







代码终于写完了,bug 处理好了,终于跑起来了。但是模型不收敛。或者收敛了,但是加 trick 也表现不良。看着这个精心编写的辣鸡模型,从内心深处生出一股恨铁不成钢的悲愤。
于是开始思考,为什么?哪里出了问题?
- 超参数是不是有问题?(最悲伤的是调了超参数,试了几组,发现一开始直觉设置的反而是最好的……)
- 是不是模型结构有问题?(于是开始怀疑自己,难道真的是我的模型结构有问题吗?)
- 或者是模型代码有问题?(mask 加了吗?残差结构加了吗?……)
- 果然还是训练代码有 bug 吧
因此就整理了这个文章,用来辅助自查模型到底哪里出了问题。(有时候是模型结构的问题,有时候真的是因为过度关注模型结构,每次写训练代码都是套模板,不往心里去,其实是训练过程有问题)
首先捋一下,深度学习模型训练过程:
- 定义数据集
- 定义模型
- 前向过程
- 反向过程计算梯度
- 梯度更新
那么可以从以上过程排查,是不是遗漏了什么。
最后,加一个灵魂提问:如果你用了分布式训练,你真的明白分布式训练在做什么吗?还是直接搜了一个模板代码能跑就行呢……
文章目录
检查代码 bug
数据预处理
- 数据的格式正确:如果用了预训练大模型提取特征,那么你用的数据格式要和训练的模型保持一致
- 图片数据:三个通道是不是正确?resize是否正确?是 float32 还是 float64 还是 uint8?有没有做过归一化?
- 文本数据:是不是用了同一个 tokenizer?(不同的 tokenizer 的单词的 id 编码不同,如果是用预训练文本特征提取器,一定要保证一致)
- 数据真值对应:输入和输入是不是对上的
- 特别是用了数据增广之后,还是不是对上的?
- 有box的任务,box的数据是xyxy类型还是xywh类型,别弄错了
- 数据处理的位置要明确
- 有些代码把数据处理写在
__get_item__(); - 有些写在
train()那一长串里面,以 transforms 的形式传到 dataset 里面; - 有些写在 Dataloader 的
collate_fn参数里; - 有些用了 transformers 等库,以
processor等形式传到 dataset 里面;
- 有些代码把数据处理写在
定义模型
- 模型结构上的小细节
- 各种 norm
- 残差结构
- dropout
- 各种 mask(padding mask、causal mask)
- position embedding
- attention 那个除以根号 d
- 激活函数
- 预训练模型,参数是不是读进去了
- 训练的时候,哪些层梯度要更新、哪些层冻住,写好了没?
- loss 计算:
- 计算 loss 时传进去的数据对不对?预测结果和真值是不是可以直接一起比较,还是真值也需要经过某些预处理(归一化之类)?
- loss 到底在哪个地方计算?有些人在 model 的
forward()方法里面直接返回 loss,有些是前向过程结束返回预测结果,在train()里面再计算 loss;
训练过程
debug和复现需要的设置
- logger 写好没?
- model_config 和 train_config 存成本地文件了没?
- 随机数种子,是不是 random, np.random, torch.random 都固定了
optimizer 和 lr
首先要理清这俩的关系,去掉花里胡哨的 tricks,这俩的调用方法是这样的:
# 随便选的一个 optimizer 实例化
# 这里的参数,model.parameters() 是要更新的参数,必须传
# lr 是必须传进去的
# 其它的参数是不同的 optimizer 可能不同,不关注 tricks 的话不用管
# [1] 实例化 optimizer
optimizer = torch.optim.Adadelta(model.parameters(), lr=1.0, rho=0.9, eps=1e-06, weight_decay=0.1)
# 随便选的一个 lr_scheduler 实例化
# 这里 optimizer 是必须传的参数,别的参数因 lr_scheduler 不同而不同,在这不是重点
# [2] 实例化 lr_scheduler
lr_sche = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)
for epoch in range(num_epoch):
for batch_data in train_dataloader
# [3] 已经更新过的梯度清零,防止影响下次梯度更新
optimizer.zero_grad()
# [4] 前向过程计算损失
loss = model(**batch_data)
# [5] 反向过程计算梯度
loss.backward()
# [6] 利用计算的梯度,根据学习率更新梯度
optimizer.step()
# [7] 学习率按照计划更新
lr_sche.step()
optimizer
首先解析 optimizer
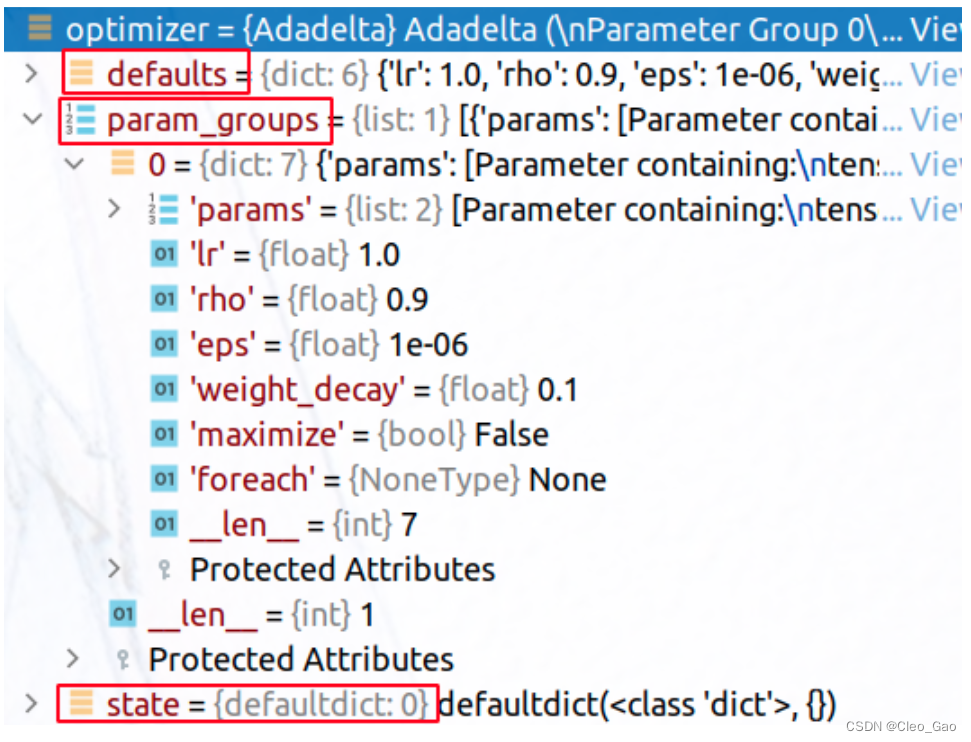
optimizer 内维护了 3 个变量:
- defaults
- param_groups:是
List[dict]类型的数据,这个dict里面存了要更新的模型参数、更新这个参数需要的超参数(比如说学习率、weight decay 之类的) - state: 这是个默认值为 dict 的字典(字典套娃);其中保存的是optimizer更新变量过程中计算出的最新的相关缓存变量。key是这些缓存的地址,value也是一个字典,key是缓存变量名,value是相应的tensor。
举例,模型是一个 model = torch.nn.Linear(10, 10) ,模型参数传进去,得到的 optimizer 内部的信息:
 展开看可训练的模型参数:
展开看可训练的模型参数:

把模型看成 y = wx+b,那么其中 shape=(10, 10) 的是 w,shape=(10, ) 的是 b
每个 optimizer 子类都要实现 step() 方法,执行单步的梯度更新操作。进一步学习:torch.optim.optimizer源码阅读和灵活使用 (这里给了一个源码例子,看看 step() 方法里到底做了什么)
lr_scheduler
参考:torch.optim.lr_scheduler源码和cosine学习率策略学习
- lr_scheduler在构造函数中主要是获取optimizer并向其添加step计数功能,然后更新一次学习率。
- step函数主要进行lr的实时计算以及相关参数的更新,包括epoch、lr和optimizer中保存的实时lr。
超参数设置的问题
除了代码有 bug 导致你的模型表现不好,还可能是超参设置有问题。超参有问题,你往上加 trick 也无济于事呀(流泪)
超参怎么设还是经验问题,这里就放一些别人的经验。搜集到新的再慢慢更新。
关于 batch size 和 lr
观点:batch size 和 learning rate 要等比例放大
看到很多人这么说,于是去查了下原理。一般谈论 batch size 对训练过程的影响,会说:
- 小的 batch size 计算得到的噪声多(这个很好理解,比如 batch size=1,那就是贴着这个数据的梯度方向下降,肯定会把这个数据中的噪声带进去)
- 过大的 batch size 表现不一定好。不仅仅是说泛化性不好,val表现变差;在 train 数据集上也会变差
- 一个解释是,因为大的 batch size 下降到鞍部就不再下降了,而小的 bs 还会探索别的梯度下降的方向。
这篇文章:如何选择模型训练的batch size和learning rate
写得非常好,给出的结论是:
- batchsize变大 k k k 倍,学习率也要相应变大 k \sqrt{k} k 倍,本质是为了梯度的方差保持不变;
- 如果增加了学习率,那么batch size最好也跟着增加,这样收敛更稳定。
- 尽量使用大的学习率,因为很多研究都表明更大的学习率有利于提高泛化能力。如果真的要衰减,可以尝试其他办法,比如增加batch size,学习率对模型的收敛影响真的很大,慎重调整。
分布式训练
分布式字面上很好理解,就是同时训练。搜资料最多的也是说,有把模型拆成两部分训练的、有把数据拆成两部分训练的,等等。
但是我还有有些概念搞不清楚,导致我无法把控我的训练过程中是不是出现了梯度整合的错误,导致模型训练的错误。
我的疑问是:
- 分布式训练是多线程还是多进程?
- 怎么保证分布式训练时候的数据安全性?(包括训练数据、梯度、optimizer、lr_scheduler)
- 常见的分布式训练的方法是什么?参数怎么设置?
先不说在pytorch上的框架(lightning 等),pytorch 提供的分布式训练有两种方法:
nn.DataParallel- 简单
- 只能数据分布式训练
- 单进程多线程
nn.DistributedDataParallel- 支持数据分布式、模型分布式
- 多进程
- 每个进程都有独立的优化器,执行自己的更新过程,但是梯度通过通信传递到每个进程,所有执行的内容是相同的;
现在一般都推荐使用 nn.DistributedDataParallel
DistributedDataParallel内部机制
(这里以数据分布式训练讲解,没有考虑模型分布式训练)
DistributedDataParallel 在多个GPUs间复制模型,每个GPU都由一个进程控制。GPU可以都在同一个节点上,也可以分布在多个节点上(这里的节点,应该说的是主机)。
不同进程拿到的是相同的模型、不同的数据,需要在正向传播时对数据的分配进行调整,所以dataloader里面多了一个sampler参数。
在多机多卡情况下分布式训练数据的读取也是一个问题,不同的卡读取到的数据应该是不同的。dataparallel的做法是直接将batch切分到不同的卡,这种方法对于多机来说不可取,因为多机之间直接进行数据传输会严重影响效率。于是有了利用sampler确保dataloader只会load到整个数据集的一个特定子集的做法。DistributedSampler就是做这件事的。它为每一个子进程划分出一部分数据集,以避免不同进程之间数据重复。
每个进程都执行相同的任务,并且每个进程都与所有其他进程通信。进程或者说GPU之间只传递梯度,这样网络通信就不再是瓶颈。
什么时候整合多张卡的计算结果?
首先看看数据流(图片来源:PyTorch分布式训练基础–DDP使用)
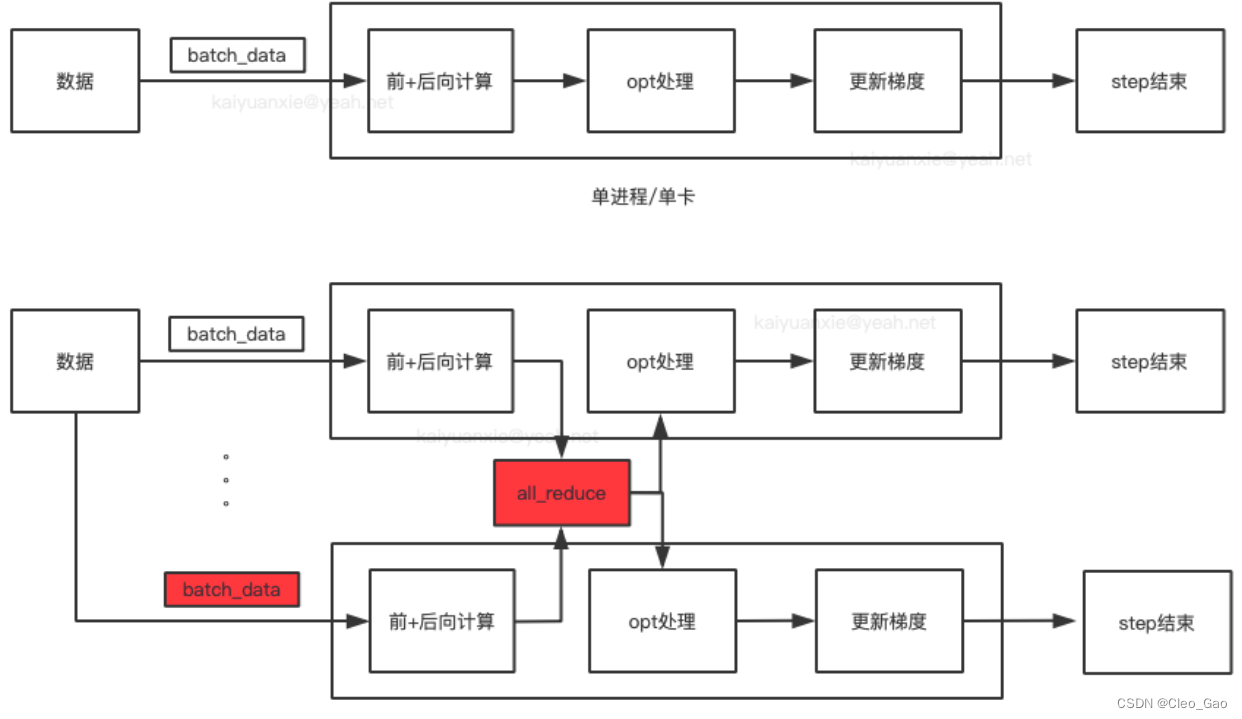 所以每张卡算出来 loss 之后,要先整合大家计算的 loss 结果,得到一个梯度,然后把这个梯度告诉所有人,完成梯度更新。(也就是说,大家跑的数据是不同的,但是更新的梯度是一致的。)
所以每张卡算出来 loss 之后,要先整合大家计算的 loss 结果,得到一个梯度,然后把这个梯度告诉所有人,完成梯度更新。(也就是说,大家跑的数据是不同的,但是更新的梯度是一致的。)
还有一些需要处理的地方,比如大部分情况下,分布式的进程之间执行的都是相同的代码,但是有些只需处理一次的工作,比如ckpt的保存,就需要指定单个进程来完成。 于是需要对进程进行编号,指定特定编号的进程去完成特定的工作,这个编号是rank。
分布式训练中的各种参数
- rank:用于表示进程的编号/序号(在一些结构图中rank指的是软节点,rank可以看成一个计算单位),每一个进程对应了一个rank的进程,整个分布式由许多rank完成。
- rank与GPU之间没有必然的对应关系,一个rank可以包含多个GPU;一个GPU也可以为多个rank服务(多进程共享GPU)。
- node:物理节点,可以是一台机器也可以是一个容器,节点内部可以有多个GPU。
- rank与local_rank: rank是指在整个分布式任务中进程的序号;local_rank是指在一个node上进程的相对序号,local_rank在node之间相互独立。
- nnodes、node_rank与nproc_per_node:nnodes是指物理节点数量,node_rank是物理节点的序号;nproc_per_node是指每个物理节点上面进程的数量。
- node_rank 是和 node, nnodes 一起命名的,和 rank 没关系
- word size : 全局(一个分布式任务)中,rank的数量。
还有一些与通信相关的参数(多机训练肯定要通信的呀)
- backend :通信后端,可选的包括:
nccl(NVIDIA推出)、gloo(Facebook推出)、mpi(OpenMPI)。从测试的效果来看,如果显卡支持nccl,建议后端选择nccl,其它硬件(非N卡)考虑用gloo、mpi(OpenMPI)。 - master_addr与master_port:主节点的地址以及端口,供init_method 的tcp方式使用。 因为pytorch中网络通信建立是从机去连接主机,运行ddp只需要指定主节点的IP与端口,其它节点的IP不需要填写。 这个两个参数可以通过环境变量或者init_method传入。
分布式训练中 batch size 的设置
除了分布式训练本身的参数设置,还要考虑到别的参数随着分布式训练要进行的变动。
补充资料(可看看):
- 深度学习多机多卡batchsize和学习率的关系: 发现单机多卡和多机多卡即使全局batchsize对齐训练结果仍有较大的diff,实验结果是差了2个多点。
以前总是听到学习率和batchsize成正比例变化这样的说法,之前做reid实验的时候确实是这么回事:记得当时作者的模型是四卡DP模式训练的全局batchsize是256,相当于每张卡上的batchsize是64.作者的学习率是0.00375我复现的实验因为实验室没有卡只能用两卡实验,修改全局batchsize为128,学习率0.001875,然后还有个重要的参数,就是每个epoch遍历的iter数,因为作者的dataloader是iterloader,就是说一个epoch不是见过了所有的数据就结束,而是达到我制定的iter数目才结束,所以一个epoch可能会见到一两遍全部的数据。然后作者的iter数目设置的是400,我因为一个iter的bs只有128了,所以iter的数目设置了他的两倍就是800.修改上述三个参数实验结果和作者对齐了。reid这种任务因为要充分挖掘一个batch里面正负样本的信息,所以受到batchsize很大的影响,上述三个参数不管哪个不对都会很大的影响最后的结果。
这里让我疑惑的地方是,一个 batch 的数据送进去,计算出来的梯度是这个 batch 的数据的 sum,而不会除以 bs 的大小做平均吗?
搜到了这个问题:pytorch 如何实现梯度累积?。提问人说“因为受限于gpu资源,一次能跑起来的bath_size较小。所以想通过梯度累积的方式来解决这个问题。”并且贴了自己的代码。
我看他的代码里面在反向传播计算梯度之间,做了 loss /= batch_size
有人回答的时候贴出交叉熵损失的官方 api 接口:
torch.nn.BCELoss(weight=None, size_average=None, reduce=None, reduction='mean')
这里写了个参数:reduction='mean' (我发现我居然一直都没有注意过这个参数)
这里有一个至关重要的默认参数 “reduction”,它的值必须是 none,mean,sum 中的任意一个。
所以结论是:如果实例化 loss_function 的时候,传进去的参数是 mean,那么一定要注意,mean 的维度是不是正确的(如果是 sum,也要注意 sum 的 dim);如果已经是 mean 参数了,那么自己再做 loss /= batch_size 就没意义
另一个人说:
batch size 和 learning rate 要等比例放大。如果遵从了这个原则,loss 那里就没必要除以 batch size。如果累积了 batch 但 learning rate 没变,那在 loss 那里改一下也是等效的。
但需要注意:特别大的 batch size 还需要再加上其他 trick 如 warmup 才能保证训练顺利(因为太大的初始 lr 很容易 train 出 nan)
另外有时间也可以看看:
分布式训练的参考资料
- PyTorch分布式训练基础–DDP使用:写了单机多卡、多机多卡的方法(各种参数的说明、还有常用的函数),很详细,非常好
- Pytorch多机多卡分布式训练:分享了多机多卡设置节点时候的坑。单机多卡的可以不看。
- Pytorch 分布式训练: 整理性质的,写得也蛮细致全面的
- 记录使用Pytorch分布式训练(torch.distributed)踩过的坑: 分享了遇到的坑:因为 Sampler 设置错误导致不同进程的loss不一致















 1202
1202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









