






https://www.bilibili.com/video/BV1MW411w79n?p=2&vd_source=275b19d02ca629f220713e4de0936247
目录
Policy Gradient - review
各种概念
三要素:
· actor
· environment - 不可控制
· reward - 不可控制
· policy
π
\pi
π is a network of param
θ
\theta
θ,
input=state(可以理解为游戏的画面、现状),
output=可能的actor的概率分布
· episode = 一轮游戏,trajectory
τ
=
s
1
,
a
1
,
s
2
,
a
2
,
.
.
.
,
s
T
,
a
T
\tau = s_1,a_1,s_2,a_2, ...,s_T, a_T
τ=s1,a1,s2,a2,...,sT,aT
· 一个episode的total reward:
R
=
∑
t
=
1
T
r
t
R = \sum_{t=1}^T r_t
R=∑t=1Trt, 一共T轮的reward总和; actor存在的意义就是maximize total reward
· expected reward: 穷举所有trajectory,算出total reward的均值
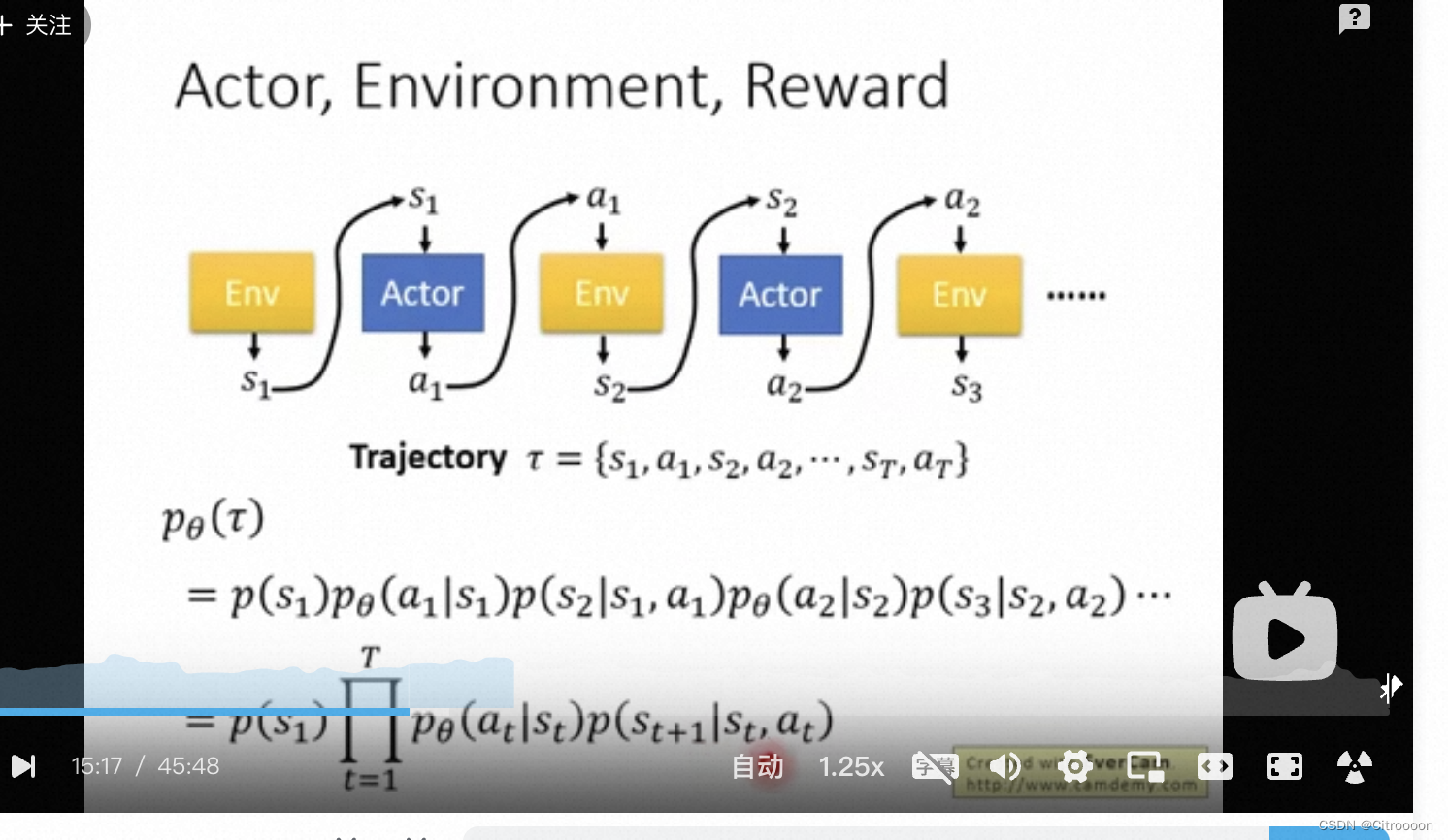
最大化total reward的推导过程
total reward R
p
θ
(
τ
)
=
p
(
s
1
)
p
θ
(
a
1
∣
s
1
)
p
(
s
2
∣
s
1
,
a
1
)
p
θ
(
a
1
∣
s
2
)
p
(
s
3
∣
s
2
,
a
2
)
.
.
.
p_\theta(\tau) = p(s_1)p_\theta(a_1|s_1)p(s_2|s_1,a_1)p_\theta(a_1|s_2)p(s_3|s_2,a_2)...
pθ(τ)=p(s1)pθ(a1∣s1)p(s2∣s1,a1)pθ(a1∣s2)p(s3∣s2,a2)...
=
p
(
s
1
)
∏
t
=
1
T
p
θ
(
a
t
∣
s
t
)
p
(
s
t
+
1
∣
s
t
,
a
t
)
=p(s_1)\prod_{t=1}^Tp_\theta(a_t|s_t)p(s_{t+1}|s_t,a_t)
=p(s1)∏t=1Tpθ(at∣st)p(st+1∣st,at)
expected reward:
R
θ
=
∑
τ
R
(
τ
)
p
θ
(
τ
)
=
E
τ
−
p
θ
(
τ
)
[
R
(
τ
)
]
R_\theta =\sum_\tau R(\tau)p_\theta(\tau) = E_{\tau -p_\theta(\tau)}[R(\tau)]
Rθ=∑τR(τ)pθ(τ)=Eτ−pθ(τ)[R(τ)]
从
p
θ
(
τ
)
p_{\theta}(\tau)
pθ(τ)这个概率分布中采样一个
τ
\tau
τ的reward就是reward的期望值
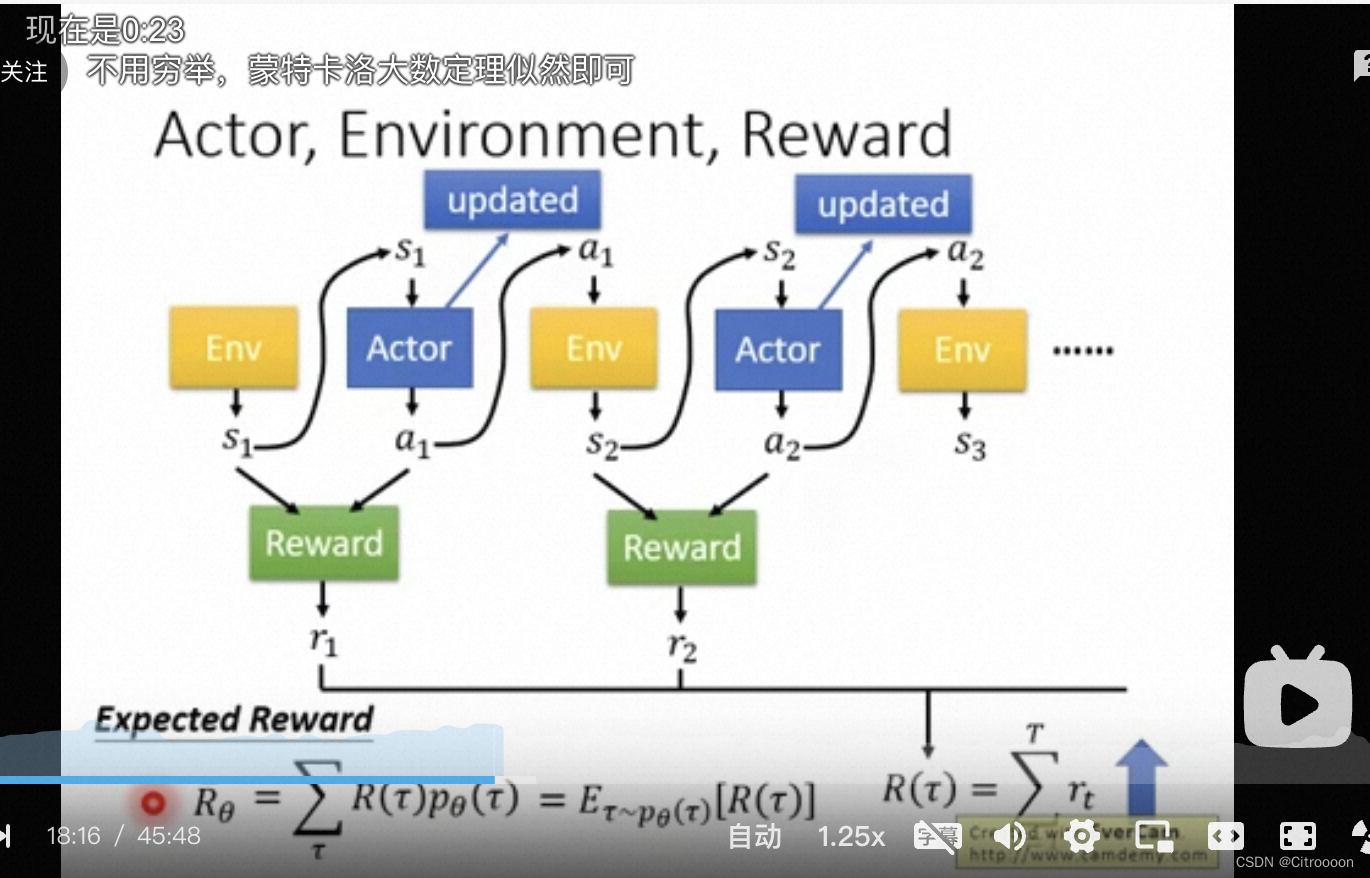
gradient descent
用gradient descent 来求
θ
\theta
θ 以最大化expected reward

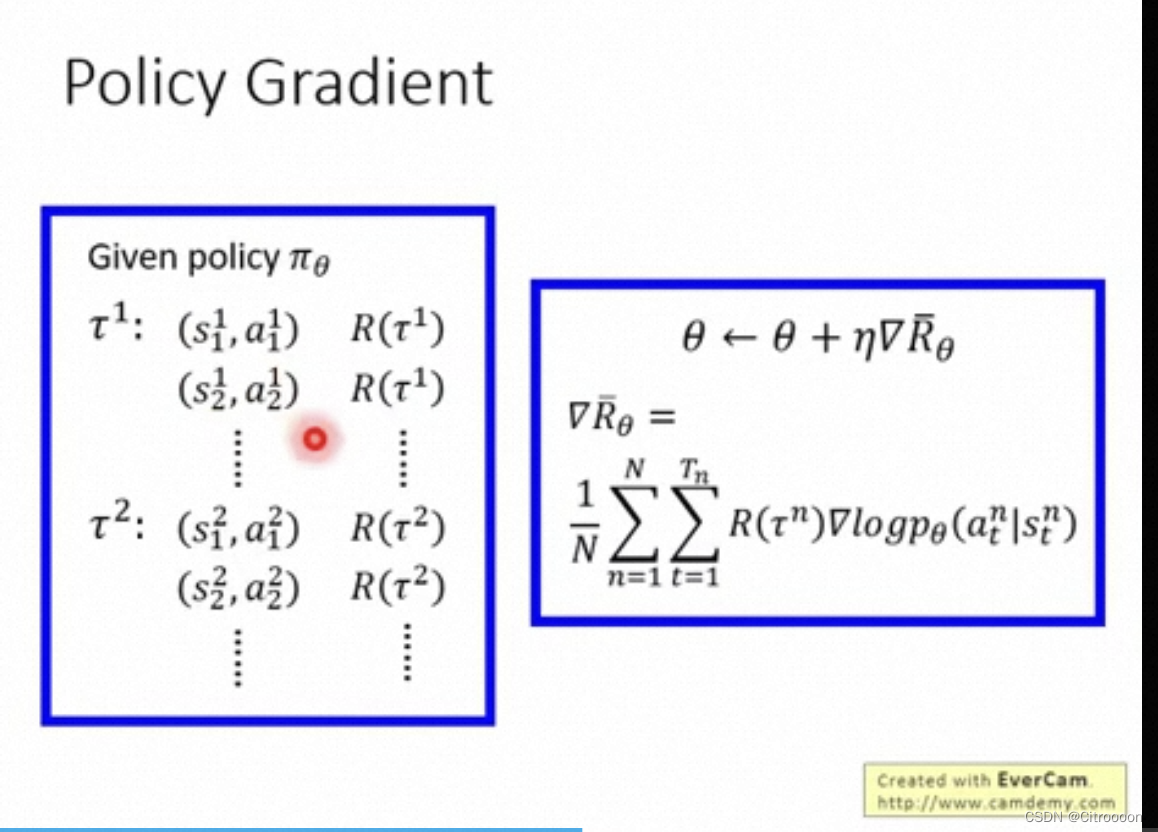
如果在
s
t
s_t
st执行
a
t
a_t
at导致整个trajectory的reward是正的,那么就要增加在
s
t
s_t
st执行
a
t
a_t
at的几率
p
(
a
t
∣
s
t
)
p(a_t|s_t)
p(at∣st), 反之就要减小这个几率.
θ
\theta
θ更新:
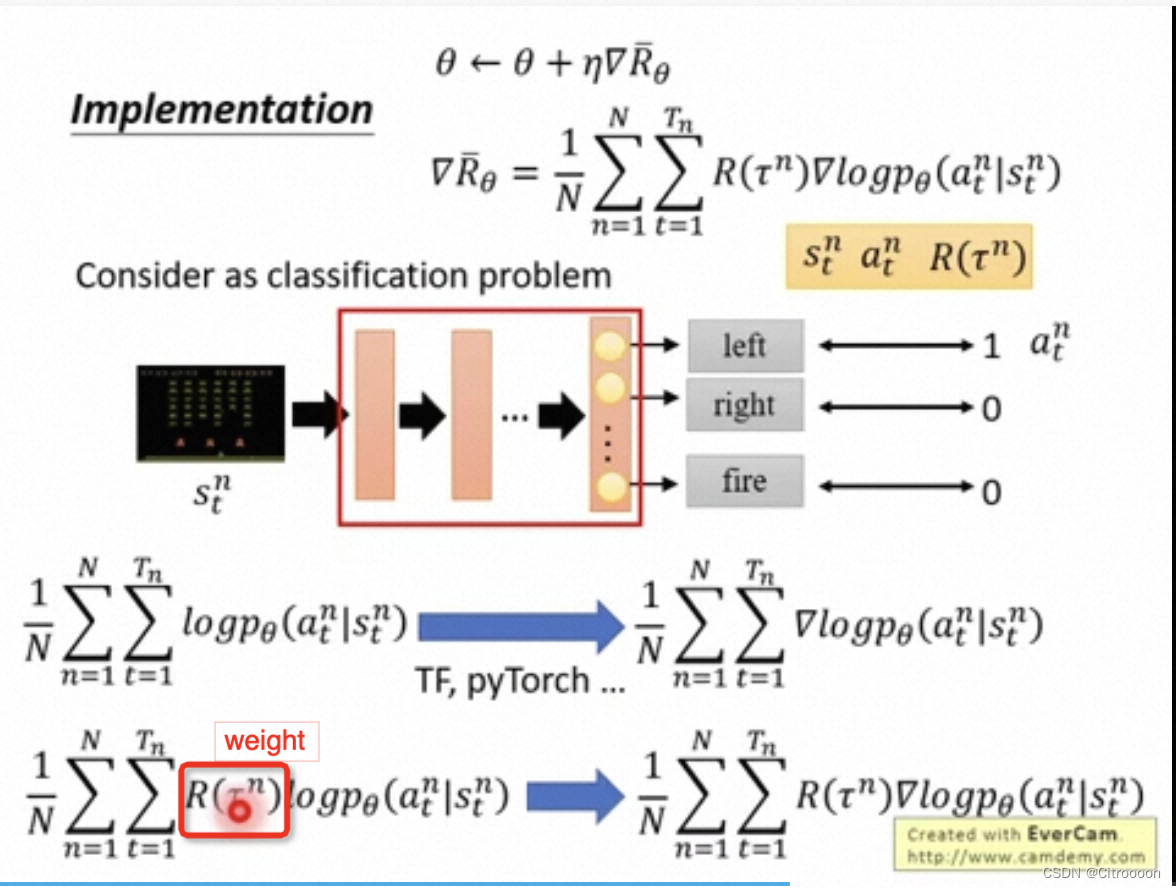
实践中 可以想成一个多分类问题
如果对于一个state你采样到做了action a 那么就把action a 作为label
minimize cross entropy = maximize log-likelihood
与mll的区别就是要乘上一个weight,也就是total reward
如何正确表示R
Tip1: Baseline
R 如果一直是负的,会造成问题,所以要减去baseline
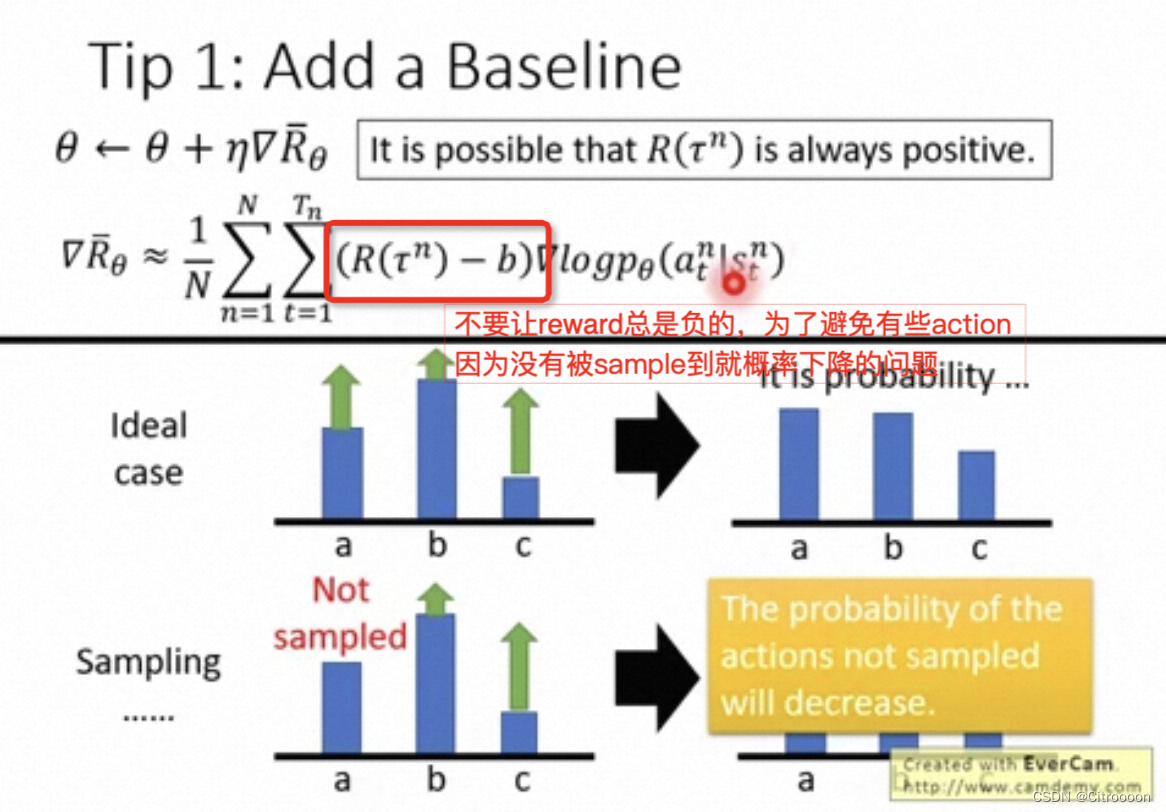
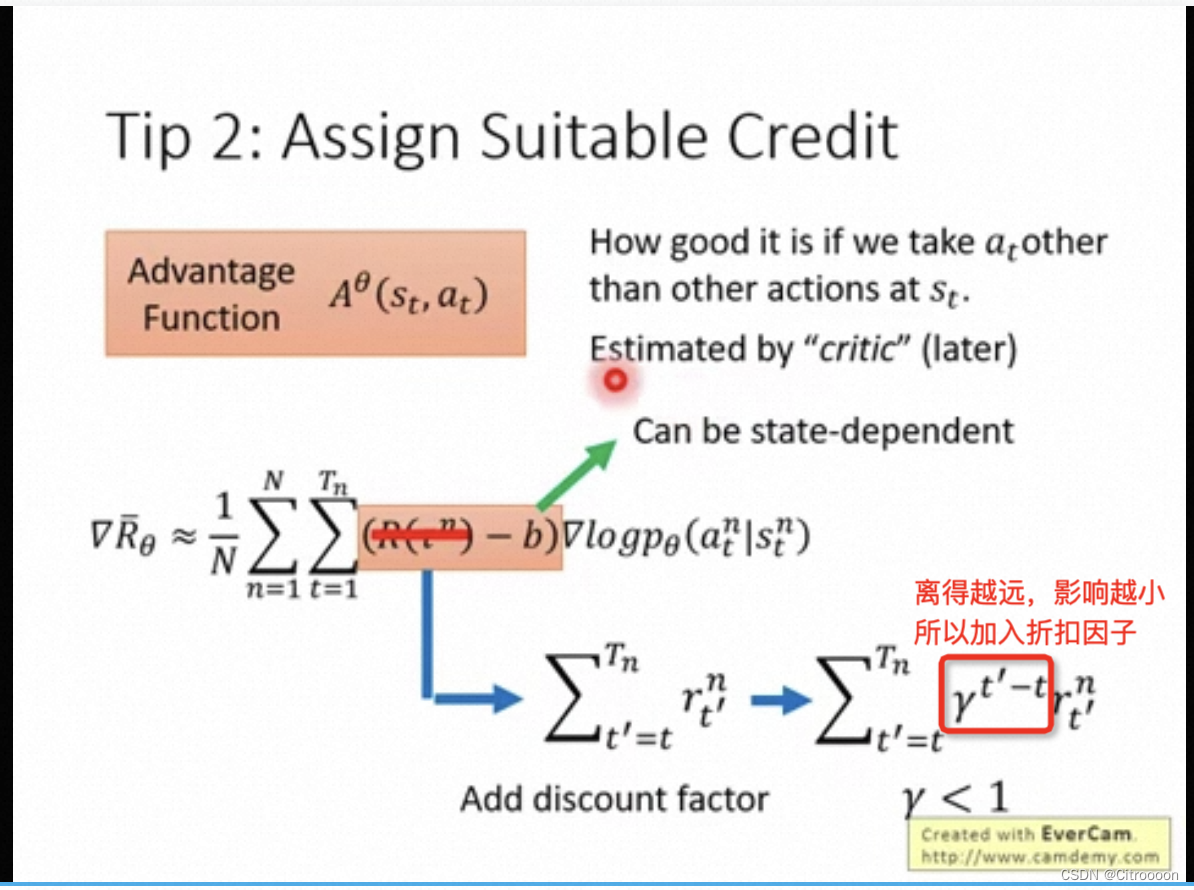
Tip2: Credit
一个整体reward是正的,但不代表其中每一步都是好的,所以加入credit

PPO
on-policy & off-policy
on-policy: 学习的agent和与环境交互的agent是同一个。–自己学下棋
off-policy: 学习的agent和与环境交互的agent不是同一个。 – 看别人学下棋
假设我们只能在q这个分布中采样,那么如何表示期望:

q和p的分布不能差距太大的原因:

θ
′
\theta'
θ′ 是示范给
θ
\theta
θ看, 跟环境做互动会发生什么。我们要优化的是theta。

PPO: 加入KL散度惩罚
ppo本质就是走好几步之后在调整一次,普通的policy gradient就是每一步都要更新


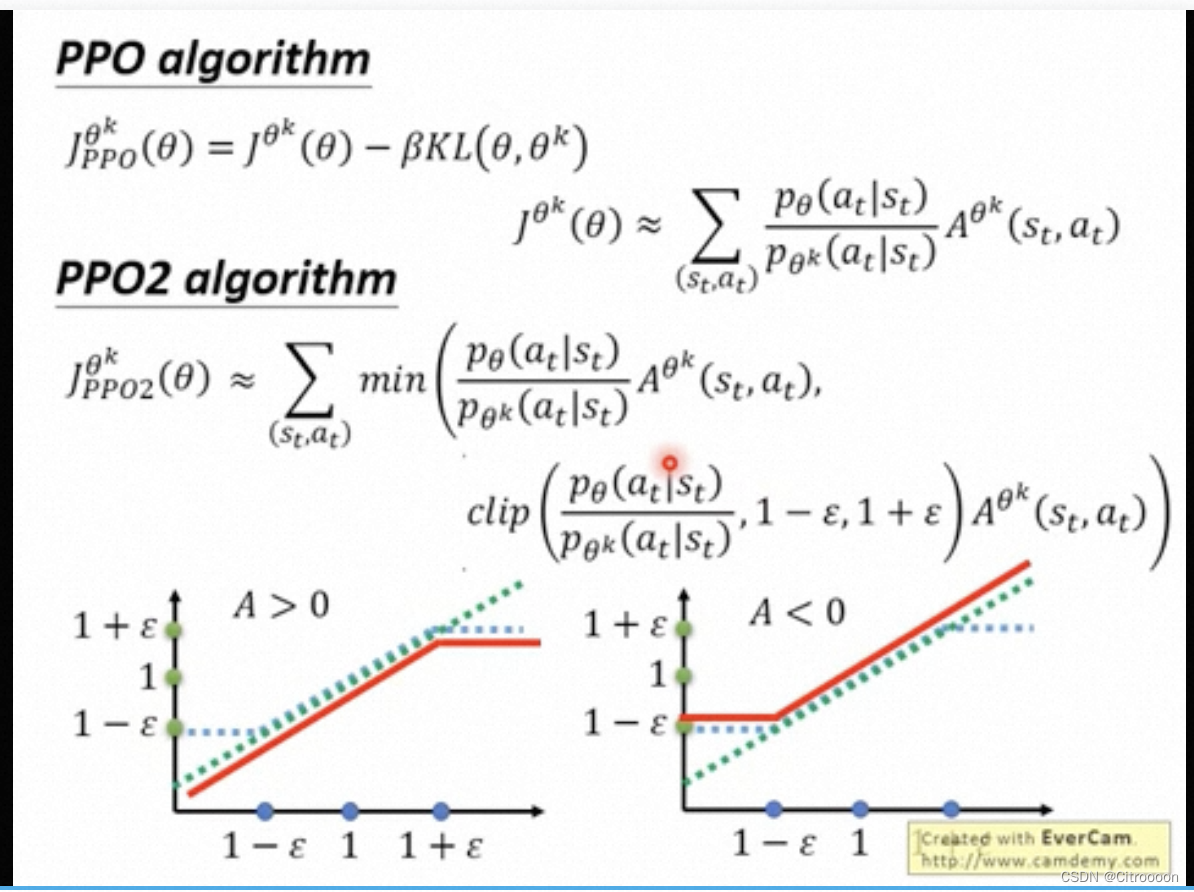
横轴:
p
θ
/
p
θ
k
p_\theta / p_\theta^k
pθ/pθk ; 如果A>0 希望
p
θ
p_\theta
pθ越大越好,但是不能超过
1
+
ϵ
1+\epsilon
1+ϵ; 反之不能小于
1
−
ϵ
1-\epsilon
1−ϵ















 3125
3125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









