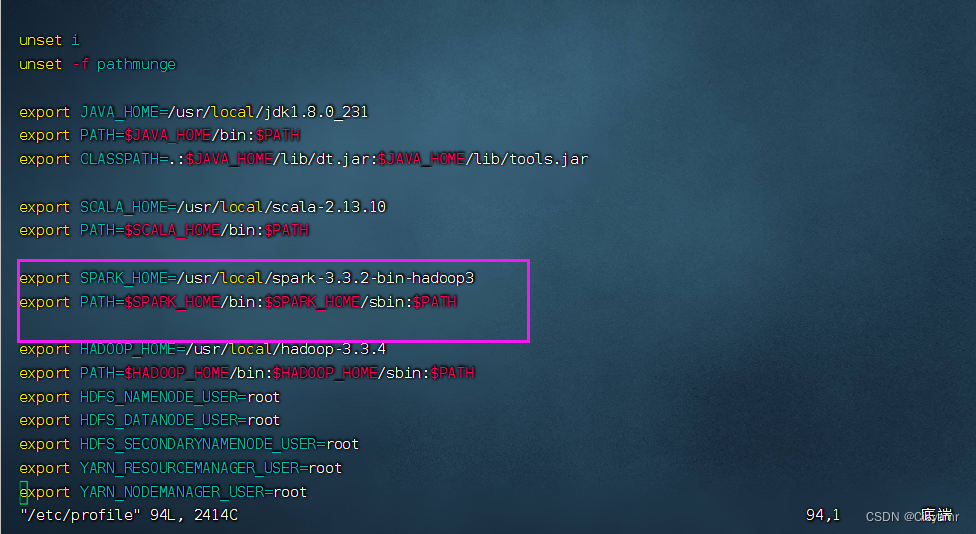
export SPARK_HOME=/usr/local/spark-3.3.2-bin-hadoop3
export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
- 存盘退出后,执行命令:
source /etc/profile,让配置生效 - 查看spark安装目录
4.4、编辑spark环境配置文件
- 进入spark配置目录后,执行命令:
cp spark-env.sh.template spark-env.sh与vim spark-env.sh
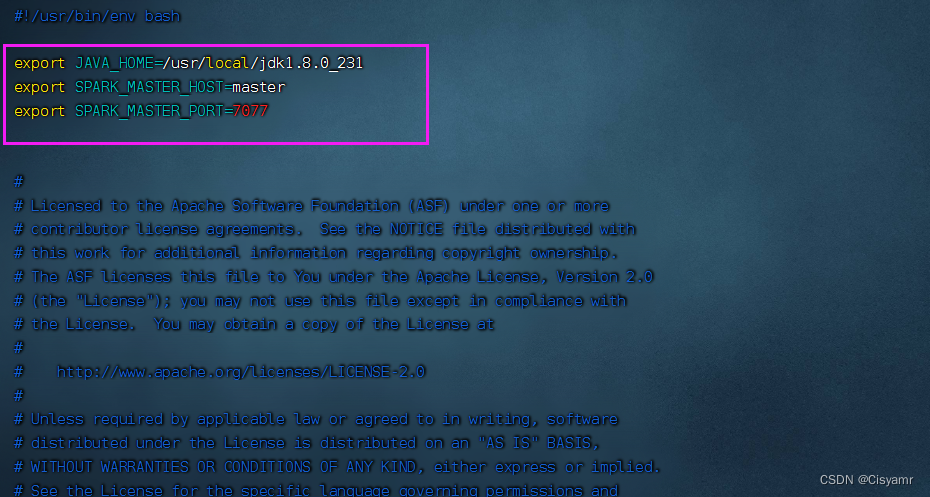
- 添加三行语句
export JAVA_HOME=/usr/local/jdk1.8.0_231
export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
- JAVA_HOME:指定JAVA_HOME的路径。若集群中每个节点在/etc/profile文件中都配置了JAVA_HOME,则该选项可以省略,Spark集群启动时会自动读取。为了防止出错,建议此处将该选项配置上。
- SPARK_MASTER_HOST:指定集群主节点(master)的主机名,此处为master。
- SPARK_MASTER_PORT:指定Master节点的访问端口,默认为7077。
- 存盘退出,执行命令:source spark-env.sh,让配置生效

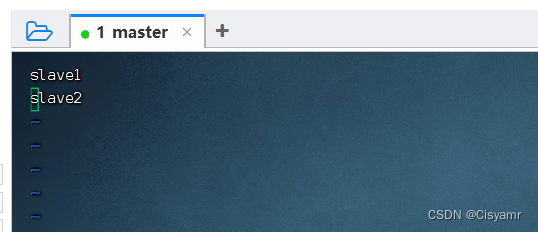
4.5、创建slaves文件,添加从节点
- 执行命令:
vim slaves,添加两个从节点主机名
5、 在slave1虚拟机上安装配置Spark
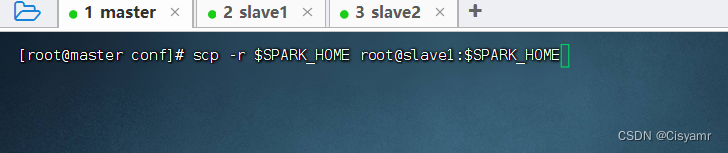
5.1、把master虚拟机上安装的spark分发给slave1虚拟机
- 执行命令:
scp -r $SPARK_HOME root@slave1:$SPARK_HOME
5.2、将master虚拟机上环境变量配置文件分发到slave1虚拟机
- 在master虚拟机上,执行命令:
scp /etc/profile root@slave1:/etc/profile

- 在slave1虚拟机上,执行命令:
source /etc/profile,让环境配置生效
5.3、在slave1虚拟机上让spark环境配置文件生效
- 在slave1虚拟机上,进入spark配置目录,执行命令:
source spark-env.sh
6、在slave2虚拟机上安装配置Spark
6.1、把master虚拟机上安装的spark分发给slave2虚拟机
- 执行命令:
scp -r $SPARK_HOME root@slave2:$SPARK_HOME

6.2、将master虚拟机上环境变量配置文件分发到slave2虚拟机
- 在master虚拟机上,执行命令:
scp /etc/profile root@slave2:/etc/profile
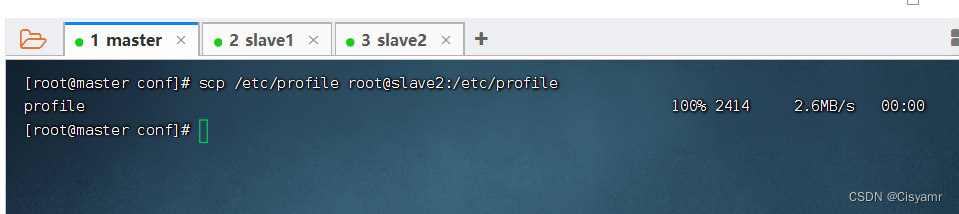
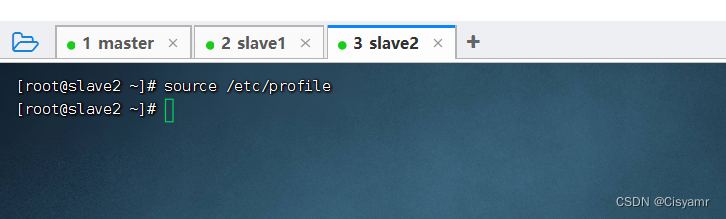
- 在slave2虚拟机上,执行命令:
source /etc/profile,让环境配置生效
6.3、在slave2虚拟机上让spark环境配置文件生效
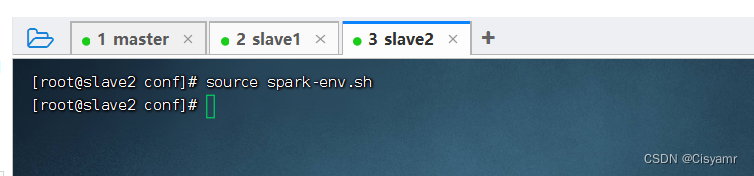
- 在slave2虚拟机上,进入spark配置目录,执行命令:
source spark-env.sh
7、启动Spark Standalone集群
- Spark Standalone集群使用Spark自带的资源调度框架,但一般我们把数据保存在HDFS上,用HDFS做数据持久化,所以Hadoop还是需要配置,但是可以只配置HDFS相关的,而Hadoop YARN不需要配置。启动Spark Standalone集群,不需要启动YARN服务,因为Spark会使用自带的资源调度框架。
7.1、启动hadoop的dfs服务
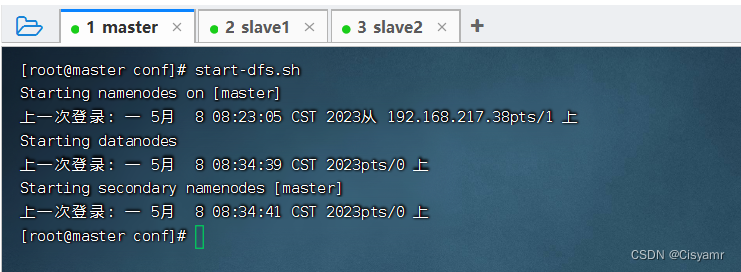
- 在master虚拟机上执行命令:
start-dfs.sh
7.2、启动Spark集群
- 执行命令:
start-all.sh 可以看到,当执行start-all.sh命令时,会分别执行start-master.sh命令启动Master,执行start-slaves.sh命令启动Worker。注意,若spark-evn.sh中配置了SPARK_MASTER_HOST属性,则必须在该属性指定的主机上启动Spark集群,否则会启动不成功;若没有配置SPARK_MASTER_HOST属性,则可以在任意节点上启动Spark集群,当前执行启动命令的节点即为Master节点。启动完毕后,分别在各节点执行jps命令,查看启动的进程。若在master节点存在Master进程,slave1节点存在Worker进程,slave2节点存在Worker进程,则说明集群启动成功。查看master节点进程
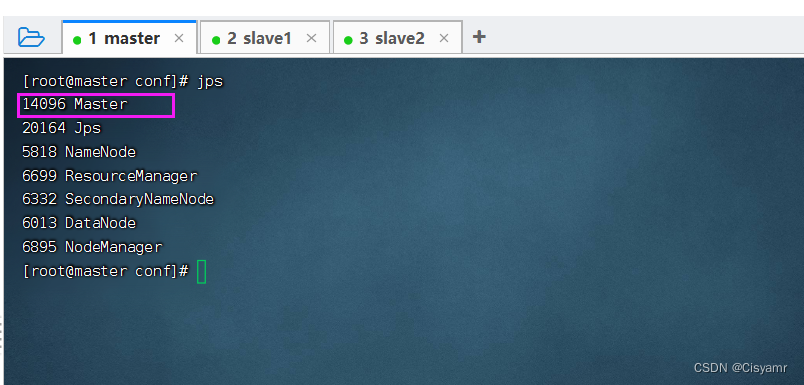
- 查看slave1节点进程
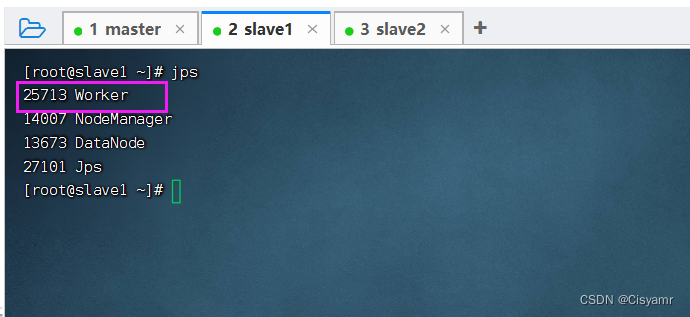
- 查看slave2节点进程
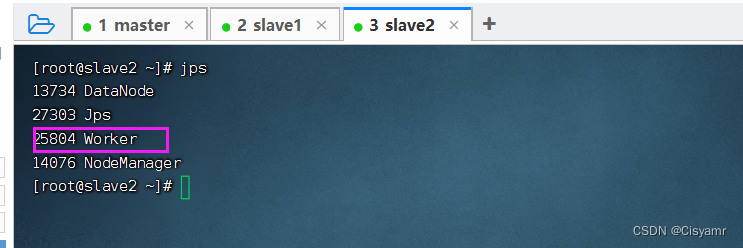
8、访问Spark的WebUI
- 在浏览器里访问
http://192.168.219.75:8080
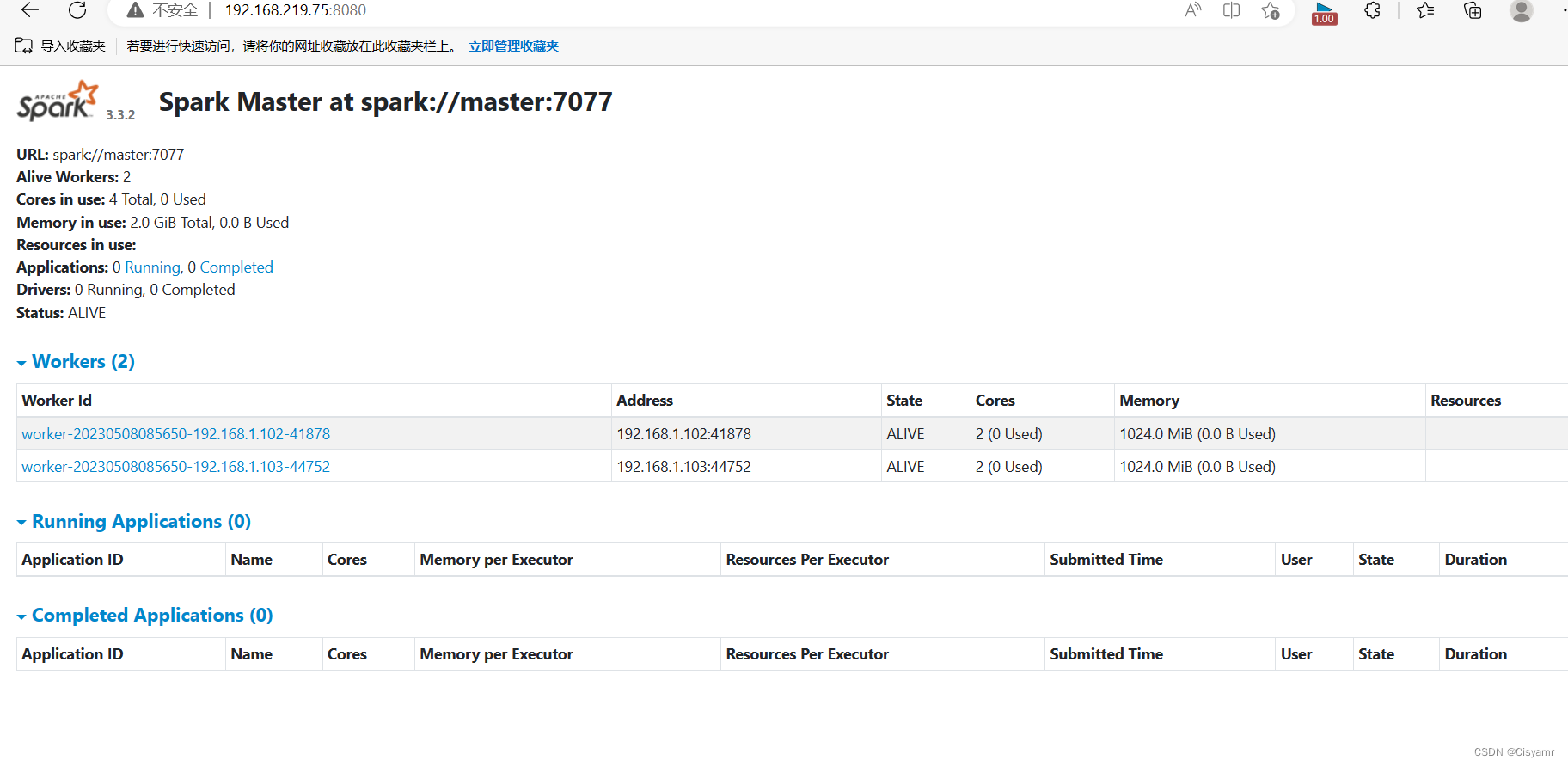
- 在浏览器访问
http://slave1:8081
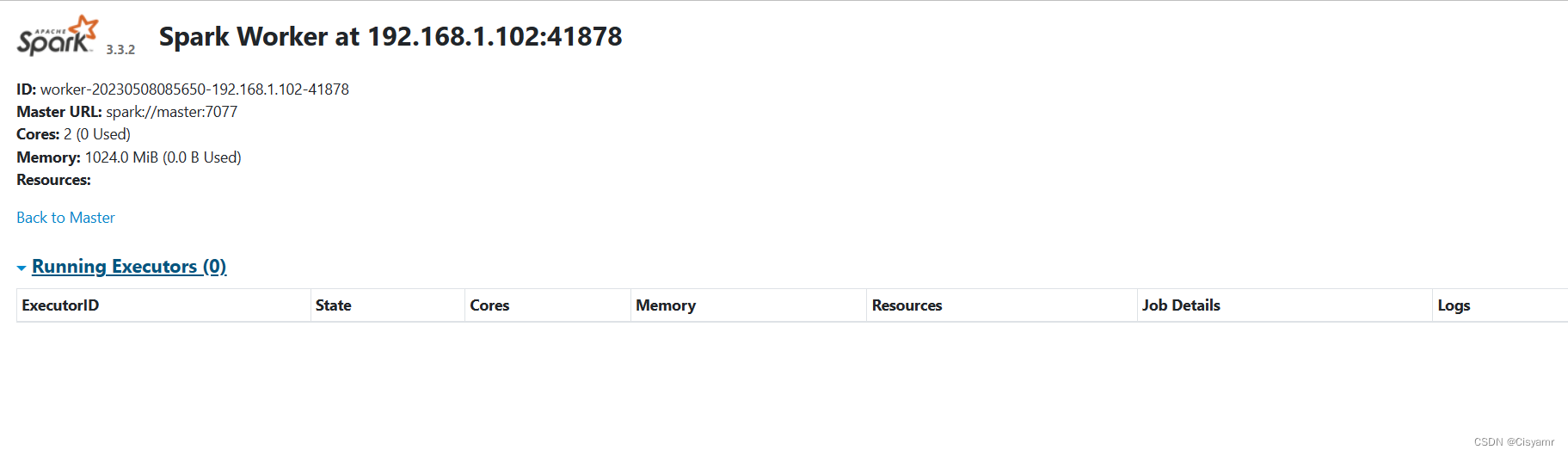
- 在浏览器访问
http://slave2:8081
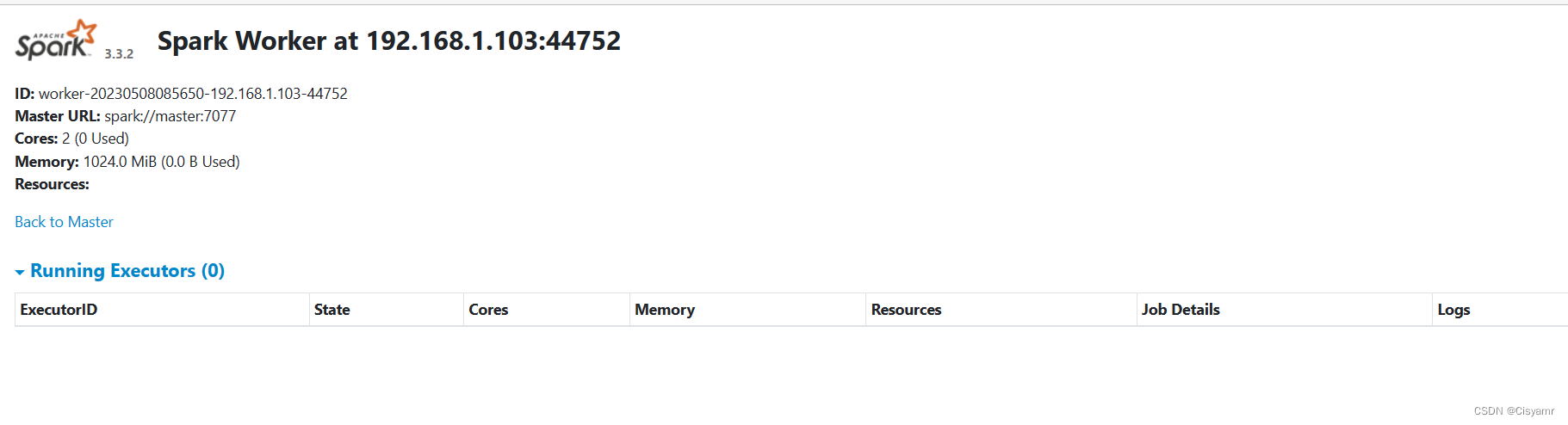
- 如果要用IP地址来访问,得用浮动IP地址,不能用私有IP地址
9、启动Scala版Spark Shell
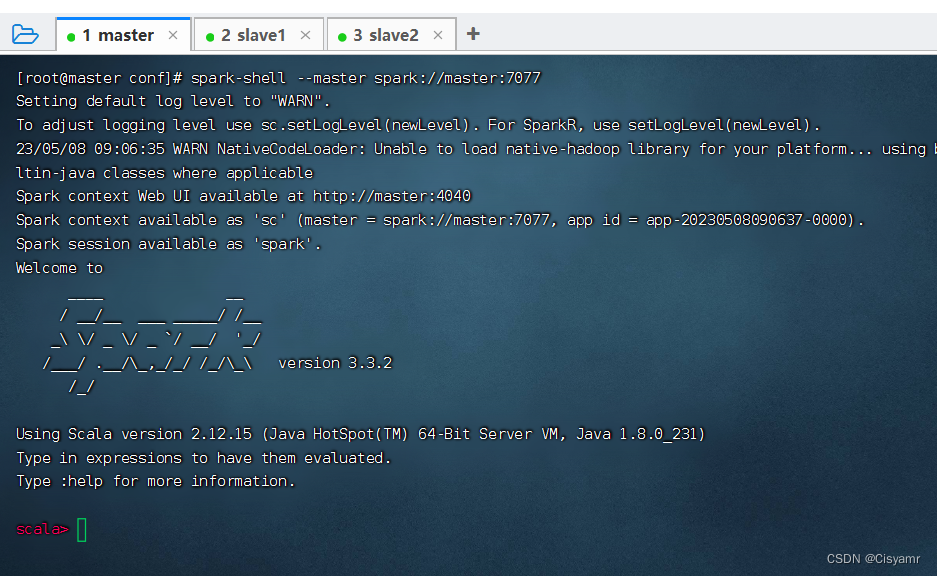
- 执行命令:
spark-shell --master spark://master:7077(注意--master,两个-不能少)
- 在
/opt目录里执行命令:vim test.txt

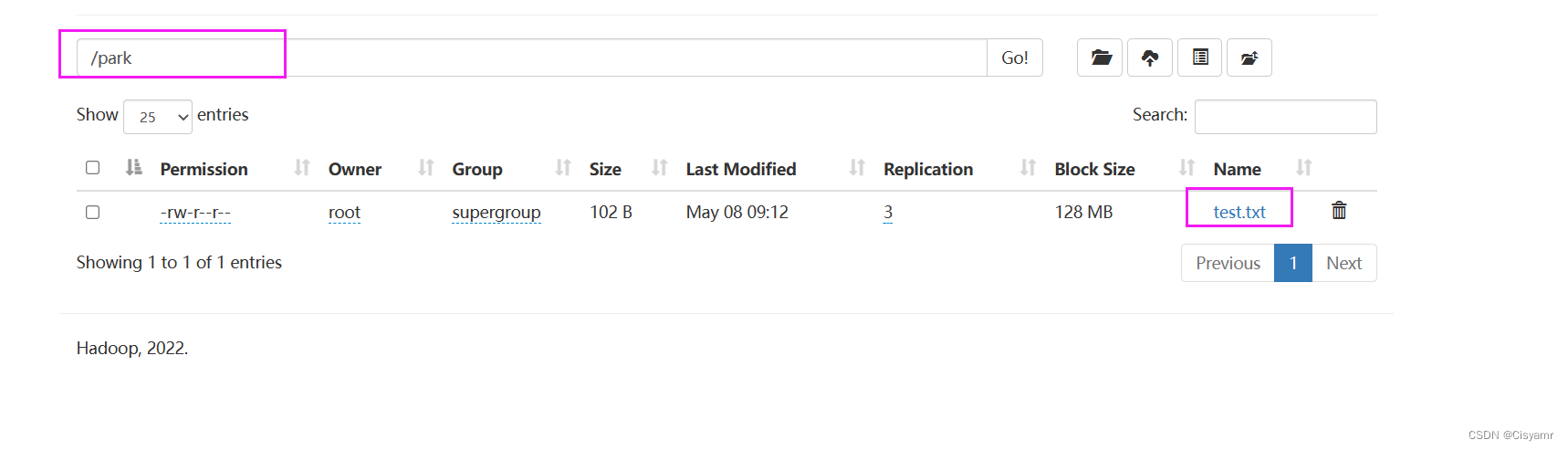
- 在HDFS上创建
park目录,将test.txt上传到HDFS的/park目录
- 读取HDFS上的文件,创建RDD,执行命令:val rdd = sc.textFile("hdfs://192.168.219.75:9000/park/test.txt")(说明:val rdd = sc.textFile("/park/test.txt")读取的依然是HDFS上的文件,绝对不是本地文件)

- 收集rdd的数据,执行命令:
rdd.collect

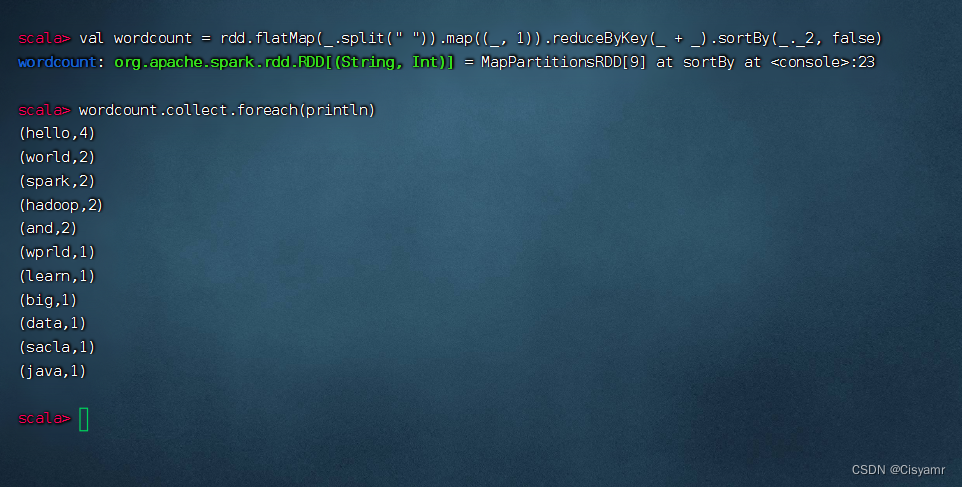
- 进行词频统计,按单词个数降序排列,执行命令:val wordcount = rdd.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).sortBy(_._2, false)与`wordcount.collect.foreach(println)
10、提交Spark应用程序
10.1、提交语法格式
- Spark提供了一个客户端应用程序提交工具spark-submit,使用该工具可以将编写好的Spark应用程序提交到Spark集群。
- spark-submit的使用格式如下:$ bin/spark-submit [options] <app jar> [app options]
- options表示传递给spark-submit的控制参数;
- app jar表示提交的程序JAR包(或Python脚本文件)所在位置;
- app options表示jar程序需要传递的参数,例如main()方法中需要传递的参数。
10.2、spark-submit常用参数
- 除了
--master参数外,spark-submit还提供了一些控制资源使用和运行时环境的参数。
| 参数 | 描述 |
| –master | Master节点的连接地址,取值为spark://host:port、mesos://host:port、yarn、k8s://https://host:port 或 local(默认为local[*]) |
| –deploy-mode | 提交方式,取值为client或cluster。client表示在本地客户端启动Driver程序,cluster表示在集群内部的工作节点上启动Driver程序,默认为client |
| –class | 应用程序的主类(Java或Scala程序) |
| –name | 应用程序名称,会在Spark Web UI中显示 |
| –jars | 应用依赖的第三方JAR包列表,以逗号分隔 |
| –files | 需要放到应用工作目录中的文件列表,以逗号分隔。此参数一般用来放需要分发到各节点的数据文件 |
| –conf | 设置任意的SparkConf配置属性,格式为“属性名=属性值” |
| -properties-file | 加载外部包含键值对的属性文件。如果不指定,就默认读取Spark安装目录下的conf/spark-defaults.conf 文件中的配置 |
| –driver-memory | Driver进程使用的内存量,例如512MB或1GB,单位不区分大小写,默认为1GB |
| –executor-memory | 每个Executor进程所使用的内存量。例如512MB或1GB,单位不区分大小写,默认为1GB |
| –driver-cores | Driver进程使用的CPU核心数,仅在集群模式中使用,默认为1 |
| -executor-cores | 每个Executor进程所使用的CPU核心数,默认为1 |
| num-executors | Executor进程数量,默认为2。如果开启动态分配,那么初始Executor的数量至少是此参数配置的数量。需要注意的是,此参数仅在Spark On YARN模式中使用 |
10.3、案例演示 - 提交Spark自带的圆周率计算程序
- 进入Spark安装目录
- 执行下述命令,将Spark自带的求圆周率的程序提交到集群
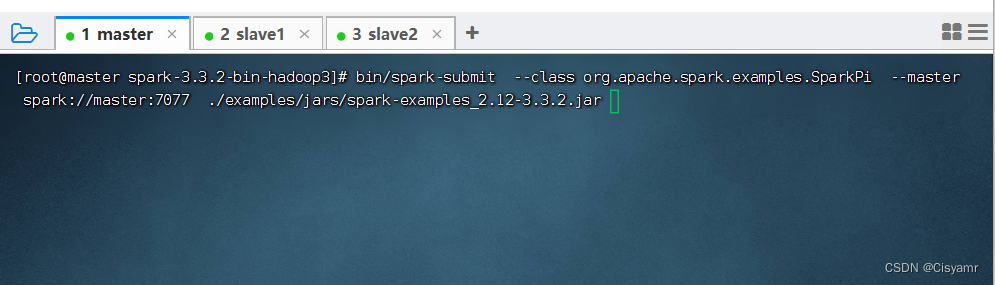
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://master:7077 \
./examples/jars/spark-examples_2.12-3.3.2.jar
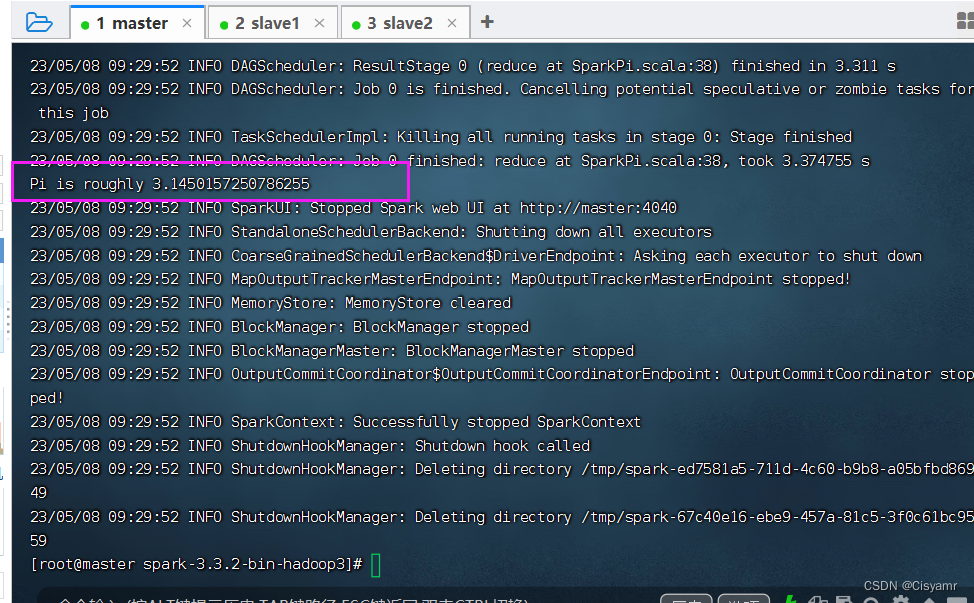
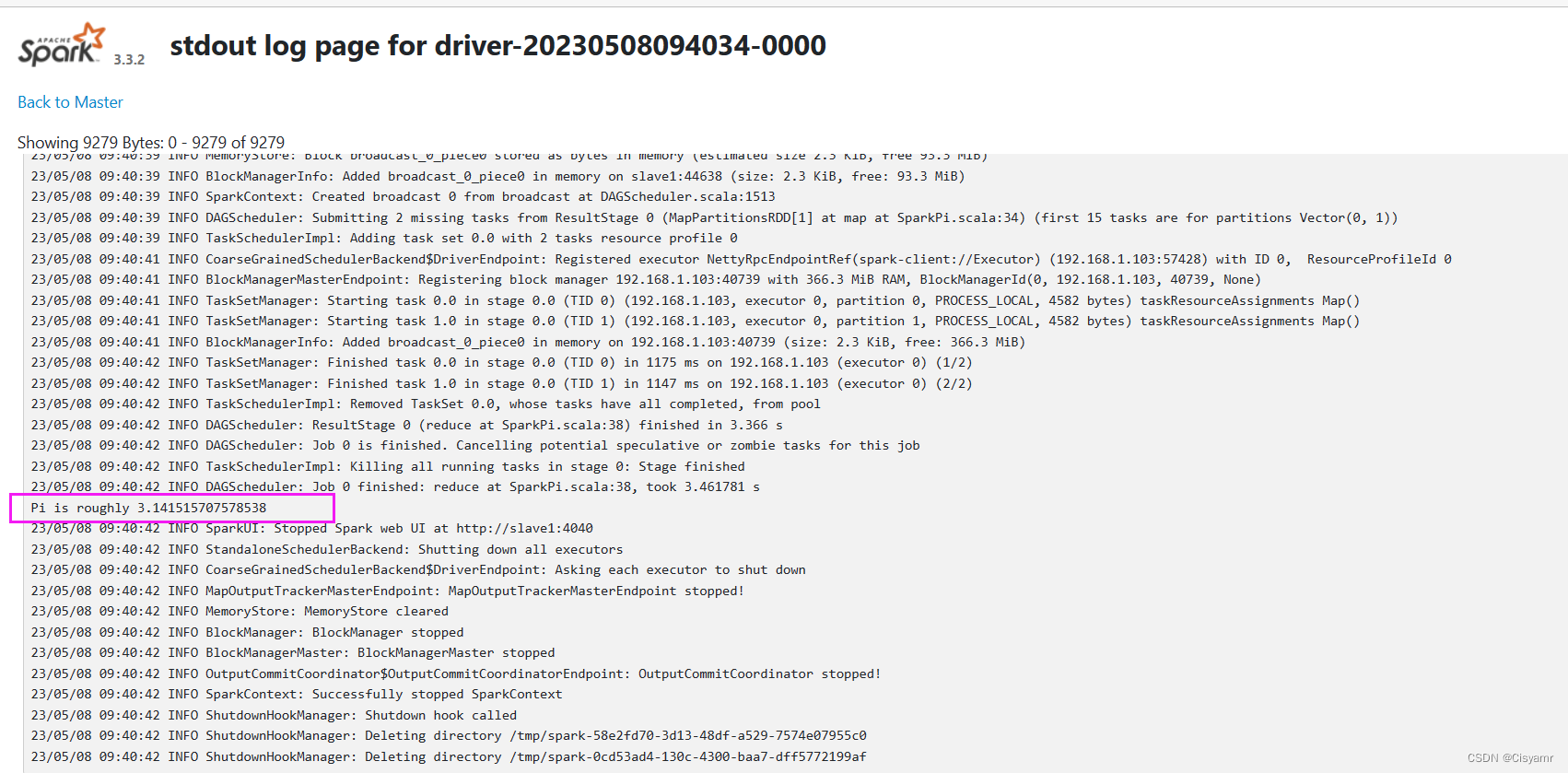
- 提交Spark作业后,观察Spark集群管理界面,其中“Running Applications”列表表示当前Spark集群正在计算的作业,执行几秒后,刷新界面,在Completed Applications表单下,可以看到当前应用执行完毕,返回控制台查看输出信息,出现了“Pi is roughly 3.1424157120785603”,说明Pi值已经被计算完毕。
-
上述命令中的–master参数指定了Master节点的连接地址。该参数根据不同的Spark集群模式,其取值也有所不同,常用取值如下表所示。
| 取值 | 描述 |
| spark://host:port | Standalone模式下的Master节点的连接地址,默认端口为7077 |
| yarn | 连接到YARN集群。若YARN中没有指定ResourceManager的启动地址,则需要在ResourceManager所在的节点上进行应用程序的提交,否则将因找不到ResourceManager而提交失败 |
| local | 运行本地模式,使用1个CPU核心 |
| local[N] | 运行本地模式,使用N个CPU核心。例如,local[2]表示使用两个CPU核心运行程序 |
| local[*] | 运行本地模式,尽可能使用最多的CPU核心 |
- 若不添加–master参数,则默认使用本地模式local[*]运行。
- 在Standalone模式下,将Spark自带的圆周率计算程序提交到集群,并且设置Driver进程使用内存为512MB,每个Executor进程使用内存为1GB,每个Executor进程所使用的CPU核心数为2,提交方式为cluster(Driver进程运行在集群的工作节点中),执行命令如下:
bin/spark-submit \
--master spark://master:7077 \
--deploy-mode cluster \
--class org.apache.spark.examples.SparkPi \
--driver-memory 512m \
--executor-memory 1g \
--executor-cores 2 \
./examples/jars/spark-examples_2.12-3.3.2.jar
- 执行命令后,看到
State of driver-20230406114733-0000 is RUNNING,就表明运行成功~,否则会显示State of driver-20230406114733-0000 is FAILED

- 在Spark WebUI界面上查看运行结果
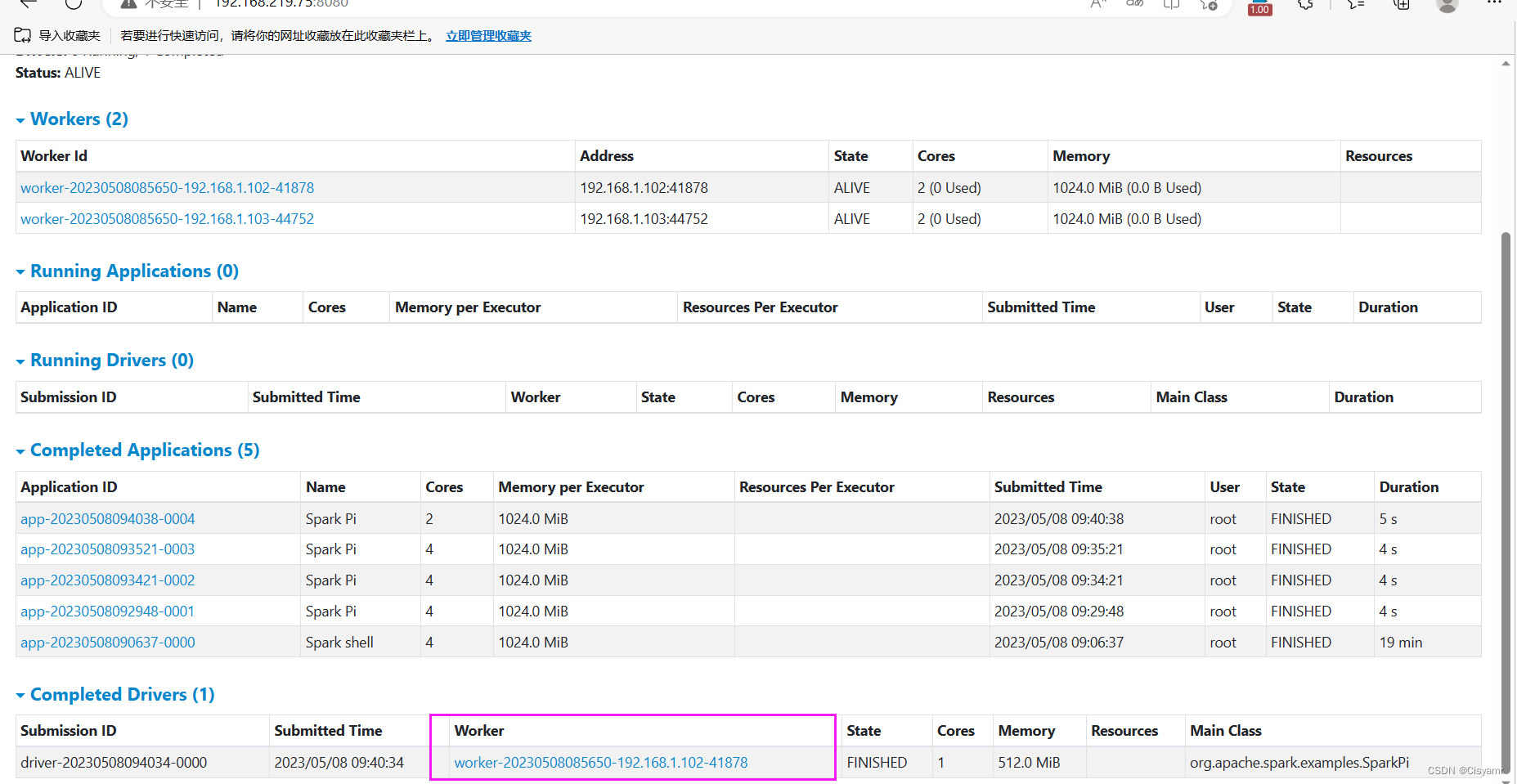
- 单击圈红的
Worker超链接 -worker-20230406114652-192.168.1.102-36708 - 注意:必须把私有IP地址改成主机名
slave1或者对应的浮动IP地址
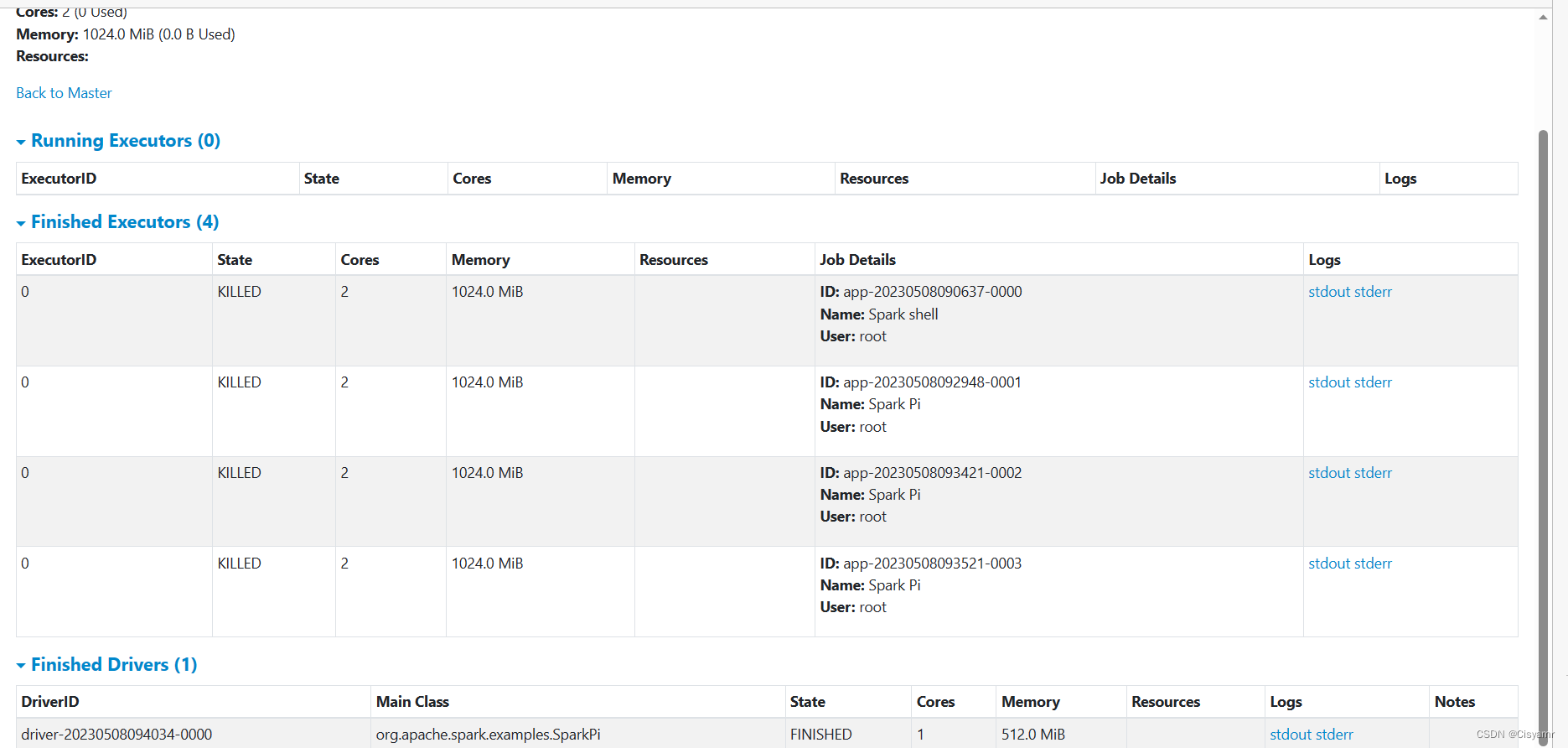
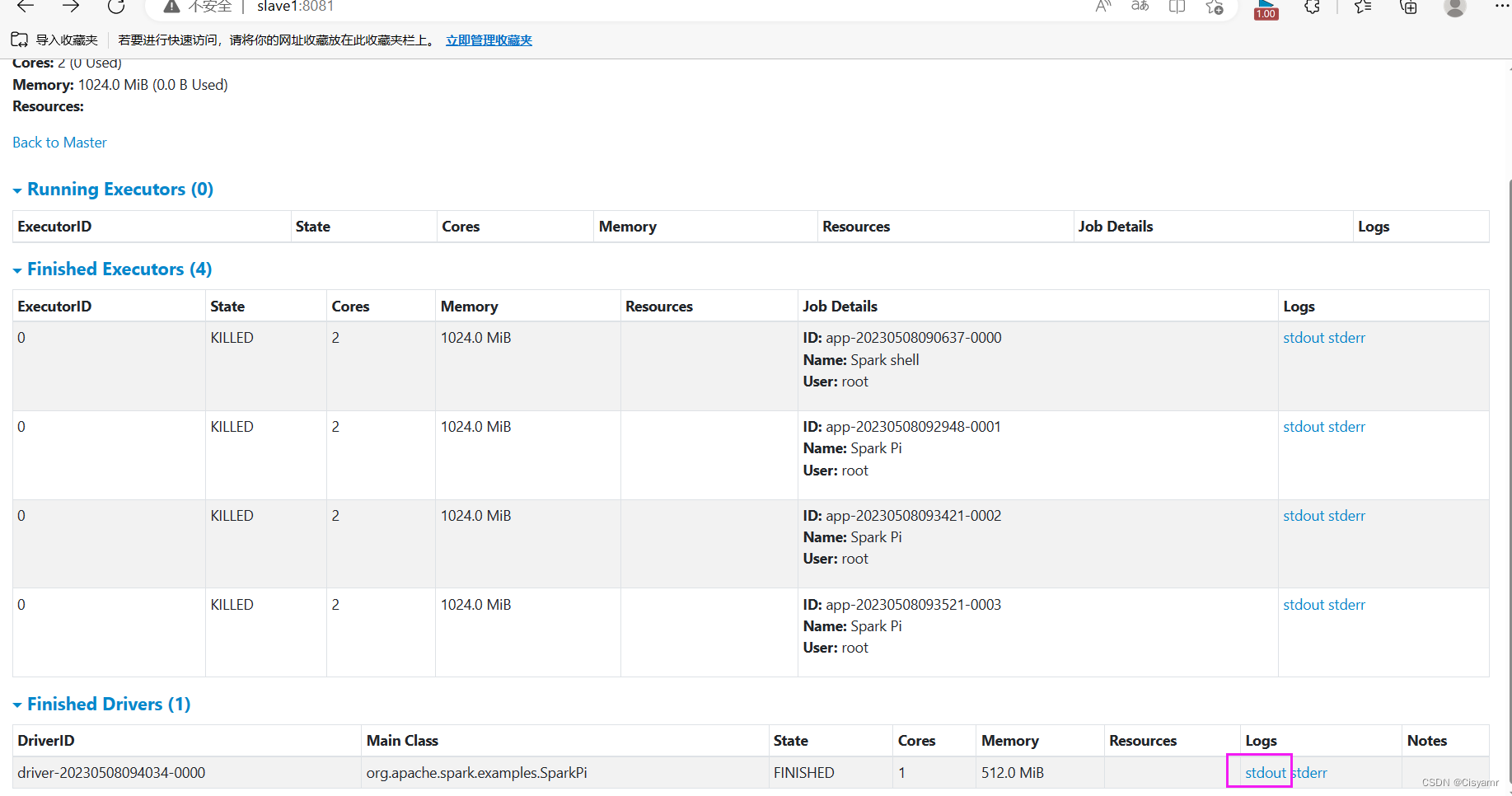
- 单击
stdout超链接,可以查看到Pi的计算结果
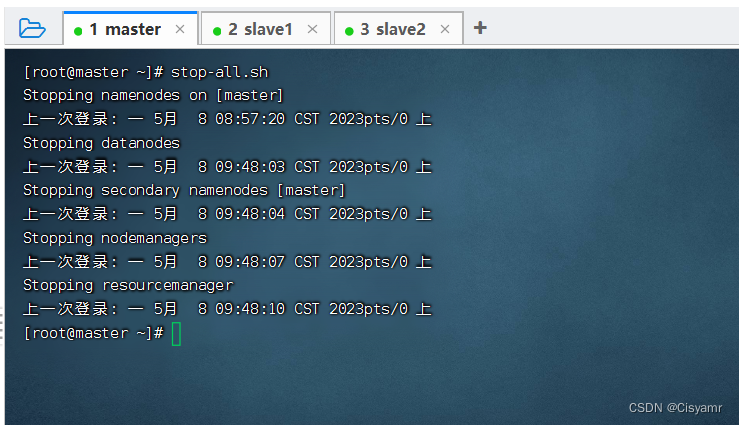
11、停止Spark集群服务
- 在master节点执行命令:
stop-all.sh















 705
705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









