









Intro
在做新词提取任务时,被python2的编码恶心到了,研究了半天,整理出以下tips,希望以后不要被编码问题折磨了。!
环境:windows + python 2.7.15 + spyder
ps. 直接从notebook里复制来的,就变成了图片。完整代码在最后。
几个préacquis
- python默认的编码时ASCII,需要在第一行加入 # -- coding: utf-8 --,意义是: 以utf-8编码储存字符。
- Unicode是集所有语言字符的查询表,ASCII只有英文字母字符和数字。
- Utf-8是被最广泛应用的一种编码方案,编码长度从1到16不等。
- gbk是主要用于中文的编码方案
- decode(): 将其他形式的编码解码为Unicode
- encode(): 将Unicode编码为其他形式
读取

写入

读取字典
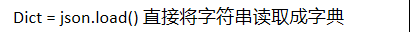
完成代码
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









