








本文字数:11002;估计阅读时间:28 分钟
审校:庄晓东(魏庄)
本文在公众号【ClickHouseInc】首发
您能相信已经是三月了吗?时间过得飞快,但好处就是我们又有一个 ClickHouse 版本供您享用了!
ClickHouse 24.2 版本包含了 18 个新功能 🎁 18 个性能优化 🛷 49 个bug修复 🐛
新贡献者
像往常一样,我们特别欢迎所有在 24.2 版中的新贡献者!ClickHouse 的受欢迎程度在很大程度上归功于社区的努力贡献。看到这个社区不断壮大总是令人感到自豪的。
以下是新贡献者的名字:
johnnymatthews, AlexeyGrezz, Aris Tritas, Charlie, Fille, HowePa, Joshua Hildred, Juan Madurga, Kirill Nikiforov, Nickolaj Jepsen, Nikolai Fedorovskikh, Pablo Musa, Ronald Bradford, YenchangChan, conicliu, jktng, mikhnenko, rogeryk, una, Кирилл Гарбар_
提示:如果您想知道我们是如何生成这个列表的...请点击这里(https://gist.github.com/gingerwizard/5a9a87a39ba93b422d8640d811e269e9)。
如果您在这里看到了您的名字,请与我们联系...不过我们也会在 Twitter 等地方找到您。
您也可以在 YouTube 上查看本次版本视频,查看演示文稿的幻灯片。(https://presentations.clickhouse.com/release_24.2/#)
好的,让我们进入功能介绍吧!
自动检测文件格式
由 Pavel Kruglov 贡献
在处理文件时,即使文件没有有效的扩展名,ClickHouse 也会自动检测文件的类型。例如,以下文件 foo 包含了 JSON 行格式的数据:
$ cat foo
{"name": "John Doe", "age": 30, "city": "New York"}
{"name": "Jane Doe", "age": 25, "city": "Los Angeles"}
{"name": "Jim Beam", "age": 35, "city": "Chicago"}
{"name": "Jill Hill", "age": 28, "city": "Houston"}
{"name": "Jack Black", "age": 40, "city": "Philadelphia"}我们尝试使用 file 函数处理该文件:
SELECT *
FROM file('foo')
┌─name───────┬─age─┬─city─────────┐
│ John Doe │ 30 │ New York │
│ Jane Doe │ 25 │ Los Angeles │
│ Jim Beam │ 35 │ Chicago │
│ Jill Hill │ 28 │ Houston │
│ Jack Black │ 40 │ Philadelphia │
└────────────┴─────┴──────────────┘
5 rows in set. Elapsed: 0.003 sec.非常酷。现在让我们将内容写入 Parquet 格式:
SELECT *
FROM file('foo')
INTO OUTFILE 'bar'
FORMAT Parquet我们可以在不告诉 ClickHouse 文件格式的情况下读取它吗?
SELECT *
FROM file('bar')
┌─name───────┬─age─┬─city─────────┐
│ John Doe │ 30 │ New York │
│ Jane Doe │ 25 │ Los Angeles │
│ Jim Beam │ 35 │ Chicago │
│ Jill Hill │ 28 │ Houston │
│ Jack Black │ 40 │ Philadelphia │
└────────────┴─────┴──────────────┘
5 rows in set. Elapsed: 0.003 sec.当然可以!自动检测功能在从 URL 读取时同样适用。所以如果我们在上述文件周围启动一个本地 HTTP 服务器:
python -m http.server然后我们可以像这样读取它们:
SELECT *
FROM url('http://localhost:8000/bar')
┌─name───────┬─age─┬─city─────────┐
│ John Doe │ 30 │ New York │
│ Jane Doe │ 25 │ Los Angeles │
│ Jim Beam │ 35 │ Chicago │
│ Jill Hill │ 28 │ Houston │
│ Jack Black │ 40 │ Philadelphia │
└────────────┴─────┴──────────────┘这就是现在的足够的示例,但您也可以将此功能与 s3、hdfs 和 azureBlobStorage 表函数一起使用。
漂亮格式更漂亮了
RogerYK
如果您曾经需要快速解释查询结果中的大数字,那么这个功能就适合您。当您返回单个数字列时,如果该列中的值大于一百万,则可读数量将作为注释显示在值本身旁边。
SELECT 765432198
┌─765432198─┐
│ 765432198 │ -- 765.43 million
└───────────┘
视图的安全性
由 Artem Brustovetskii 贡献
在此版本之前,如果您在表上定义了视图,要想用户访问该视图,他们还需要访问该表。这不是理想的情况,在 24.2 版本中,我们为 CREATE VIEW 查询添加了 SQL SECURITY 和 DEFINER 规范,以解决这个问题。
假设我们有一个公司的工资表,其中包含员工的姓名、部门、工资和地址详情。我们可能希望允许人力资源团队访问所有信息,但也允许其他用户查看员工姓名和部门。
让我们首先创建一个表并填充它:
CREATE TABLE payroll (
name String,
address String,
department LowCardinality(String),
salary UInt32
)
Engine = MergeTree
ORDER BY name;
INSERT INTO payroll (`name`, `address`, `department`, `salary`) VALUES
('John Doe', '123 Maple Street, Anytown, AT 12345', 'HR', 50000),
('Jane Smith', '456 Oak Road, Sometown, ST 67890', 'Marketing', 55000),
('Emily Jones', '789 Pine Lane, Thistown, TT 11223', 'IT', 60000),
('Michael Brown', '321 Birch Blvd, Othertown, OT 44556', 'Sales', 52000),
('Sarah Davis', '654 Cedar Ave, Newcity, NC 77889', 'HR', 53000),
('Daniel Wilson', '987 Elm St, Oldtown, OT 99000', 'IT', 62000),
('Laura Martinez', '123 Spruce Way, Mytown, MT 22334', 'Marketing', 56000),
('James Garcia', '456 Fir Court, Yourtown, YT 33445', 'Sales', 51000);我们有两个用户 - Alice 是人力资源团队的成员,Bob 是工程团队的成员。Alice 在人力资源团队中,并且可以访问工资表,而 Bob 则不行!
CREATE USER alice IDENTIFIED WITH sha256_password BY 'alice';
GRANT SELECT ON default.payroll TO alice;
GRANT SELECT ON default.employees TO alice WITH GRANT OPTION;
CREATE USER bob IDENTIFIED WITH sha256_password BY 'bob';Alice 创建了一个名为 employees 的视图:
CREATE VIEW employees
DEFINER = alice SQL SECURITY DEFINER
AS
SELECT name, department
FROM payroll;然后 Alice 将该视图的访问权限授予了自己和 Bob:
GRANT SELECT ON default.employees TO alice;
GRANT SELECT ON default.employees TO bob;如果我们以 Bob 的身份登录:
clickhouse client -u bob我们可以查询 employees 表:
SELECT *
FROM employees
┌─name───────────┬─department─┐
│ Daniel Wilson │ IT │
│ Emily Jones │ IT │
│ James Garcia │ Sales │
│ Jane Smith │ Marketing │
│ John Doe │ HR │
│ Laura Martinez │ Marketing │
│ Michael Brown │ Sales │
│ Sarah Davis │ HR │
└────────────────┴────────────┘但是他无法查询底层的工资表,这是我们所预期的:
SELECT *
FROM payroll
Received exception from server (version 24.3.1):
Code: 497. DB::Exception: Received from localhost:9000. DB::Exception: bob: Not enough privileges. To execute this query, it's necessary to have the grant SELECT(name, address, department, salary) ON default.payroll. (ACCESS_DENIED)
矢量化距离函数
由 Robert Schulze 贡献
在最近的博客文章中,我们探讨了 ClickHouse 如何在用户需要高性能线性扫描以获得准确结果和/或能够通过 SQL 将向量搜索与元数据过滤和聚合相结合时,作为向量数据库使用。用户可以利用这些功能通过检索增强生成(RAG)流水线为基于 LLM 的应用程序提供上下文。我们在底层支持向量搜索方面的投入继续进行,最近的工作重点是改进计算两个向量之间距离的函数族的性能。有关背景信息,我们建议阅读这篇文章以及我们自己 Mark 的最新视频:(https://www.youtube.com/watch?v=BFtWe2xG5cU)
尽管对于较大的数据集,向量搜索的查询性能很容易受到 I/O 限制,但许多用户只需要搜索适合内存的较小数据集的 SQL。在这些情况下,ClickHouse 中的性能可能会受到 CPU 的限制。因此,确保该代码被适当地矢量化并使用最新的指令集,可以显著提高性能,并将性能限制为内存带宽 - 对于具有 DDR-5 的机器,这意味着更高的扫描性能。
在 24.2 版本中,我们很高兴地宣布,cosineDistance、dotProduct 和 L2Distance(欧几里德距离)函数都已经优化,以利用最新的指令集。对于 x86,这意味着使用了融合乘-加(FMA)和 AVX-512 指令进行水平加-减运算,并针对 ARM 进行了自动矢量化。
作为潜在改进的示例,请考虑以下在几乎正式的 ANN 基准测试中流行的 glove 数据集。这个特定的子集(我们已经提供了 Parquet 格式,大小为 2.5GiB),包含了从 840B CommonCrawl 标记中训练的 2.1m 个向量。该集合中的每个向量都有 300 维,并表示一个单词。鉴于简单的架构,这需要几秒钟加载到 ClickHouse 中:
CREATE TABLE glove
(
`word` String,
`vector` Array(Float32)
)
ENGINE = MergeTree
ORDER BY word;
INSERT INTO glove SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/glove/glove_840b_300d.parquet')
0 rows in set. Elapsed: 49.779 sec. Processed 2.20 million rows, 2.66 GB (44.12 thousand rows/s., 53.44 MB/s.)
Peak memory usage: 1.03 GiB.机器规格:
i3en.3xlarge - 12vCPU Intel(R) Xeon(R) Platinum 8259CL CPU @ 2.50GHz,96GiB RAM
我们可以通过找到与特定单词的向量最接近的单词,来比较不同版本 ClickHouse 的性能。例如,在 23.12 版本中:
WITH 'dog' AS search_term,
(
SELECT vector
FROM glove
WHERE word = search_term
LIMIT 1
) AS target_vector
SELECT word, cosineDistance(vector, target_vector) AS score
FROM glove
WHERE lower(word) != lower(search_term)
ORDER BY score ASC
LIMIT 5
┌─word────┬──────score─┐
│ dogs │ 0.11640692 │
│ puppy │ 0.14147866 │
│ pet │ 0.19425482 │
│ cat │ 0.19831467 │
│ puppies │ 0.24826884 │
└─────────┴────────────┘
5 rows in set. Elapsed: 0.407 sec. Processed 2.14 million rows, 2.60 GB (5.25 million rows/s., 6.38 GB/s.)
Peak memory usage: 248.94 MiB.这里重要的是这个数据集适合文件系统缓存,如其在磁盘上的压缩大小所示:
SELECT
name,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size,
round(sum(data_uncompressed_bytes) / sum(data_compressed_bytes), 2) AS ratio
FROM system.columns
WHERE table LIKE 'glove'
GROUP BY name
ORDER BY name DESC
┌─name───┬─compressed_size─┬─uncompressed_size─┬─ratio─┐
│ word │ 13.41 MiB │ 18.82 MiB │ 1.4 │
│ vector │ 2.46 GiB │ 2.47 GiB │ 1 │
└────────┴─────────────────┴───────────────────┴───────┘
2 rows in set. Elapsed: 0.003 sec.单词列和向量列的总大小约为 2.65 GB,完全适合内存。
在 24.2 版本中,同样的查询性能提高了超过 25%:
5 rows in set. Elapsed: 0.286 sec. Processed 1.91 million rows, 2.32 GB (6.68 million rows/s., 8.12 GB/s.)
Peak memory usage: 216.89 MiB.这些差异将根据处理器、数据集大小、向量基数和内存性能而变化。
关于点积的一小点说明
在 24.2 版本之前,dotProduct 函数没有被矢量化。在确保这一点尽可能高效的同时,我们注意到该函数还执行了任何常量参数的必要解包操作(最常见的用例即我们传递一个常量向量进行比较),这导致了不必要的内存复制。这意味着实际函数运行时间主要受内存操作的影响 - 在这种情况下,矢量化只是相对较小的收益。一旦消除了这一点,基准测试的性能就提高了惊人的 270 倍!
虽然与以前版本的这个函数进行性能比较并不值得(它们有点令人尴尬 :)),但我们认为利用这些改进的机会可以展示出用户现在可以利用的一个很好的性能优化。
读者可能还记得余弦距离和点积之间的密切关系。更具体地说,余弦距离测量多维空间中两个向量之间的夹角的余弦。它是从余弦相似度导出的,其中余弦距离定义为 1 - 余弦相似度。余弦相似度计算为向量的点积除以它们的大小的乘积,即 1- ((a.b)/||a||||b||)。相反,点积测量两个数字序列的对应条目的乘积的总和,即具有分量 ai 和 bi 的向量 A 和 B 的点积为 A⋅B=∑aibi。
当规范化向量时(即两个向量的大小都为 1 时),余弦距离和点积变得特别相关。在这种情况下,余弦相似度实际上就是点积,因为余弦相似度公式中的分母(向量的大小)都是 1,从而相互抵消。因此,我们的余弦距离简单地变为 1-(a.b)。
我们如何利用这一点?
我们可以在插入时使用 L2Norm 函数(向量大小)对我们的向量进行规范化,从而使我们能够在查询时使用 dotProduct 函数。这样做的主要动机是 dotProduct 函数的计算更简单(我们不必为每个向量计算大小),因此可能节省一些查询时间。
要在查询时执行规范化:
INSERT INTO glove
SETTINGS schema_inference_make_columns_nullable = 0
SELECT
word,
vector / L2Norm(vector) AS vector
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/glove/glove_840b_300d.parquet')
SETTINGS schema_inference_make_columns_nullable = 0
0 rows in set. Elapsed: 51.699 sec. Processed 2.20 million rows, 2.66 GB (42.48 thousand rows/s., 51.46 MB/s.)我们之前的查询变成了:
WITH
'dog' AS search_term,
(
SELECT vector
FROM glove
WHERE word = search_term
LIMIT 1
) AS target_vector
SELECT
word,
1 - dotProduct(vector, target_vector) AS score
FROM glove
WHERE lower(word) != lower(search_term)
ORDER BY score ASC
LIMIT 5
┌─────────┬─────────────────────┐
│ word │ score │
├─────────┼─────────────────────┤
│ dogs │ 0.11640697717666626 │
│ puppy │ 0.1414787769317627 │
│ pet │ 0.19425475597381592 │
│ cat │ 0.19831448793411255 │
│ puppies │ 0.24826878309249878 │
└─────────┴─────────────────────┘
5 rows in set. Elapsed: 0.262 sec. Processed 1.99 million rows, 2.42 GB (7.61 million rows/s., 9.25 GB/s.)
Peak memory usage: 226.29 MiB.与使用余弦相似度时相比,该查询耗时 0.262 秒,是原始查询的小时间节省,但每一毫秒都很重要!
还有一个 PR 仍在进行中(https://github.com/ClickHouse/ClickHouse/pull/60928),它将修复 dotProduct 函数的正确性和性能问题,该 PR 应该很快合并。
自适应异步插入
由 Julia Kartseva 贡献
在传统的插入查询中,数据是同步插入到表中的:当 ClickHouse 收到查询时,数据会立即以数据part的形式写入到数据库存储中。为了获得最佳性能,数据需要进行批处理,通常情况下,我们应该避免创建过多的小插入并频繁执行。
异步插入将数据批处理从客户端转移到服务器端:插入查询的数据首先插入到缓冲区中,然后稍后或异步地写入到数据库存储中。这是非常方便的,特别是对于许多并发客户端频繁向表中插入数据、需要实时分析数据并且客户端批处理引起的延迟是不可接受的情况。例如,可观察性用例经常涉及数千个监控代理持续发送少量事件和指标数据。这样的场景可以利用异步插入模式,如下图所示:
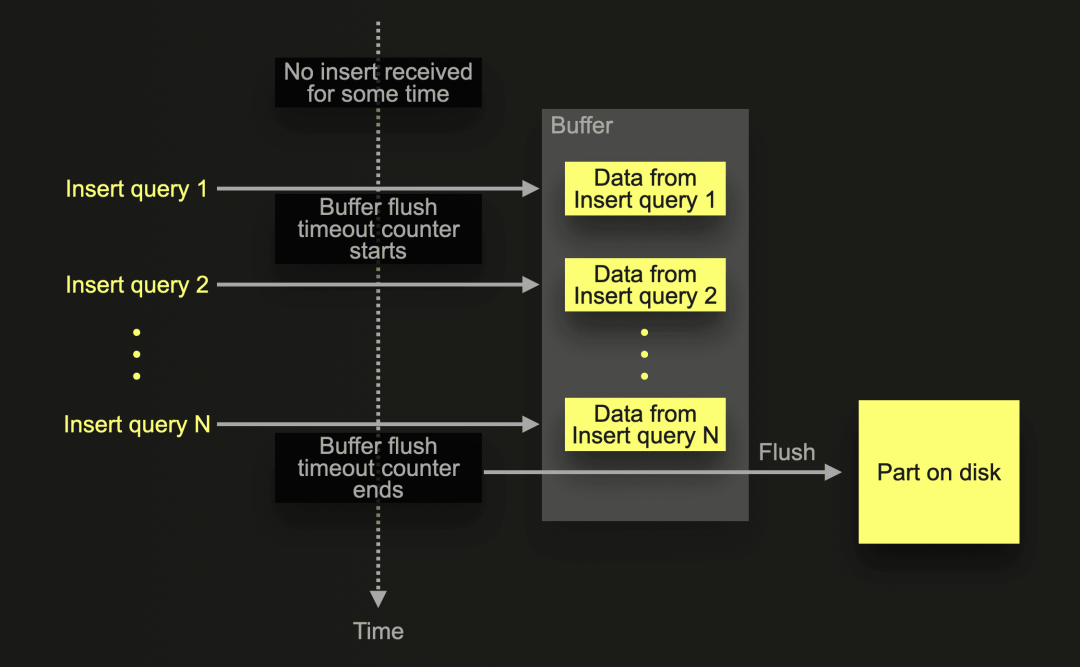
在上述示意图的示例场景中,ClickHouse 在一段时间内没有插入活动后,收到特定表的异步插入1。在收到插入1 后,插入的数据被首先插入到内存缓冲区中,并且默认缓冲区刷新超时计数器开始。在计数器结束之前,即缓冲区被刷新之前,可以收集来自相同或其他客户端的其他异步插入的数据到缓冲区中。刷新缓冲区将在磁盘上创建一个数据part,其中包含在刷新之前接收的所有插入查询的组合数据。
请注意,根据默认返回行为,所有插入只有在缓冲区刷新发生后才会返回给发送方插入的确认。换句话说,发送插入查询的客户端端调用将被阻塞,直到下一个缓冲区刷新发生。因此,不经常插入的插入具有更高的延迟。我们在下面进行了简述:

在上述极端情况下,显示了不频繁的插入查询。ClickHouse 在表的插入活动停止一段时间后收到了异步插入查询 1。这触发了一个新的缓冲区刷新周期,使用默认的缓冲区刷新超时,这意味着该查询的发送者需要等待完整的默认缓冲区刷新时间(OSS 为 200 毫秒,ClickHouse Cloud 为 1000 毫秒)才能收到插入的确认。同样,插入查询 2 的发送者也会遇到较高的插入延迟。
ClickHouse 24.2 中引入的自适应异步插入缓冲区刷新超时通过使用自适应算法根据插入频率自动调整缓冲区刷新超时来解决这个问题:
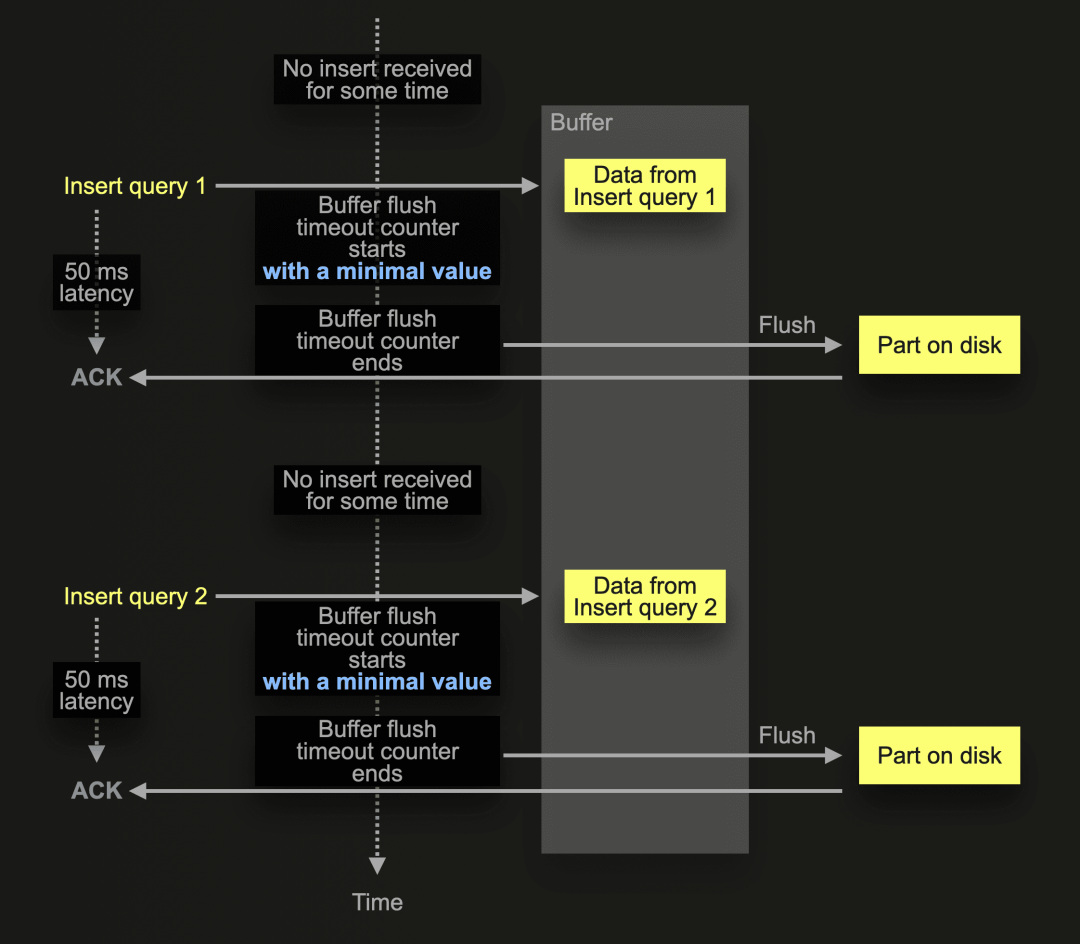
对于以前显示的极端情况,其中存在一些不频繁的插入查询,现在缓冲区刷新超时计数器将从最小值(50 毫秒)开始。因此,来自这些查询的数据将更快地写入磁盘。将较小的数据量几乎立即写入磁盘是可以接受的,因为频率很低。因此,没有风险触发too many parts保护机制。
频繁的插入与以前一样工作。它们将被延迟并合并:
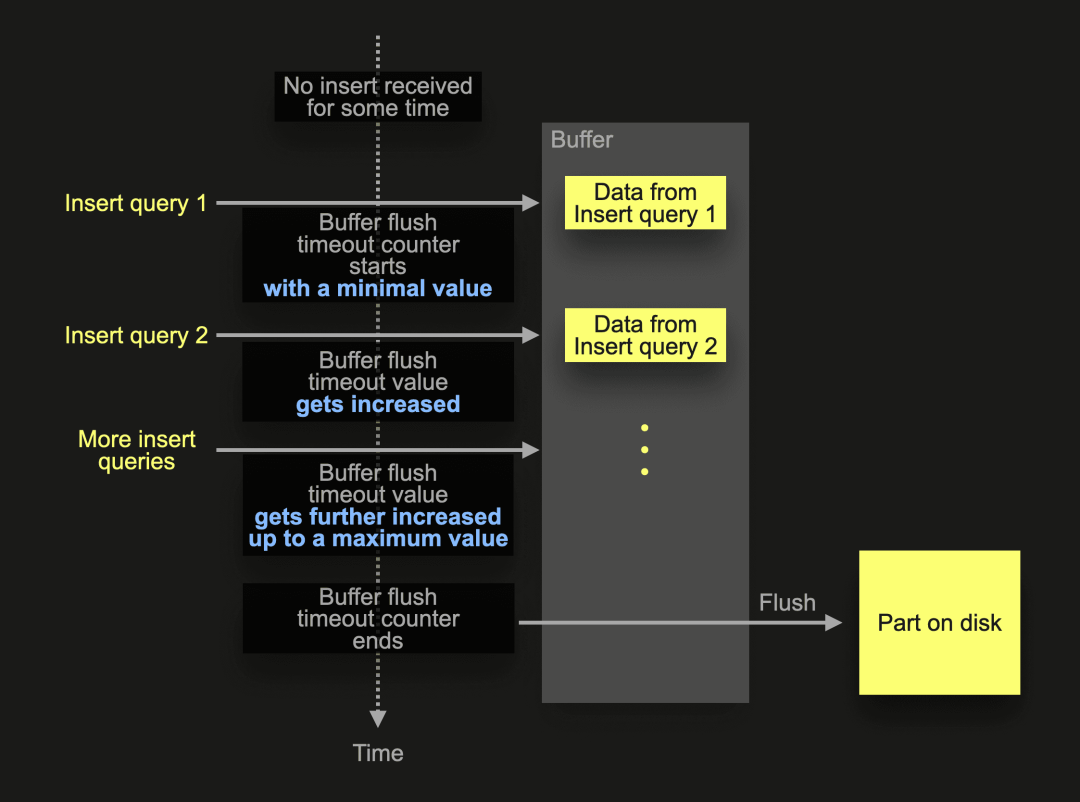
当 ClickHouse 在一段时间内没有插入活动的情况下收到插入查询 1 时,缓冲区刷新超时计数器将从最小值开始,并在频繁发生额外插入时自动调整到最大值(当插入频率降低时也会相应调整回来)。
总之,频繁的插入与以前一样工作。它们将被延迟并合并在一起。然而,不频繁的插入不会延迟太多,并且会像同步插入一样表现。您只需启用异步插入,不用再担心了。😀
让我们通过一个例子来演示这一点。为此,我们启动一个 ClickHouse 24.2 实例,并创建我们的 UpClick 可观察性示例应用程序的简化版本表:
CREATE TABLE default.upclick_metrics (
`url` String,
`status_code` UInt8,
`city_name_en` String
) ENGINE = MergeTree
ORDER BY (url, status_code, city_name_en);现在我们可以使用这个简单的 Python 脚本(使用 ClickHouse Connect Python 驱动程序)向我们的 ClickHouse 实例发送 10 个小的异步插入。请注意,我们通过将 wait_for_async_insert 设置为 1 明确启用了默认的返回行为,并将缓冲区刷新超时增加到 2 秒(以更好地演示自适应异步插入)。
import clickhouse_connect
import time
client = clickhouse_connect.get_client(...)
for _ in range(10):
start_time = time.time()
client.insert(
database='default',
table='upclick_metrics',
data=[['clickhouse.com', 200, 'Amsterdam']],
column_names=['url', 'status_code', 'city_name_en'],
settings={
'async_insert':1,
'wait_for_async_insert':1,
'async_insert_busy_timeout_ms':2000,
'async_insert_use_adaptive_busy_timeout':0}
)
end_time = time.time()
print(str(round(end - start, 2)) + ' seconds')
time.sleep(1)该脚本测量并打印每个插入的延迟(以秒为单位),然后休眠一秒以模拟不频繁的插入。
我们使用禁用的自适应异步插入缓冲区刷新超时(async_insert_use_adaptive_busy_timeout 设置为 0)运行脚本,并且输出结果如下:
2.03 seconds
2.02 seconds
2.03 seconds
2.02 seconds
2.04 seconds
2.02 seconds
2.03 seconds
2.03 seconds
2.03 seconds
2.03 seconds我们可以看到不频繁插入的高延迟为 2 秒。
然而,当我们使用启用的自适应异步插入缓冲区刷新超时(async_insert_use_adaptive_busy_timeout 设置为 1)并且所有其他设置与上述运行相同时,输出结果如下:
0.07 seconds
0.06 seconds
0.08 seconds
0.08 seconds
0.07 seconds
0.07 seconds
0.07 seconds
0.08 seconds
0.07 seconds
0.08 seconds不频繁插入的延迟大大降低了。
我们在这里没有完全看到最小的缓冲区刷新超时为 50 毫秒,这是因为来自 Python 驱动程序机制、服务器端查询解析的额外延迟开销以及发送查询到 ClickHouse 等等。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求

















 2708
2708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









