








论文地址:https://arxiv.org/pdf/1506.04214v1.pdf
Intro
背景:相对较短的时间内预测局部区域未来的降雨强度
难点:对预测的准确度和时间的精确性要求较高
本文将降水预报问题建模成一个时空序列预测问题,可以在一般sequence-to-sequence学习框架下解决。为了很好地模拟时空关系,本文将FC-LSTM的概念扩展到ConvLSTM,在input-to-state和state-to-state的转换中都具有卷积结构,通过堆叠多个ConvLSTM层并形成编码预测结构,构建end-to-end的可训练模型。
Preliminaries
时序问题
降水预测问题的输入是每6-10分钟获取一次天气雷达信息,用于预测未来1-6小时的天气(6-60个frames)
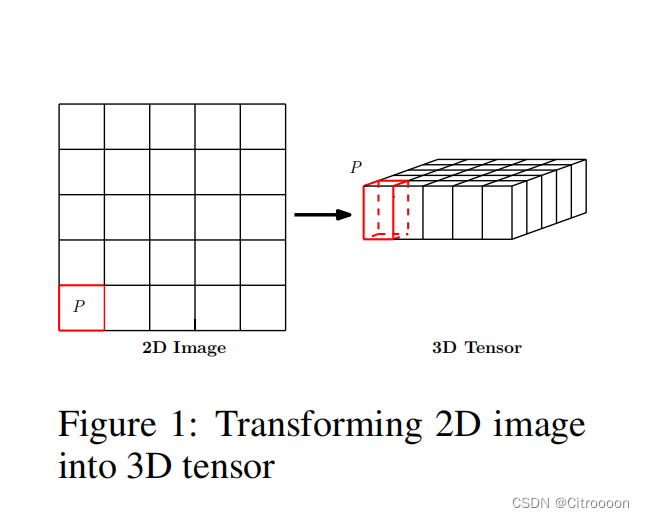
观察数据来源于一个M x N的 radar echo map, 在网格中的每个grid中,有 P 个随时间变化的测量值。 因此,任何时候的观察都可以用张量
X
∈
R
P
∗
M
∗
N
X \in R^{P*M*N}
X∈RP∗M∗N来表示。时空序列预测问题是在给定之前和当前的 J 个观测值的情况下预测未来最可能的长度为 K 的序列:
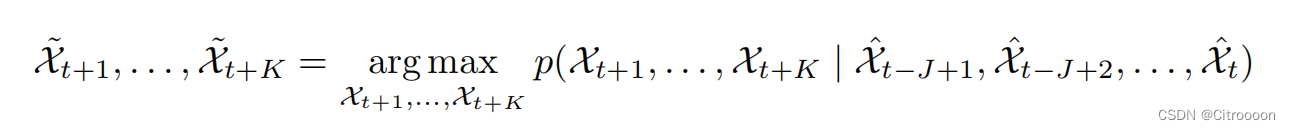
LSTM
复习:https://zhuanlan.zhihu.com/p/123857569
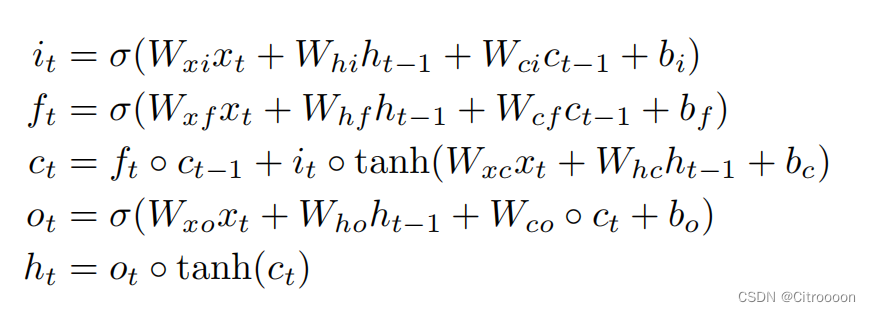
Model
conv-lstm
传统LSTM的x是1d-tensor, 而在Conv-LSTM中是3d-tensor。实际上,传统FC-LSTM的输入、输出和隐藏状态也可以看作是后二维为1的三维张量。从这个意义上说,FC-LSTM实际上是ConvLSTM的一个特例,它的所有特性都位于一个单元上。
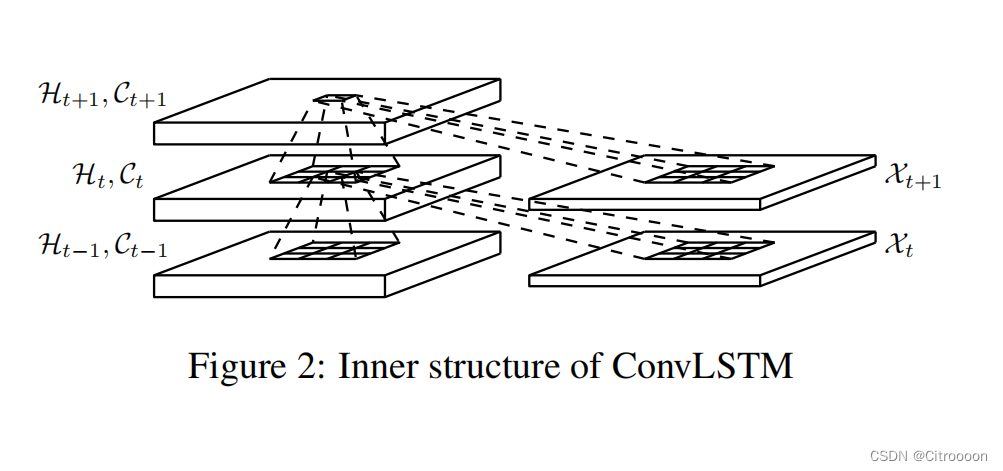
conv-lstm通过本地邻居(
X
t
X_t
Xt)的输入和过去状态(
H
t
−
1
,
C
t
−
1
H_{t-1}, C_{t-1}
Ht−1,Ct−1)来确定网格中某个单元格的未来状态。 这可以通过上图所示的卷积算子来实现。公式如下:
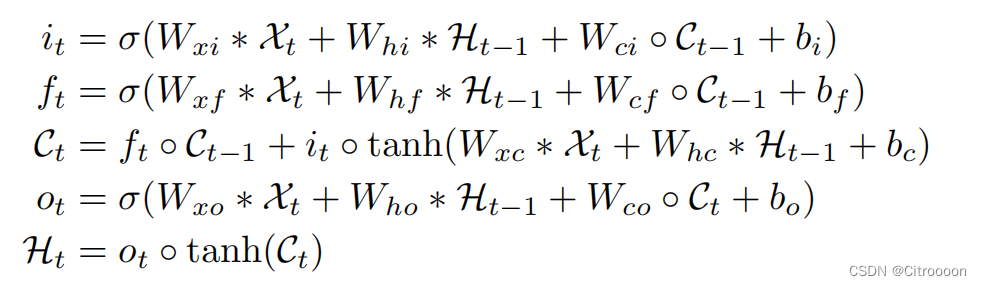
其中,*表示卷积算子,o表示product
为了确保states具有与输入相同的行数和列数,在卷积之前需要padding。通常,在第一个输入到来之前,我们将 LSTM 的所有states初始化为零,这对应于对未来的“完全无知”。 如果我们对hidden states初始化为零,我们实际上是在将外部世界的状态设置为零并且假设没有关于外部的先验知识。
encoding-forecasting structure
conv-lstm由两个网络组成,分别是encoding network编码网络 和 forecasting networ预测网络。预测网络的初始状态和单元输出是从编码网络的最后一个状态复制而来的。 这两个网络都是通过堆叠几个 ConvLSTM 层形成的。 由于我们的预测目标与输入具有相同的维度,我们将预测网络中的所有状态连接起来(红色线),并将它们输入一个 1×1 的卷积层以生成最终预测
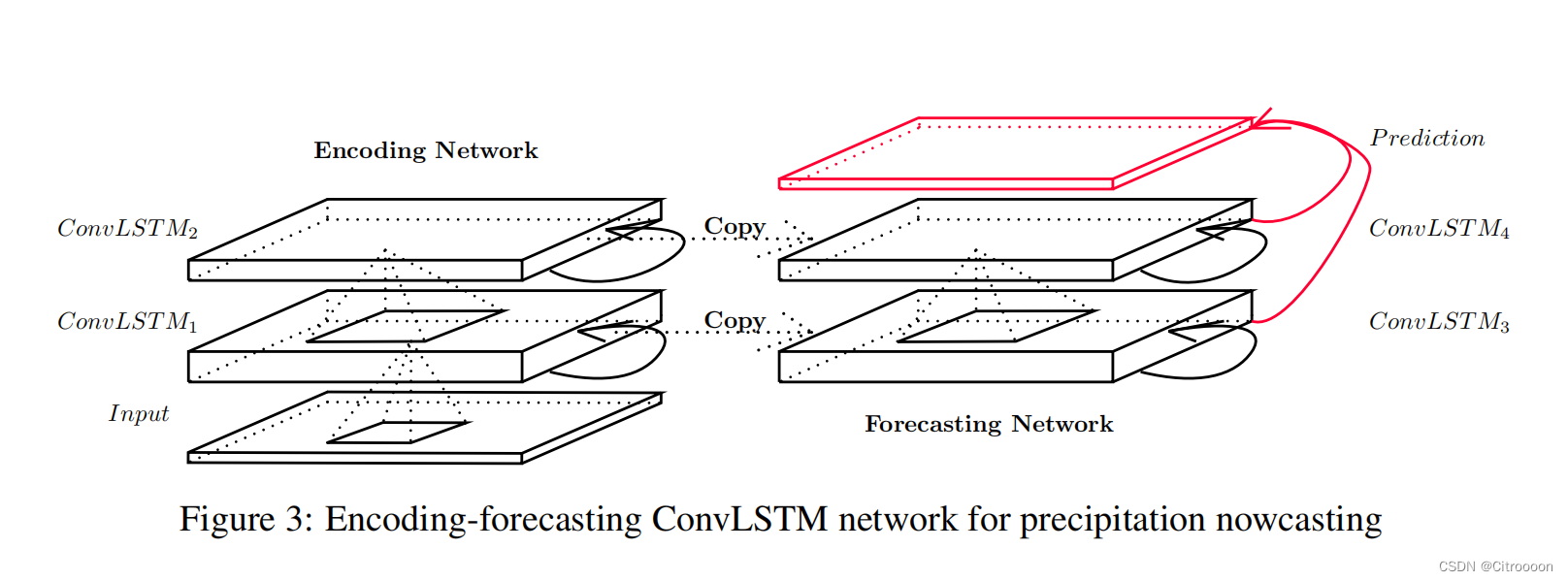
换句话说,编码 LSTM 将整个输入序列压缩为隐藏状态张量,预测 LSTM 展开该隐藏状态以给出最终预测:
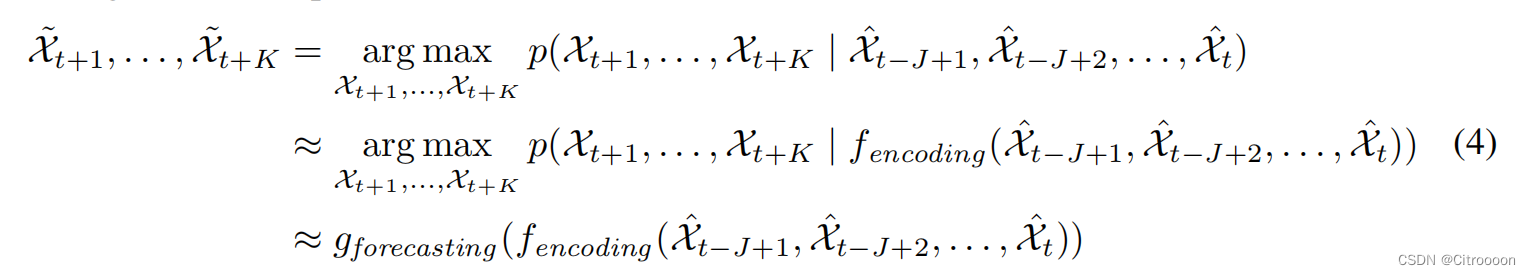
总结:conv-lstm就是3d版的传统lstm, 用卷积kernel来解决高维映射的问题。多层的堆叠也增加了网络的表达能力。
实验
base model: FC-LSTM
dataset: moving MNIST
findings:

















 290
290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









