








本文字数:10726;估计阅读时间:27 分钟
审校:庄晓东(魏庄)
本文在公众号【ClickHouseInc】首发

ClickHouse 不仅支持标准的聚合函数,还提供了许多更高级的函数,以满足大多数分析用例的需求。除了聚合函数之外,ClickHouse 还提供了聚合组合器,这是对查询功能的强大扩展,可以满足大量需求。
组合器允许扩展和混合聚合以处理各种数据结构。这种能力将使我们能够调整查询而不是表,以回答甚至最复杂的问题。
在本篇博客文章中,我们将探讨聚合组合器以及它们如何潜在地简化您的查询,并避免对数据进行结构性更改的需求。
如何使用组合器
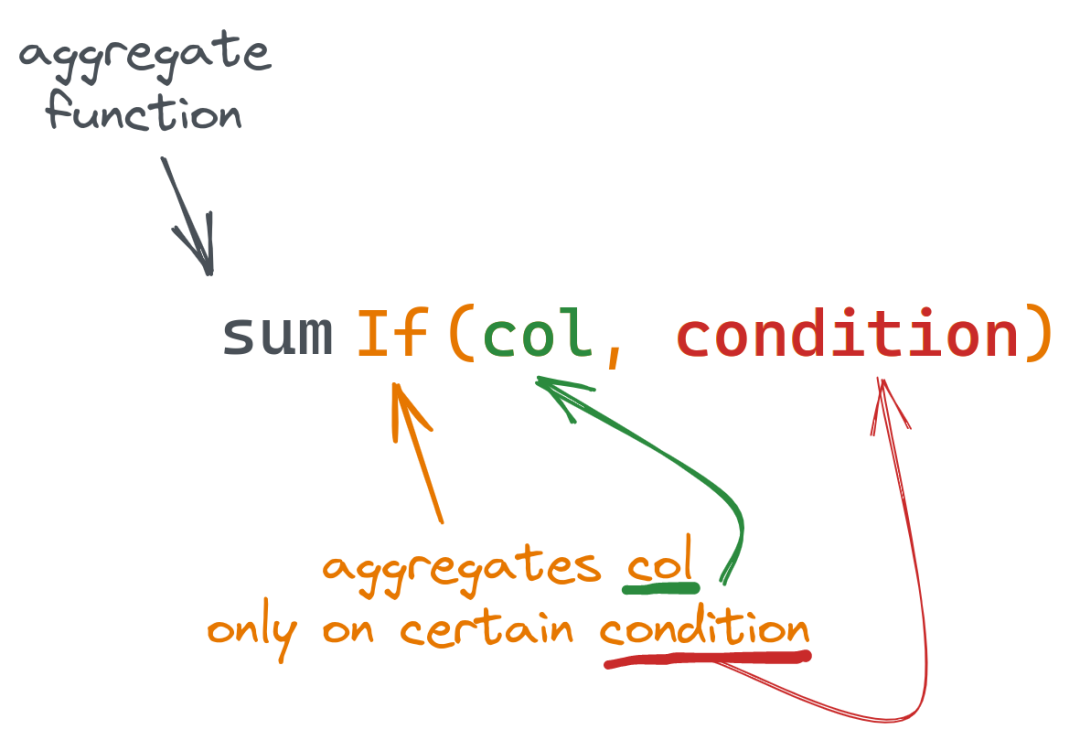
要使用组合器,我们需要做两件事。首先,选择我们想要使用的聚合函数;假设我们想要使用 sum() 函数。其次,选择我们案例所需的组合器;假设我们需要一个 If 组合器。要在查询中使用它,我们将组合器添加到函数名称中:
SELECT sumIf(...)更加实用的功能是,我们可以将任意数量的组合器组合在一个单一的函数中:
SELECT sumArrayIf(...)在这里,我们将 sum() 函数与 Array 和 If 组合器结合起来使用:

这个特定的示例将允许我们有条件地对数组列的内容进行求和。
让我们探讨一些实际案例,看看组合器可以用在哪些情况下。
向聚合添加条件
有时,我们需要根据特定条件对数据进行聚合。我们可以使用 If 组合器,并将条件指定为组合函数的最后一个参数,而不是使用 WHERE 子句:
假设我们有一个具有以下结构的用户支付表(填充了示例数据):
CREATE TABLE payments
(
`total_amount` Float,
`status` ENUM('declined', 'confirmed'),
`create_time` DateTime,
`confirm_time` DateTime
)
ENGINE = MergeTree
ORDER BY (status, create_time)假设我们想要获得总支出金额,但只有当支付已确认时,即 status="confirmed" 时:
SELECT sumIf(total_amount, status = 'confirmed') FROM payments
┌─sumIf(total_amount, equals(status, 'declined'))─┐
│ 10780.18000793457 │
└─────────────────────────────────────────────────┘我们可以使用与 WHERE 子句相同的语法来设置条件。让我们获取已确认支付的总金额,但是当 confirm_time 晚于 create_time 1 分钟时:
SELECT sumIf(total_amount, (status = 'confirmed') AND (confirm_time > (create_time + toIntervalMinute(1)))) AS confirmed_and_checked
FROM payments
┌─confirmed_and_checked─┐
│ 11195.98991394043 │
└───────────────────────┘使用条件 If 的主要优势,而不是标准的 WHERE 子句,是能够为不同的子句计算多个总和。我们还可以使用任何可用的聚合函数与组合器一起使用,如 countIf()、avgIf() 或 quantileIf() - 任何函数。结合这些功能,我们可以在单个请求中根据多个条件和函数进行聚合:
SELECT
countIf((status = 'confirmed') AND (confirm_time > (create_time + toIntervalMinute(1)))) AS num_confirmed_checked,
sumIf(total_amount, (status = 'confirmed') AND (confirm_time > (create_time + toIntervalMinute(1)))) AS confirmed_checked_amount,
countIf(status = 'declined') AS num_declined,
sumIf(total_amount, status = 'declined') AS dec_amount,
avgIf(total_amount, status = 'declined') AS dec_average
FROM payments
┌─num_confirmed_checked─┬─confirmed_checked_amount─┬─num_declined─┬────────dec_amount─┬───────dec_average─┐
│ 39 │ 11195.98991394043 │ 50 │ 10780.18000793457 │ 215.6036001586914 │
└───────────────────────┴──────────────────────────┴──────────────┴───────────────────┴───────────────────┘
仅对唯一条目进行聚合
计算唯一条目的数量是一个常见的情况。ClickHouse有几种方法可以做到这一点,可以使用 COUNT(DISTINCT col)(与 uniqExact 相同)或 uniq(),当需要估计值(但更快速)时。尽管如此,我们可能希望从不同的聚合函数中使用在列中的唯一值。可以使用 Distinct 组合器来实现这一点:

一旦将 Distinct 添加到聚合函数中,它就会忽略重复的值:
SELECT
countDistinct(toHour(create_time)) AS hours,
avgDistinct(toHour(create_time)) AS avg_hour,
avg(toHour(create_time)) AS avg_hour_all
FROM payments
┌─hours─┬─avg_hour─┬─avg_hour_all─┐
│ 2 │ 13.5 │ 13.74 │
└───────┴──────────┴──────────────┘在这里,avg_hour 将仅基于两个唯一值进行计算,而avg_hour_all 将基于表中的所有100条记录进行计算。
结合 Distinct 和 If
由于组合器可以组合在一起,我们可以将前面的组合器和avgDistinctIf函数一起使用,以处理更高级的逻辑:
SELECT avgDistinctIf(toHour(create_time), total_amount > 400) AS avg_hour
FROM payments
┌─avg_hour─┐
│ 13 │
└──────────┘这将计算记录中 total_amount 值大于400的条目的唯一小时值的平均值。
将数据分组后再进行聚合
我们可能想要将数据分成几组,然后分别计算每组的指标,而不是进行最小值/最大值分析。这可以使用 Resample 组合器来解决。
它接受一个列、范围(开始/停止)和你想要根据哪个步长来分割数据。然后,它为每个组返回一个聚合值:
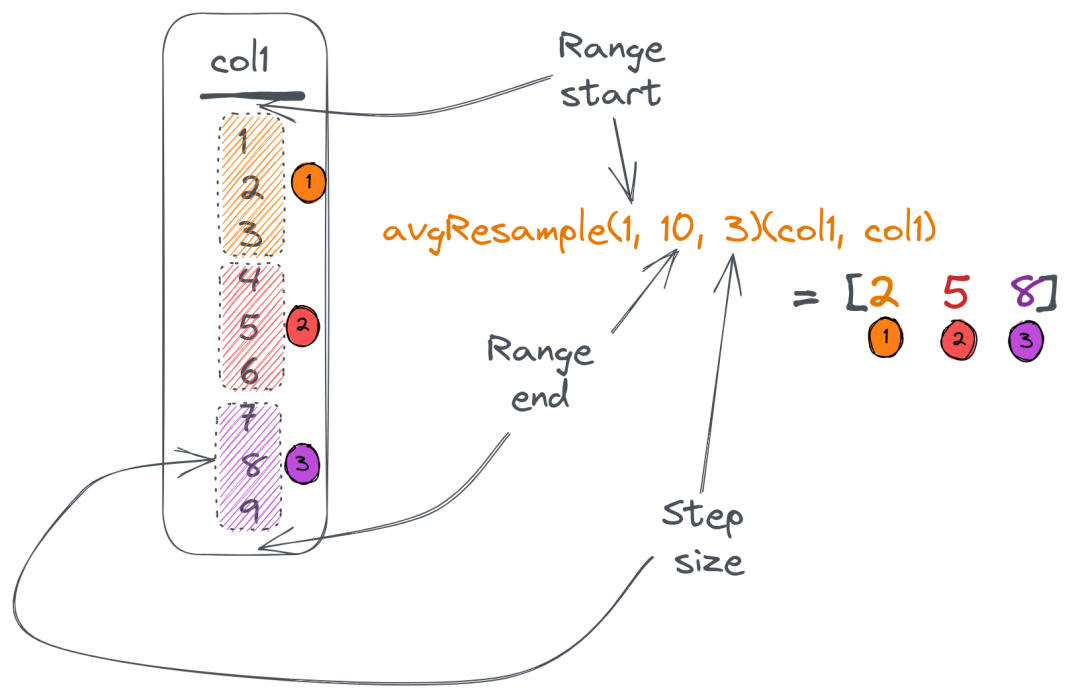
假设我们想要根据 total_amount(从最小值0到最大值500)以步长100来分割我们的支付表数据。然后,我们想要知道每个组中有多少条目,以及每个组的总平均数:
SELECT
countResample(0, 500, 100)(toInt16(total_amount)) AS group_entries,
avgResample(0, 500, 100)(total_amount, toInt16(total_amount)) AS group_totals
FROM payments
FORMAT Vertical
Row 1:
──────
group_entries: [21,20,24,31,4]
group_totals: [50.21238123802912,157.32600135803222,246.1433334350586,356.2583834740423,415.2425003051758]这里,countResample() 函数计算每个组中的条目数,avgResample() 函数计算每个组的 total_amount 的平均值。Resample 组合器接受要根据的列名称作为组合函数的最后一个参数。
请注意,countResample() 函数只有一个参数(因为 count() 根本不需要参数),avgResample() 函数有两个参数(第一个是要计算平均值的列)。最后,我们必须使用 toInt16 将 total_amount 转换为整数,因为 Resample 组合器需要这样。
要以表格布局获取 Resample() 组合器的输出,我们可以使用 arrayZip() 和 arrayJoin() 函数:
SELECT
round(tp.2, 2) AS avg_total,
tp.1 AS entries
FROM
(
SELECT
arrayJoin(arrayZip(countResample(0, 500, 100)(toInt16(total_amount)),
avgResample(0, 500, 100)(total_amount, toInt16(total_amount)))) AS tp
FROM payments
)
┌─avg_total─┬─entries─┐
│ 50.21 │ 21 │
│ 157.33 │ 20 │
│ 246.14 │ 24 │
│ 356.26 │ 31 │
│ 415.24 │ 4 │
└───────────┴─────────┘在这里,我们将两个数组中的对应值组合成元组,并使用 arrayJoin() 函数将生成的数组展开成表格。
控制空结果的聚合值
聚合函数在结果集为空时的反应不同。例如,count() 会返回 0,而 avg() 则会产生一个 nan 值。
我们可以使用 OrDefault() 和 OrNull() 这两个组合器来控制这种行为。它们都会改变在数据集为空时聚合函数返回的值:
-
OrDefault() 会返回函数的默认值,而不是 nan,
-
OrNull() 会返回 NULL(并且还会改变返回类型为 Nullable)。
考虑以下示例:
SELECT
count(),
countOrNull(),
avg(total_amount),
avgOrDefault(total_amount),
sumOrNull(total_amount)
FROM payments
WHERE total_amount > 1000
┌─count()─┬─countOrNull()─┬─avg(total_amount)─┬─avgOrDefault(total_amount)─┬─sumOrNull(total_amount)─┐
│ 0 │ ᴺᵁᴸᴸ │ nan │ 0 │ ᴺᵁᴸᴸ │
└─────────┴───────────────┴───────────────────┴────────────────────────────┴─────────────────────────┘正如我们在第一列中所看到的,返回了零行。请注意 countOrNull() 将返回 NULL 而不是 0,而 avgOrDefault() 则给出 0 而不是 nan。
使用其他组合器
与其他组合器一样,orNull() 和 orDefault() 可以与不同的组合器一起使用,以实现更高级的逻辑:
SELECT
sumIfOrNull(total_amount, status = 'declined') AS declined,
countIfDistinctOrNull(total_amount, status = 'confirmed') AS confirmed_distinct
FROM payments
WHERE total_amount > 420
┌─declined─┬─confirmed_distinct─┐
│ ᴺᵁᴸᴸ │ 1 │
└──────────┴────────────────────┘我们使用了 sumIfOrNull() 组合函数来计算仅拒绝的付款,并在空集合上返回 NULL。countIfDistinctOrNull() 函数计算了不同的 total_amount 值的计数,但仅针对满足指定条件的行。
聚合数组
ClickHouse 的 Array 类型在其用户中很受欢迎,因为它为表结构带来了很大的灵活性。为了有效地操作 Array 列,ClickHouse 提供了一组数组函数。为了简化对 Array 类型进行聚合,ClickHouse 提供了 Array() 组合器。这些组合器将给定的聚合函数应用于数组列中的所有值,而不是数组本身:
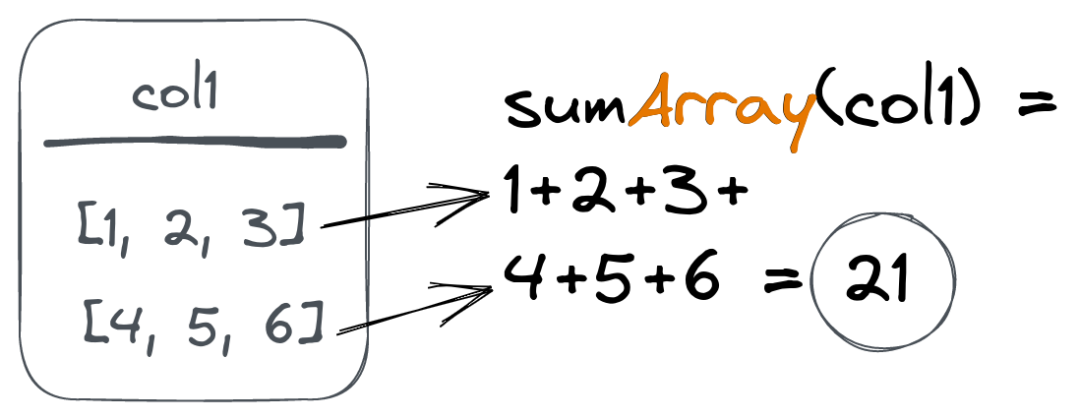
假设我们有以下表(填充了示例数据):
CREATE TABLE article_reads
(
`time` DateTime,
`article_id` UInt32,
`sections` Array(UInt16),
`times` Array(UInt16),
`user_id` UInt32
)
ENGINE = MergeTree
ORDER BY (article_id, time)
┌────────────────time─┬─article_id─┬─sections─────────────────────┬─times────────────────────────────────┬─user_id─┐
│ 2023-01-18 23:44:17 │ 10 │ [16,18,7,21,23,22,11,19,9,8] │ [82,96,294,253,292,66,44,256,222,86] │ 424 │
│ 2023-01-20 22:53:00 │ 10 │ [21,8] │ [30,176] │ 271 │
│ 2023-01-21 03:05:19 │ 10 │ [24,11,23,9] │ [178,177,172,105] │ 536 │这张表用于为文章的每个部分存储文章阅读数据。当用户阅读一篇文章时,我们将阅读的部分保存到 sections 数组列中,将相关的阅读时间保存到 times 列中:
让我们使用 uniqArray() 函数来计算每篇文章阅读的唯一部分数,再结合 avgArray() 来获得每个部分的平均时间:
SELECT
article_id,
uniqArray(sections) sections_read,
round(avgArray(times)) time_per_section
FROM article_reads
GROUP BY article_id
┌─article_id─┬─sections_read─┬─time_per_section─┐
│ 14 │ 22 │ 175 │
│ 18 │ 25 │ 159 │
...
│ 17 │ 25 │ 170 │
└────────────┴───────────────┴──────────────────┘我们可以使用 minArray() 和 maxArray() 函数跨所有文章获取阅读时间的最小值和最大值:
SELECT
minArray(times),
maxArray(times)
FROM article_reads
┌─minArray(times)─┬─maxArray(times)─┐
│ 30 │ 300 │
└─────────────────┴─────────────────┘我们还可以使用 groupUniqArray() 函数结合 Array() 组合器来获取每篇文章的阅读部分列表:
SELECT
article_id,
groupUniqArrayArray(sections)
FROM article_reads
GROUP BY article_id
┌─article_id─┬─groupUniqArrayArray(sections)───────────────────────────────────────┐
│ 14 │ [16,13,24,8,10,3,9,19,23,14,7,25,2,1,21,18,12,17,22,4,6,5] │
...
│ 17 │ [16,11,13,8,24,10,3,9,23,19,14,7,25,20,2,1,15,21,6,5,12,22,4,17,18] │
└────────────┴─────────────────────────────────────────────────────────────────────┘另一个常用的函数是 any(),它返回聚合下的任何列值,并且也可以与 Array 组合器一起使用:
SELECT
article_id,
anyArray(sections)
FROM article_reads
GROUP BY article_id
┌─article_id─┬─anyArray(sections)─┐
│ 14 │ 19 │
│ 18 │ 6 │
│ 19 │ 25 │
│ 15 │ 15 │
│ 20 │ 1 │
│ 16 │ 23 │
│ 12 │ 16 │
│ 11 │ 2 │
│ 10 │ 16 │
│ 13 │ 9 │
│ 17 │ 20 │
└────────────┴────────────────────┘
使用 Array 与其他组合器
Array 组合器可以与任何其他组合器一起使用:
SELECT
article_id,
sumArrayIfOrNull(times, length(sections) > 8)
FROM article_reads
GROUP BY article_id
┌─article_id─┬─sumArrayOrNullIf(times, greater(length(sections), 8))─┐
│ 14 │ 4779 │
│ 18 │ 3001 │
│ 19 │ NULL │
...
│ 17 │ 14424 │
└────────────┴───────────────────────────────────────────────────────┘我们使用了 sumArrayIfOrNull() 函数来计算阅读超过八个部分的文章的总时间。请注意,对于阅读超过八个部分的次数为零的文章,会返回 NULL,因为我们还使用了 OrNull() 组合器。
如果我们将数组函数与组合器一起使用,可以处理更加复杂的情况:
SELECT
article_id,
countArray(arrayFilter(x -> (x > 120), times)) AS sections_engaged
FROM article_reads
GROUP BY article_id
┌─article_id─┬─sections_engaged─┐
│ 14 │ 26 │
│ 18 │ 44 │
...
│ 17 │ 98 │
└────────────┴──────────────────┘在这里,我们首先使用 arrayFilter 函数过滤 times 数组,以删除所有低于 120 秒的值。然后,我们使用 countArray 来计算每篇文章的过滤时间(在我们的案例中表示参与阅读)。
聚合映射
ClickHouse 中还提供了另一种强大的类型,即 Map。与数组类似,我们可以使用 Map() 组合器对此类型应用聚合。
假设我们有以下具有 Map 列类型的表:
CREATE TABLE page_loads
(
`time` DateTime,
`url` String,
`params` Map(String, UInt32)
)
ENGINE = MergeTree
ORDER BY (url, time)
┌────────────────time─┬─url─┬─params───────────────────────────────┐
│ 2023-01-25 17:44:26 │ / │ {'load_speed':100,'scroll_depth':59} │
│ 2023-01-25 17:44:37 │ / │ {'load_speed':400,'scroll_depth':12} │
└─────────────────────┴─────┴──────────────────────────────────────┘我们可以使用 Map() 组合器将 sum() 和 avg() 函数应用于获取总加载时间和平均滚动深度:
SELECT
sumMap(params)['load_speed'] AS total_load_time,
avgMap(params)['scroll_depth'] AS average_scroll
FROM page_loads
┌─total_load_time─┬─average_scroll─┐
│ 500 │ 35.5 │
└─────────────────┴────────────────┘Map() 组合器也可以与其他组合器一起使用:
SELECT sumMapIf(params, url = '/404')['scroll_depth'] AS average_scroll FROM page_loads
聚合相应的数组值
另一种处理数组列的方法是从两个数组中聚合相应的值。这将产生另一个数组。这可以用于矢量化数据(如向量或矩阵),并通过 ForEach() 组合器实现:
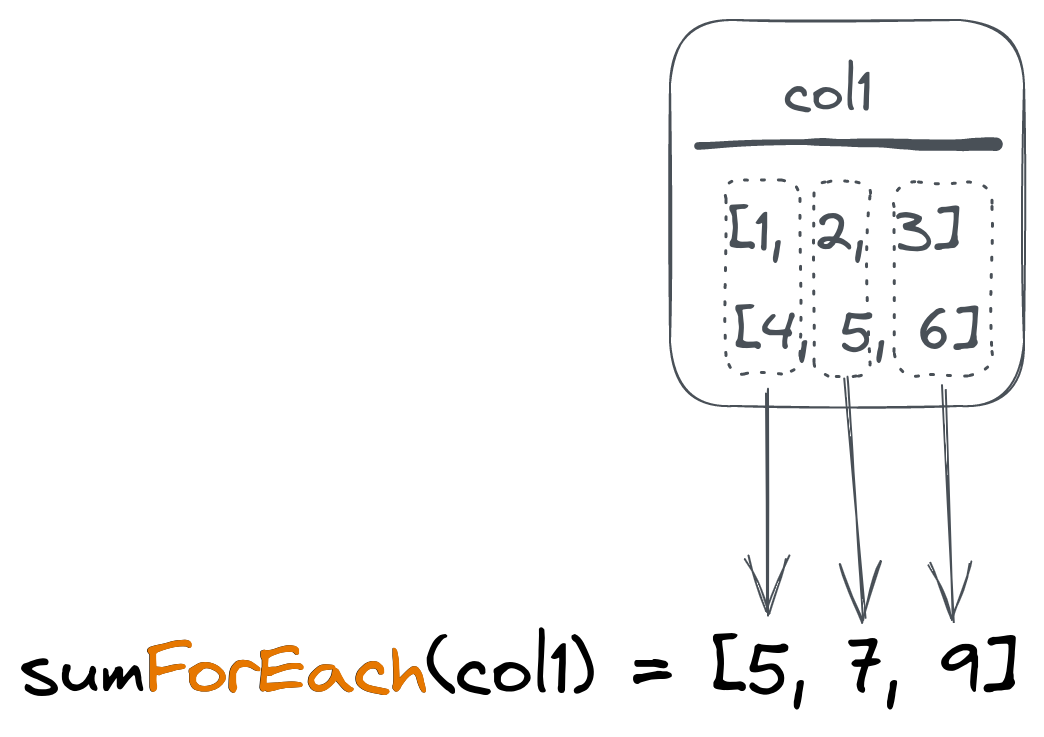
假设我们有以下具有向量的表:
SELECT * FROM vectors
┌─title──┬─coordinates─┐
│ first │ [1,2,3] │
│ second │ [2,2,2] │
│ third │ [0,2,1] │
└────────┴─────────────┘要计算平均坐标数组(向量),我们可以使用 avgForEach() 组合函数:
SELECT avgForEach(coordinates) FROM vectors
┌─avgForEach(coordinates)─┐
│ [1,2,2] │
└─────────────────────────┘这将要求 ClickHouse 计算所有坐标数组的第一个元素的平均值,并将其放入结果数组的第一个元素中。然后对第二个和第三个元素重复相同的操作。
当然,也支持与其他组合器一起使用:
SELECT avgForEachIf(coordinates, title != 'second') FROM vectors
┌─avgForEachIf(coordinates, notEquals(title, 'second'))─┐
│ [0.5,2,2] │
└───────────────────────────────────────────────────────┘处理聚合状态
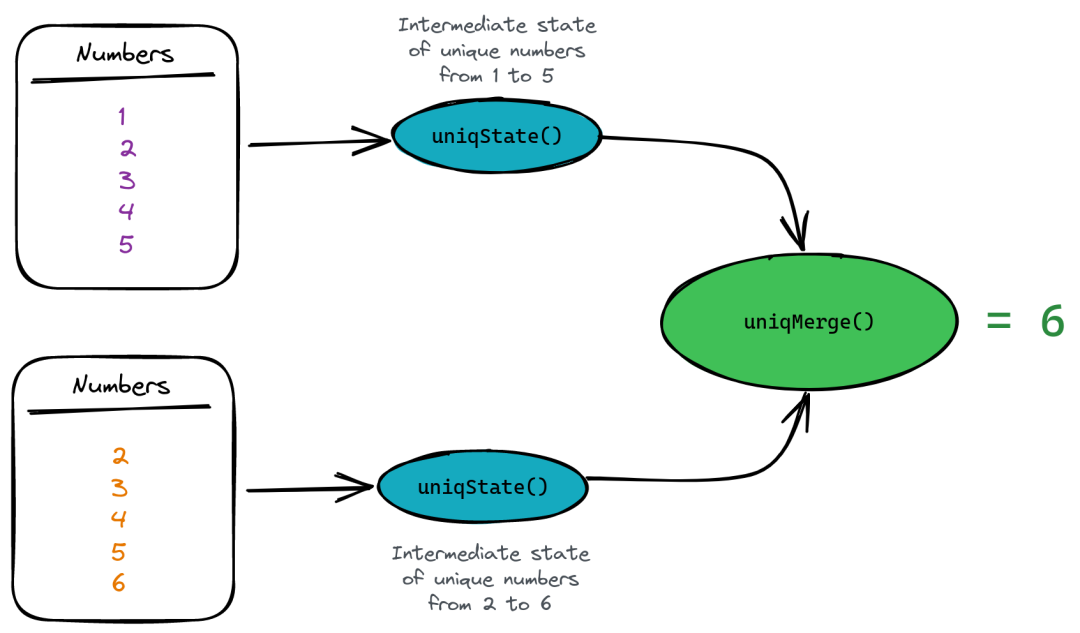
ClickHouse允许处理中间聚合状态而不是结果值。假设我们需要计算唯一值的数量,但我们不想保存值本身(因为它占用空间)。在这种情况下,我们可以使用 State() 组合器为 uniq() 函数保存中间聚合状态,然后使用 Merge() 组合器计算实际值:
SELECT uniqMerge(u)
FROM
(
SELECT uniqState(number) AS u FROM numbers(5)
UNION ALL
SELECT uniqState(number + 1) AS u FROM numbers(5)
)
┌─uniqMerge(u)─┐
│ 6 │
└──────────────┘在这里,第一个嵌套查询将返回1到5数字的唯一计数的状态。第二个嵌套查询返回2到6数字的相同状态。父查询然后使用 uniqMerge() 函数合并我们的状态,并获取我们看到的所有唯一数字的计数:
为什么我们要这样做?因为聚合状态所占用的空间比原始数据少得多。当我们想要将此状态存储在磁盘上时,这一点尤为重要。例如,uniqState() 数据比100万个整数数字少15倍的空间:
SELECT
table,
formatReadableSize(total_bytes) AS size
FROM system.tables
WHERE table LIKE 'numbers%'
┌─table─────────┬─size───────┐
│ numbers │ 3.82 MiB │ <- we saved 1 million ints here
│ numbers_state │ 245.62 KiB │ <- we save uniqState for 1m ints here
└───────────────┴────────────┘ClickHouse提供了一个AggregatingMergeTree表引擎,用于存储聚合状态并在主键上自动合并它们。让我们创建一个表,用于存储我们之前示例中的每日支付的聚合数据:
CREATE TABLE payments_totals
(
`date` Date,
`total_amount` AggregateFunction(sum, Float)
)
ENGINE = AggregatingMergeTree
ORDER BY date我们使用了AggregateFunction类型,让ClickHouse知道我们要存储聚合总状态而不是标量值。在插入时,我们需要使用sumState函数插入聚合状态:
INSERT INTO payments_totals SELECT
date(create_time) AS date,
sumState(total_amount)
FROM payments
WHERE status = 'confirmed'
GROUP BY date最后,我们需要使用sumMerge()函数来获取结果值:
┌─sumMerge(total_amount)─┐
│ 12033.219916582108 │
└────────────────────────┘请注意,ClickHouse提供了一种简单的方法来使用基于材料化视图的聚合表引擎。ClickHouse还提供了一个SimpleState组合器,作为可以与某些聚合函数(如'sum'或'min')一起使用的优化版本。
总结
聚合函数组合器为ClickHouse中的任何数据结构上的分析查询带来了几乎无限的可能性。我们可以为聚合添加条件,对数组元素应用函数,或获取中间状态以以聚合形式存储数据,但仍可用于查询。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









