








本文字数:17443;估计阅读时间:44 分钟
作者:Dale McDiarmid
本文在公众号【ClickHouseInc】首发

本文将探索 MLOps 的世界,探讨如何在 ClickHouse 中对数据进行建模和转换,使其成为高效的特征存储,用于训练机器学习模型。本文讨论的方法已被现有的 ClickHouse 用户采用,感谢他们分享这些技术,同时我们也会探讨开箱即用的特征存储解决方案。
我们将重点关注 ClickHouse 作为数据源、离线存储和转换引擎的角色。这些特征存储组件对于高效、准确地传递数据至关重要。尽管大多数开箱即用的特征存储提供了抽象层,我们将深入探讨如何高效建模数据,以构建和提供特征。无论您是希望构建自己的特征存储,还是只是对现有存储使用的技术感到好奇,请继续阅读。
为什么选择 ClickHouse?
在之前的博客文章中,我们已经探讨过什么是特征存储,并建议用户在深入阅读本文之前先了解这一概念。简单来说,特征存储是一个集中式存储库,用于存储和管理用于训练机器学习模型的数据,旨在提高协作性和重用性,同时减少模型迭代时间。
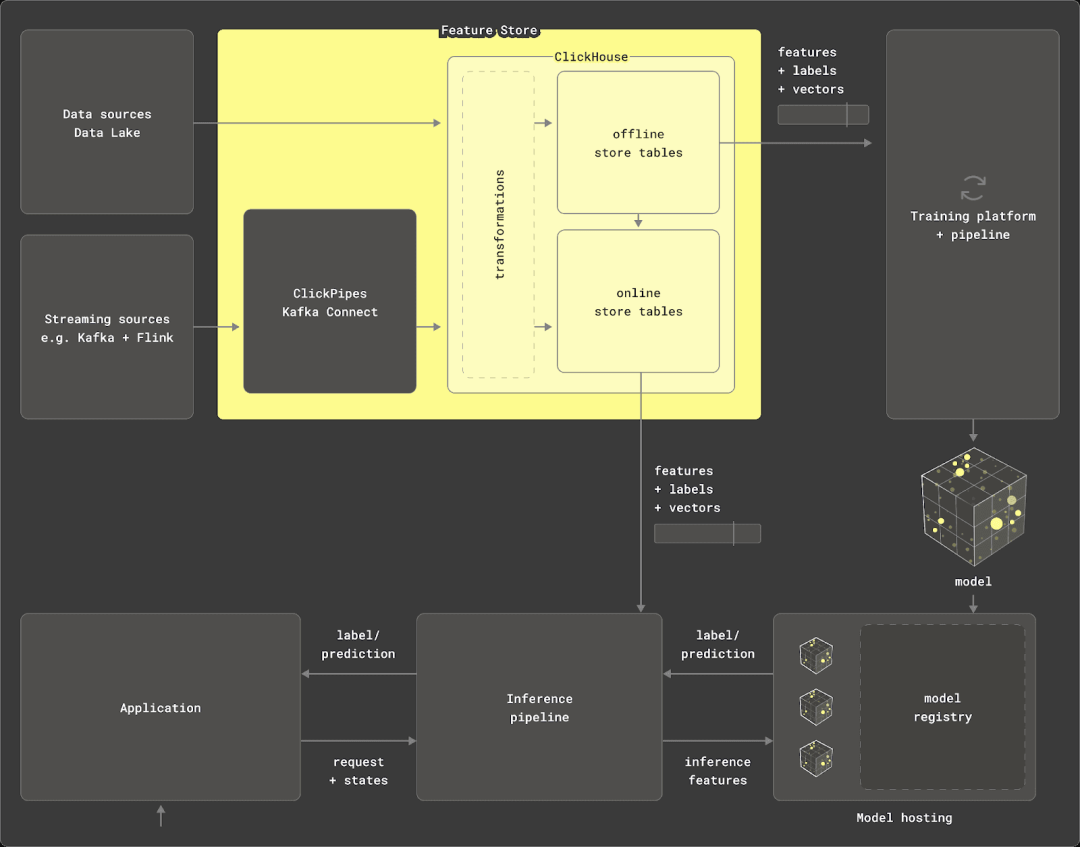
作为一个实时数据仓库,ClickHouse 除了提供数据源之外,还能够满足特征存储的两个主要需求。
-
转换引擎:ClickHouse 利用 SQL 进行数据转换声明,并通过其强大的分析和统计功能进行优化。它支持从多种数据源(如 Parquet、Postgres 和 MySQL)中查询数据,并在 PB 级数据上执行聚合操作。物化视图允许在插入时进行数据转换。此外,ClickHouse 还可以通过 chDB 在 Python 中使用,以处理和转换大型数据帧。
-
离线存储:ClickHouse 可以通过 INSERT INTO SELECT 语句持久化查询结果,自动生成表架构。它支持高效的数据迭代和扩展,特征通常以时间戳为查询点的方式存储在表中。ClickHouse 的稀疏索引和 ASOF LEFT JOIN 子句加速了过滤和特征选择过程,优化了训练管道中的数据准备工作。这些操作在集群中并行执行,使得离线存储可以扩展到 PB 级别,同时保持特征存储的轻量化。
在本文中,我们将展示如何在 ClickHouse 中对数据进行建模和管理,以实现这些功能。
总体步骤
当使用 ClickHouse 作为离线特征存储的基础时,我们将训练模型的步骤概括为以下几个部分:
-
探索 - 通过 SQL 查询熟悉 ClickHouse 中的源数据。
-
识别数据子集和特征 - 确定可能的特征、它们各自的实体,以及生成这些特征所需的数据子集。我们称这些子集为“特征子集”。
-
创建特征 - 编写 SQL 查询以生成所需特征。
-
生成模型数据 - 适当地组合这些特征,生成一组特征向量,通常通过在公共键和时间戳邻近性上使用 ASOF JOIN 来实现。
-
生成测试集和训练集 - 将“特征子集”拆分为测试集和训练集(可能还有验证集)。
-
训练模型 - 使用训练数据进行模型训练,可能尝试不同的算法。
-
模型选择与调优 - 使用验证集评估模型,选择最佳模型,并微调超参数。
-
模型评估 - 使用测试集评估最终模型。如果性能足够好,则可以停止;否则,返回步骤 2。
我们主要关注步骤 (1) 到 (5),因为这些步骤是 ClickHouse 特有的。上述过程的一个关键特点是其高度迭代性。步骤 (3) 和 (4) 可以宽泛地归为“特征工程”,这一过程通常比选择模型和优化超参数更耗时。因此,优化这一过程,并确保 ClickHouse 的高效使用,可以带来显著的时间和成本节省。
接下来,我们将逐步探讨这些步骤,并提出一种灵活的方法,充分利用 ClickHouse 的特性,帮助用户高效地进行迭代。
数据集与示例
在本示例中,我们使用了以下网站分析数据集,详见此处【https://clickhouse.com/docs/en/getting-started/example-datasets/metrica】。该数据集包含 1 亿行数据,每行代表对特定 URL 的请求。使用 ClickHouse 处理网站分析数据并训练机器学习模型是常见的用例[1][2]。
由于数据量较大,以下表格仅包含我们将使用的列。完整的表结构请见此处【https://pastila.nl/?00acf5da/2295705307eb4090c33cb5f0f5b8d472#kSJRFJM6RcULiQUo90npfA==】。
CREATE TABLE default.web_events
(
`EventTime` DateTime,
`UserID` UInt64,
`URL` String,
`UserAgent` UInt8,
`RefererCategoryID` UInt16,
`URLCategoryID` UInt16,
`FetchTiming` UInt32,
`ClientIP` UInt32,
`IsNotBounce` UInt8,
-- many more columns...
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))为了说明建模步骤,假设我们希望使用此数据集构建一个模型,以预测用户在请求到达时是否会跳出。如果考虑上述源数据,这由 IsNotBounce 列表示。此列代表我们的目标类别或标签。
我们不会实际构建这个模型或提供 Python 代码,而是专注于数据建模过程。因此,所选择的特征仅作示例用途。
步骤 1 - 探索
要探索和理解源数据,用户需要先熟悉 ClickHouse SQL。我们建议用户在此过程中熟悉 ClickHouse 提供的各种分析功能。一旦掌握了数据,我们就可以开始识别模型所需的特征及相应的数据子集。
步骤 2 - 特征和子集
为了预测一次访问是否会跳出,我们的模型需要一个训练集,其中每个数据点都包含组装成特征向量的适当特征。这些特征通常基于数据的一个子集。
我们在其他博客中探讨过特征和特征向量的概念,以及它们分别如何与结果集的列和行对应。关键是,这些特征在训练和请求时都必须可用。
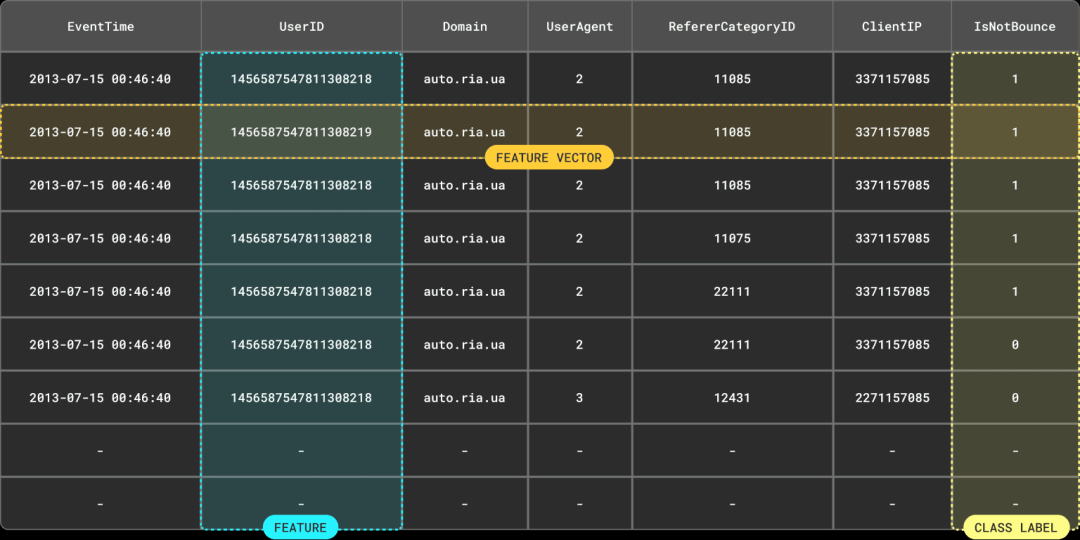
请注意,我们在上文中强调了“结果集”。特征向量往往不仅仅是表中某一行包含的列特征。通常情况下,需要通过复杂的查询来计算特征,这些查询可能涉及聚合或转换操作。
识别特征
在识别特征之前,我们需要了解两个关键属性,它们会影响我们的建模过程:
-
与实体的关联 - 特征通常与一个实体相关联或“键入”到该实体。对于我们的任务,可能有助于预测的特征可能是基于用户或域的组合。基于用户的特征通常与特定请求相关,例如用户的年龄、客户端 IP 或用户代理。基于域的特征则与访问的页面相关,例如每年的访问次数。
要将特征与某个实体实例关联,需要该实体有一个键或标识符。在我们的例子中,我们需要一个用户标识符和一个域名值。这些分别可以从 UserID 和 URL 列中获得。我们可以使用 ClickHouse 的 domain 函数从 URL 中提取域名,即 domain(URL)。
-
动态与复杂 - 虽然有些特征是相对静态的,例如用户的年龄,但其他特征如客户端 IP 会随着时间的推移而变化。在这种情况下,我们需要获取特定时间戳下的特征值,这是创建时点正确训练集的关键。
某些特征可能相对简单,例如设备是否为移动设备或客户端 IP,而其他更复杂的特征则需要聚合统计数据,并且这些数据会随时间变化——这是 ClickHouse 的强项所在!
示例特征
例如,假设我们认为以下特征有助于预测用户访问网站时是否会跳出。由于这些特征都是动态的,并且会随时间变化,因此它们都与时间戳关联。
-
用户代理 - 与用户实体相关联,并在 UserAgent 列中可用。
-
引用类别 - 例如,搜索引擎、社交媒体或直接访问。这是通过 RefererCategoryID 列获取的用户特征。
-
每小时访问的域名数量 - 记录用户发出请求时的访问数量。需要使用 GROUP BY 来计算这个用户特征。
-
每小时访问该域的唯一 IP 数量 - 一个域特征,需要使用 GROUP BY 计算。
-
页面类别 - 通过 URLCategoryID 列获取的用户特征。
-
每小时的平均请求时间 - 需要使用 GROUP BY 从 FetchTiming 列中计算。
这些特征可能并不理想,仅作示例。将这些特征与用户实体关联的方式相对简单化。例如,某些特征与请求或会话实体关联可能会更准确。
特征数据子集
在确定将要使用的特征后,我们可以识别构建这些特征所需的数据子集。这一步是可选的,因为有时用户可能希望使用整个数据集,或者数据的规模和复杂性不足以需要这一步。
在实践中,我们经常看到用户为模型数据创建专门的表——我们称之为“特征数据子集”。这些表通常包括:
-
每个特征向量的实体值。
-
如果存在,事件的时间戳。
-
类别标签。
-
生成预期特征所需的列。用户还可能希望添加其他列,以便在未来迭代中使用。
这种方法具有以下几个优点:
-
允许对数据进行排序和优化,以便于未来访问。通常,模型数据的读取和过滤方式与源数据不同。在生成最终训练集时,这些表也可以比源数据更快地产生特征。
-
模型可能需要一个数据子集或经过转换的数据集。识别、过滤和转换这个子集可能会导致查询开销较大。通过将数据插入到一个中间模型表中,这个查询只需执行一次。后续的特征生成和模型训练可以高效地从该表中获取数据。
我们还可以利用这一步来去除重复数据。虽然原始数据可能不包含重复项,但在提取子集列作为特征时,最终的子集可能会包含重复数据。
假设我们为模型创建了一个中间表 predict_bounce_subset。这个表需要包含 EventTime、标签 IsNotBounce,以及实体键 Domain 和 UserID。此外,我们还包括简单的特征列 UserAgent、RefererCategoryID 和 URLCategoryID,以及生成聚合特征所需的列 FetchTiming 和 ClientIP。
CREATE TABLE predict_bounce_subset
(
EventTime DateTime64,
UserID UInt64,
Domain String,
UserAgent UInt8,
RefererCategoryID UInt16,
URLCategoryID UInt16,
FetchTiming UInt32,
ClientIP UInt32,
IsNotBounce UInt8
)
ENGINE = ReplacingMergeTree
ORDER BY (EventTime, Domain, UserID, UserAgent, RefererCategoryID, URLCategoryID, FetchTiming, ClientIP, IsNotBounce)
PRIMARY KEY (EventTime, Domain, UserID)我们使用 ReplacingMergeTree 作为表引擎。该引擎会对排序键列值相同的行进行去重。这一去重过程在后台的合并树中异步进行,不过我们可以通过使用 FINAL 修饰符,在查询时确保不会收到重复数据。在这种情况下,与插入时通过 GROUP BY 列进行去重相比,这种去重方法通常更具资源效率。上文中假设所有列都用于标识唯一行。然而,也可能出现具有相同 EventTime、UserID 和 Domain 的事件,例如,在访问域时发出多个请求,这些请求具有不同的 FetchTiming 值。
关于 ReplacingMergeTree 的更多详细信息可以在此处找到。
作为一种优化,我们通过 PRIMARY KEY 子句将排序键的子集加载到主键中(存储在内存中)。默认情况下,ORDER BY 中的所有列都会被加载。在这种情况下,我们可能只需要按 EventTime、Domain 和 UserID 进行查询。
假设我们希望仅使用与机器人无关的事件来训练跳出率预测模型——这些事件可以通过 Robotness=0 来识别。我们还需要 Domain 和 UserID 的值。
我们可以通过 INSERT INTO SELECT 填充 predict_bounce_subset 表,从 web_events 表中读取行,并应用过滤器,将数据量减少到 4200 万行。
INSERT INTO predict_bounce_subset SELECT
EventTime,
UserID,
domain(URL) AS Domain,
UserAgent,
RefererCategoryID,
URLCategoryID,
FetchTiming,
ClientIP,
IsNotBounce
FROM web_events
WHERE Robotness = 0 AND Domain != '' AND UserID != 0
0 rows in set. Elapsed: 7.886 sec. Processed 99.98 million rows, 12.62 GB (12.68 million rows/s., 1.60 GB/s.)
SELECT formatReadableQuantity(count()) AS count
FROM predict_bounce_subset FINAL
┌─count─────────┐
│ 42.89 million │
└───────────────┘
1 row in set. Elapsed: 0.003 sec.请注意上文中使用的 FINAL 子句,以确保只计算唯一的行。
更新特征子集
虽然某些数据子集是静态的,但随着源表中新事件的到来,其他子集可能会发生变化。因此,用户通常需要保持子集的最新状态。虽然可以通过定时查询(例如使用 dbt)重建表来实现这一点,但也可以使用 ClickHouse 的增量物化视图来维护这些表。
物化视图允许用户将计算成本从查询时间转移到插入时间。ClickHouse 的物化视图其实就是一个触发器,当数据块插入表(例如 web_events 表)时,触发器会运行查询。然后,将查询结果插入到第二个“目标”表中——在我们的例子中,是子集表。如果有更多行被插入,结果将再次被发送到目标表。这一合并结果等同于在所有原始数据上运行查询的结果。
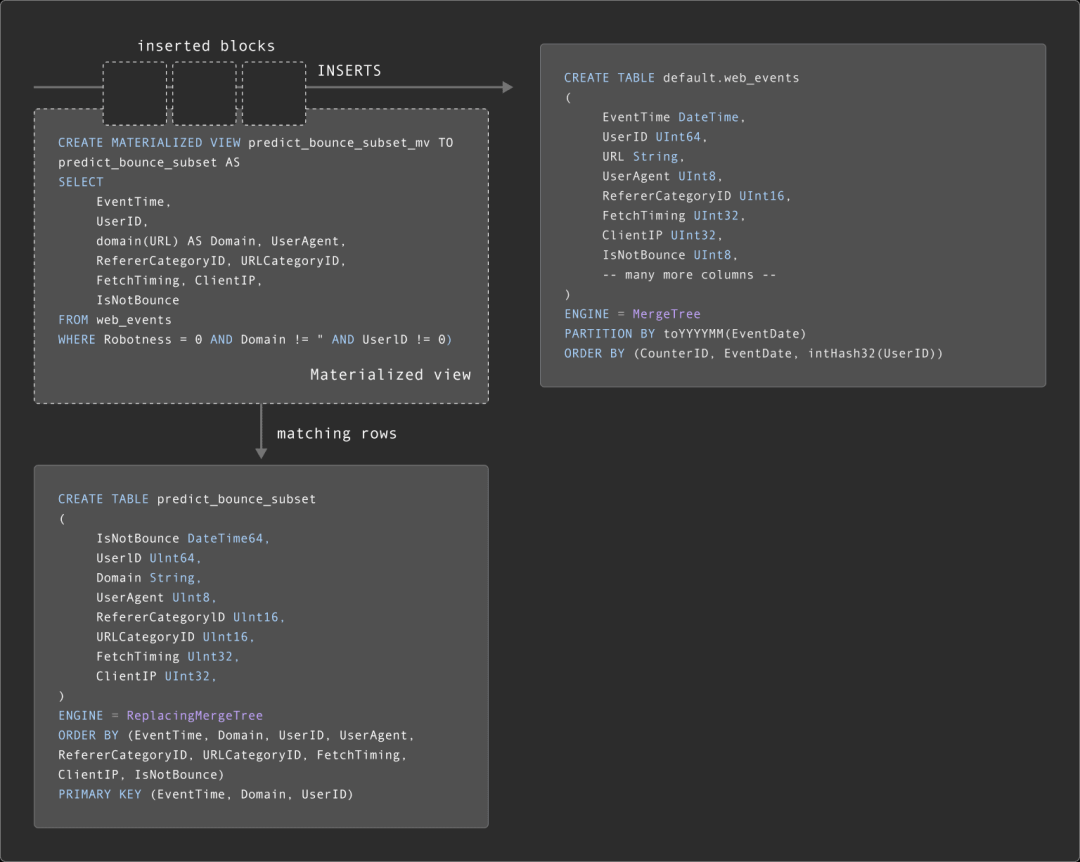
以下是维护 predict_bounce_subset 的物化视图示例:
CREATE MATERIALIZED VIEW predict_bounce_subset_mv TO predict_bounce_subset AS
SELECT
EventTime,
UserID,
domain(URL) AS Domain,
UserAgent,
RefererCategoryID,
URLCategoryID,
FetchTiming,
ClientIP,
IsNotBounce
FROM web_events
WHERE Robotness = 0 AND Domain != '' AND UserID != 0这是一个简单的例子,我们建议用户深入了解物化视图的强大功能。在接下来的步骤中,我们假设使用的模型表为 predict_bounce_subset。
步骤 3 - 创建特征
为了进行模型训练,我们需要将预期的特征组装成一组特征向量,并附加标签 IsNotBounce,如下所示:

请注意,我们是如何将多个实体的特征组装成特征向量的。在许多情况下,我们需要获取另一个实体中最接近时间点的特征值。
熟悉 ClickHouse 的有经验的 SQL 开发人员可能能够编写出生成上述特征向量的查询。尽管可以实现,但这通常是一个复杂且计算开销巨大的查询,特别是在处理数十亿行的大型数据集时。
此外,正如前面提到的,我们的特征向量是动态的,在不同的训练迭代中可能由不同的特征组合构成。理想情况下,不同的工程师和数据科学家应使用相同的特征定义,并尽可能优化查询的编写。
鉴于上述需求,将特征物化到表中是有意义的,可以通过 INSERT INTO SELECT 将查询结果写入表中。这意味着我们只需生成一次特征,将结果写入表中,之后可以高效地读取和重复使用这些结果。这也使我们能够一次性优化特征查询,并与其他工程师和科学家共享结果。
目前,我们没有详细讨论如何声明、版本控制和共享特征定义。毕竟,SQL 也是代码。对此问题有多种解决方案,每种解决方案应对不同的挑战——详见“构建或采用”。
特征表
特征表用于存储与实体相关的特征实例,并且可以选择包含时间戳。我们观察到用户使用了两种特征表模型——为每个特征创建一个表,或为每个实体创建一个表。每种方法都有其优缺点,我们将在下文中详细探讨。不过,这两种方法都能实现特征的重用,并且有助于数据的高效压缩。
您无需为每个特征都创建特征表。在某些情况下,如果特征已经由列值表示,可以直接从模型表中使用它们。
特征表(每个特征)
在每个特征使用单独的表时,表名直接表示特征本身。这种方法的主要优点是可以简化后续的联接操作。此外,它还允许用户通过物化视图,在源数据发生变化时自动维护这些表——详见“更新”部分。
这种方法的缺点是扩展性不如“每个事件”方法。拥有数千个特征的用户将会有数千个表。虽然可以管理,但为每个表创建物化视图并不现实。
举例来说,考虑存储域名特征“每个域名的唯一 IP 数量”的表。
CREATE TABLE number_unique_ips_per_hour
(
Domain String,
EventTime DateTime64,
Value Int64
)
ENGINE = MergeTree
ORDER BY (Domain, EventTime)我们选择了 ORDER BY 键,以优化数据压缩和未来的查询读取。可以通过简单的 INSERT INTO SELECT 语句,结合聚合操作,来计算特征并填充特征表。
INSERT INTO number_unique_ips_per_hour SELECT
Domain,
toStartOfHour(EventTime) AS EventTime,
uniqExact(ClientIP) AS Value
FROM predict_bounce_subset FINAL
GROUP BY
Domain,
EventTime
0 rows in set. Elapsed: 0.777 sec. Processed 43.80 million rows, 1.49 GB (56.39 million rows/s., 1.92 GB/s.)
SELECT count()
FROM number_unique_ips_per_hour
┌─count()─┐
│ 613382 │
└─────────┘我们选择用 Domain 和 Value 作为实体和特征值的列名,以简化未来的查询操作。用户可能希望为所有特征使用统一的表结构,包括 Entity 和 Value 列。
CREATE TABLE <feature_name>
(
Entity Variant(UInt64, Int64, String),
EventTime DateTime64,
Value Variant(UInt64, Int64, Float64)
)
ENGINE = MergeTree
ORDER BY (Entity, EventTime)这需要使用 Variant 类型。此类型允许列支持多个数据类型的组合,例如 Variant(String, Float64, Int64) 表示该列的每一行可以包含 String, Float64, Int64 中的任意一种数据类型,或者为空值(NULL)。
这种功能目前处于实验阶段,对于上述方法是可选的,但对于下面描述的“每个实体”方法则是必需的。
特征表(每个实体)
在“每个实体”的方法中,我们将所有与同一实体关联的特征存储在同一个表中。在这种情况下,我们使用 FeatureId 列来标识特征名称。
这种方法的优点在于其可扩展性。一个表可以轻松容纳数千个特征。
主要的缺点是这种方法目前不支持物化视图。
请注意,在下面的示例中,我们使用了新的 Variant 类型来处理域名特征。虽然该表目前支持 UInt64、Int64 和 Float64 类型的特征值,但它也可以扩展支持更多类型。
-- domain Features
SET allow_experimental_variant_type=1
CREATE TABLE domain_features
(
Domain String,
FeatureId String,
EventTime DateTime,
Value Variant(UInt64, Int64, Float64)
)
ENGINE = MergeTree
ORDER BY (FeatureId, Domain, EventTime)此表的 ORDER BY 优化是为了按特定的 FeatureId 和 Domain 进行过滤——这也是我们接下来将看到的典型访问模式。
要将“每个域名的唯一 IP 数量”这一特征填充到该表中,我们需要使用类似于之前的查询:
INSERT INTO domain_features SELECT
Domain,
'number_unique_ips_per_hour' AS FeatureId,
toStartOfHour(EventTime) AS EventTime,
uniqExact(ClientIP) AS Value
FROM predict_bounce_subset FINAL
GROUP BY
Domain,
EventTime
0 rows in set. Elapsed: 0.573 sec. Processed 43.80 million rows, 1.49 GB (76.40 million rows/s., 2.60 GB/s.)
SELECT count()
FROM domain_features
┌─count()─┐
│ 613382 │
└─────────┘新手用户可能会疑惑,“每个特征”的方法是否比“每个实体”的方法在特征检索速度上更快。由于使用了排序键和 ClickHouse 稀疏索引,两者之间在检索速度上不应该有区别。
更新特征表
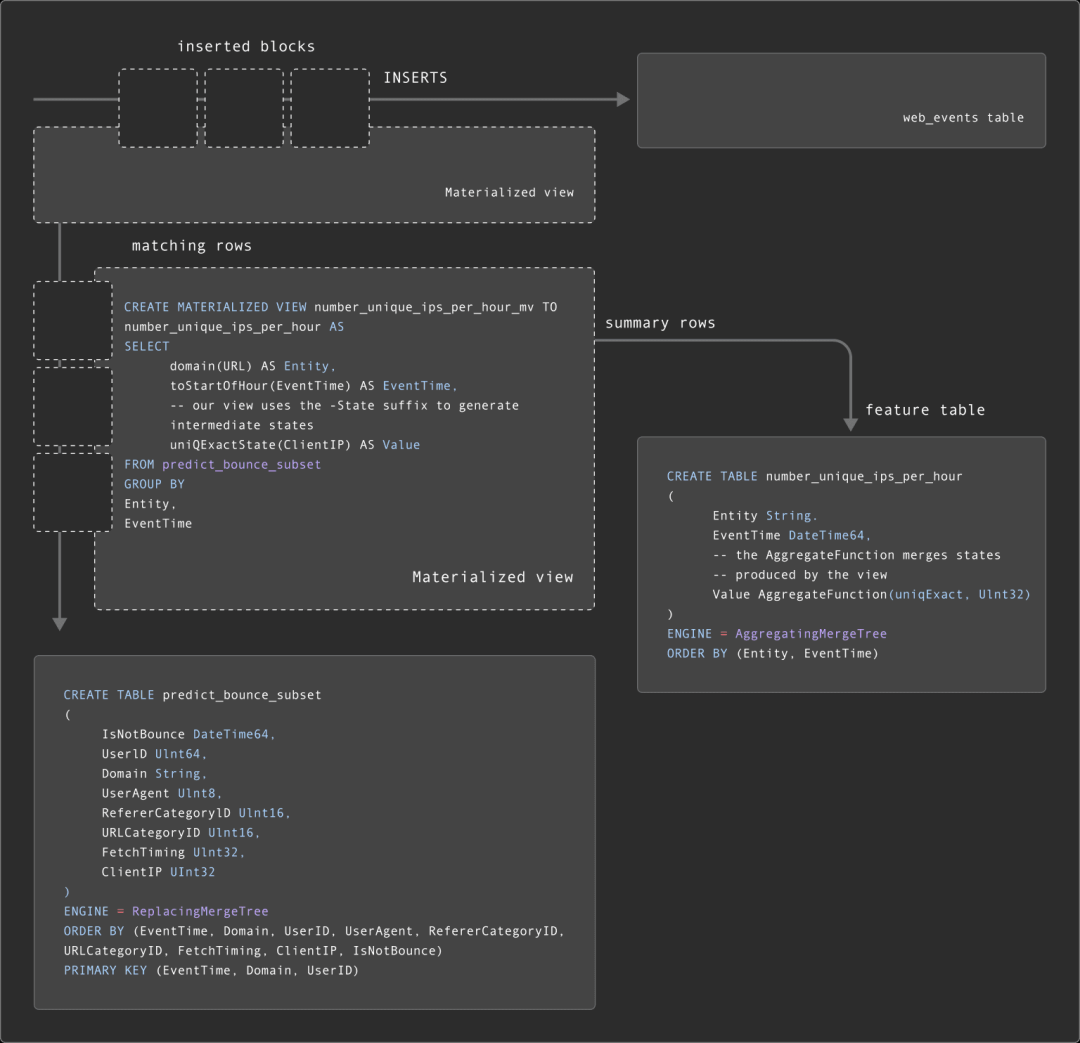
虽然某些特征是静态的,但我们通常希望在源数据或子集发生变化时能够及时更新这些特征。正如“更新子集”部分所述,我们可以通过物化视图来实现这一点。
对于特征表,物化视图通常更加复杂,因为结果往往是聚合操作的结果,而不仅仅是简单的转换和过滤。因此,物化视图执行的查询将生成部分聚合状态。这些部分聚合状态代表了聚合的中间状态,目标特征表可以将其合并。这需要特征表使用带有适当 AggregateFunction 类型的 AggregatingMergeTree。
下面我们展示了一个“每个特征”表的示例,即 number_unique_ips_per_hour。
CREATE TABLE number_unique_ips_per_hour
(
Entity String,
EventTime DateTime64,
-- the AggregateFunction merges states produced by the view
Value AggregateFunction(uniqExact, UInt32)
)
ENGINE = AggregatingMergeTree
ORDER BY (Entity, EventTime)
CREATE MATERIALIZED VIEW number_unique_ips_per_hour_mv TO number_unique_ips_per_hour AS
SELECT
domain(URL) AS Entity,
toStartOfHour(EventTime) AS EventTime,
-- our view uses the -State suffix to generate intermediate states
uniqExactState(ClientIP) AS Value
FROM predict_bounce_subset
GROUP BY
Entity,
EventTime当 predict_bounce_subset 表中插入新行时,我们的 number_unique_ips_per_hour 特征表将自动更新。
在查询 number_unique_ips_per_hour 时,我们必须使用 FINAL 子句或 GROUP BY Entity 和 EventTime,以确保聚合状态与聚合函数的 -Merge 变体(在本例中为 uniqExact)一起合并。如下所示,这将修改查询以获取实体的方式——详见此处【https://clickhouse.com/docs/en/materialized-view#a-more-complex-example】。
-- Select entities for a single domain
SELECT
EventTime,
Entity,
uniqExactMerge(Value) AS Value
FROM number_unique_ips_per_hour
WHERE Entity = 'smeshariki.ru'
GROUP BY
Entity,
EventTime
ORDER BY EventTime DESC LIMIT 5
┌───────────────EventTime─┬─Entity────────┬─Value─┐
│ 2013-07-31 23:00:00.000 │ smeshariki.ru │ 3810 │
│ 2013-07-31 22:00:00.000 │ smeshariki.ru │ 3895 │
│ 2013-07-31 21:00:00.000 │ smeshariki.ru │ 4053 │
│ 2013-07-31 20:00:00.000 │ smeshariki.ru │ 3893 │
│ 2013-07-31 19:00:00.000 │ smeshariki.ru │ 3926 │
└─────────────────────────┴───────────────┴───────┘
5 rows in set. Elapsed: 0.491 sec. Processed 8.19 thousand rows, 1.28 MB (16.67 thousand rows/s., 2.61 MB/s.)
Peak memory usage: 235.93 MiB.尽管这一过程略显复杂,但中间聚合状态允许我们基于上述表格生成不同时间段的特征。例如,我们可以使用此查询从上述表中计算每个域每天的唯一 IP 数量,而这在原始特征表中是无法实现的。
用户可能会注意到,子集表 predict_bounce_subset 已经通过物化视图进行了更新,而这些物化视图又与其他物化视图相连。如下所示,这意味着我们的物化视图实际上是“链式”执行的。关于链式物化视图的更多示例,请参见此处【https://clickhouse.com/blog/chaining-materialized-views】。
更新每个实体的特征表
上述“每个特征”方法意味着每个特征表都需要一个物化视图(因为一个物化视图只能将结果发送到一个表)。在较大规模的使用场景中,这会限制扩展性——物化视图会增加插入时间的开销,因此我们不建议在单个表上使用超过 10 个物化视图。
“每个实体”特征表模型可以减少特征表的数量。然而,要封装多个特征的查询,我们需要使用带有 AggregateFunction 类型的 Variant 类型,但这目前还不支持。
作为替代方案,用户可以使用刷新型物化视图(目前为实验性功能)。与 ClickHouse 的增量物化视图不同的是,这些视图会定期在整个数据集上执行查询,并将结果存储在目标表中,原子性地替换表中的内容。

用户可以利用此功能定期按计划更新特征表。以下是一个示例,其中“每个域的唯一 IP 数量”每 10 分钟更新一次。
--enable experimental feature
SET allow_experimental_refreshable_materialized_view = 1
CREATE MATERIALIZED VIEW domain_features_mv REFRESH EVERY 10 MINUTES TO domain_features AS
SELECT
Domain,
'number_unique_ips_per_hour' AS FeatureId,
toStartOfHour(EventTime) AS EventTime,
uniqExact(ClientIP) AS Value
FROM predict_bounce_subset
GROUP BY
Domain,
EventTime有关刷新型物化视图的更多详细信息,请参见此处【https://clickhouse.com/docs/en/materialized-view/refreshable-materialized-view】。
步骤 4 - 生成模型数据
在特征创建完成后,我们可以开始将这些特征组合成模型数据,这些数据将成为训练、验证和测试集的基础。
该表中的每一行将构成我们模型的基础,每一行对应一个特征向量。要生成这些特征向量,我们需要将各个特征进行联接。其中一些特征将来自特征表,另一些则直接来自我们的“特征子集”表,即上文提到的 predict_bounce_subset。
由于特征子集表包含事件的标签、时间戳和实体键,因此将其作为联接的基础表(左侧)是合理的。它也是最大的表,因此作为左侧表是明智的选择。
特征将基于以下两个标准与此表联接:
-
每个特征的时间戳(EventTime)与特征子集表(predict_bounce_subset)中的行最接近。
-
特征表的对应实体列,例如 UserID 或 Domain。
要基于等值连接和最近时间戳进行联接,需要使用 ASOF JOIN。
我们将使用 INSERT INTO 将联接的结果写入一个新表,即“模型表”。这个表将用于生成未来的训练、验证和测试集。
在探讨联接之前,我们先定义我们的“模型表” predict_bounce。
CREATE TABLE predict_bounce_model (
Row UInt64,
EventTime DateTime64,
UserID UInt64,
Domain String,
UserAgent UInt8,
RefererCategoryID UInt16,
URLCategoryID UInt16,
DomainsVisitedPerHour UInt32 COMMENT 'Number of domains visited in last hour by the user',
UniqueIPsPerHour UInt32 COMMENT 'Number of unique ips visiting the domain per hour',
AverageRequestTime Float32 COMMENT 'Average request time for the domain per hour',
IsNotBounce UInt8,
) ENGINE = MergeTree
ORDER BY (Row, EventTime)此处的 Row 列将为数据集中的每一行生成唯一条目。我们将其纳入 ORDER BY 中,稍后利用这一点来高效地产生训练集和测试集。
连接和对齐特征
为了根据实体键和时间戳连接和对齐特征,我们可以使用 ASOF JOIN。具体的 JOIN 构建方式取决于我们使用的是“每个特征”还是“每个实体”特征表。
假设我们使用的是“每个特征”表,并且有以下几个表可用:
-
number_unique_ips_per_hour:每小时访问每个域的唯一 IP 数量(见上述示例)。
-
domains_visited_per_hour:每个用户在过去一小时内访问的域数量(使用这里的查询生成【https://pastila.nl/?02af4d88/82927122387952892b23b7e8e90738bd#tsngZtbhHCxFhr5mVuB07w==】)。
-
average_request_time:每小时每个域的平均请求时间(使用这里的查询生成【https://pastila.nl/?07708678/211b6c5f5d81b9818496b91efaaa78f7#SX1/LZuj+7fsAYPSsvu4qQ==】)。
这个 JOIN 比较简单:
INSERT INTO predict_bounce_model SELECT
rand() AS Row,
mt.EventTime AS EventTime,
mt.UserID AS UserID,
mt.Domain AS Domain,
mt.UserAgent,
mt.RefererCategoryID,
mt.URLCategoryID,
dv.Value AS DomainsVisitedPerHour,
uips.Value AS UniqueIPsPerHour,
art.Value AS AverageRequestTime,
mt.IsNotBounce
FROM predict_bounce_subset AS mt FINAL
ASOF JOIN domains_visited_per_hour AS dv ON (mt.UserID = dv.UserID) AND (mt.EventTime >= dv.EventTime)
ASOF JOIN number_unique_ips_per_hour AS uips ON (mt.Domain = uips.Domain) AND (mt.EventTime >= uips.EventTime)
ASOF JOIN average_request_time AS art ON (mt.Domain = art.Domain) AND (mt.EventTime >= art.EventTime)
0 rows in set. Elapsed: 13.440 sec. Processed 89.38 million rows, 3.10 GB (6.65 million rows/s., 230.36 MB/s.)
Peak memory usage: 2.94 GiB.
SELECT * FROM predict_bounce_model LIMIT 1 FORMAT Vertical
Row 1:
──────
Row: 57
EventTime: 2013-07-10 06:11:39.000
UserID: 1993141920794806602
Domain: smeshariki.ru
UserAgent: 7
RefererCategoryID: 16000
URLCategoryID: 9911
DomainsVisitedPerHour: 1
UniqueIPsPerHour: 16479
AverageRequestTime: 182.69382
IsNotBounce: 0然而,如果使用“每个实体”特征表,JOIN 会变得稍微复杂一些(同时成本也更高)。假设我们使用这些查询填充了特征表 domain_features 和 user_features。
INSERT INTO predict_bounce_model SELECT
rand() AS Row,
mt.EventTime AS EventTime,
mt.UserID AS UserID,
mt.Domain AS Domain,
mt.UserAgent,
mt.RefererCategoryID,
mt.URLCategoryID,
DomainsVisitedPerHour,
UniqueIPsPerHour,
AverageRequestTime,
mt.IsNotBounce
FROM predict_bounce_subset AS mt FINAL
ASOF LEFT JOIN (
SELECT Domain, EventTime, Value.UInt64 AS UniqueIPsPerHour
FROM domain_features
WHERE FeatureId = 'number_unique_ips_per_hour'
) AS df ON (mt.Domain = df.Domain) AND (mt.EventTime >= df.EventTime)
ASOF LEFT JOIN (
SELECT Domain, EventTime, Value.Float64 AS AverageRequestTime
FROM domain_features
WHERE FeatureId = 'average_request_time'
) AS art ON (mt.Domain = art.Domain) AND (mt.EventTime >= art.EventTime)
ASOF LEFT JOIN (
SELECT UserID, EventTime, Value.UInt64 AS DomainsVisitedPerHour
FROM user_features
WHERE FeatureId = 'domains_visited_per_hour'
) AS dv ON (mt.UserID = dv.UserID) AND (mt.EventTime >= dv.EventTime)
0 rows in set. Elapsed: 12.528 sec. Processed 58.65 million rows, 3.08 GB (4.68 million rows/s., 245.66 MB/s.)
Peak memory usage: 3.16 GiB.上述 JOIN 使用了哈希连接。24.7 版本为 ASOF JOIN 添加了对 full_sorting_merge 算法的支持。该算法可以利用表的排序顺序,从而避免在 JOIN 之前进行排序。在排序和合并操作之前,表可以通过各自的连接键进行过滤,从而减少处理的数据量。这样可以让上述查询更快且消耗更少的资源。
步骤 5 - 生成测试集和训练集
在生成模型数据之后,我们可以创建训练集、验证集和测试集。这些集合通常由数据的不同比例组成,例如 80%、10%、10%。在查询执行过程中,需要确保结果的一致性——不能让测试数据混入训练集,反之亦然。此外,结果集需要保持稳定,因为某些算法可能会因数据的顺序不同而产生不同的结果。
为了确保结果的稳定性和一致性,同时保证查询的速度,我们可以利用 Row 和 EventTime 列。
假设我们希望按 EventTime 顺序提取 80% 的数据用于训练。可以通过对 predict_bounce_model 表执行一个简单的查询来实现,这个查询对 Row 列进行 mod 100 运算:
SELECT * EXCEPT Row
FROM predict_bounce_model
WHERE (Row % 100) < 80
ORDER BY EventTime, Row ASC我们可以通过几个简单的查询验证这些行是否提供了稳定的结果:
SELECT
groupBitXor(sub) AS hash,
count() AS count
FROM
(
SELECT sipHash64(concat(*)) AS sub
FROM predict_bounce_model
WHERE (Row % 100) < 80
ORDER BY
EventTime ASC,
Row ASC
)
┌─────────────────hash─┬────count─┐
│ 14452214628073740040 │ 34315802 │
└──────────────────────┴──────────┘
1 row in set. Elapsed: 8.346 sec. Processed 42.89 million rows, 2.74 GB (5.14 million rows/s., 328.29 MB/s.)
Peak memory usage: 10.29 GiB.
--repeat query, omitted for brevity
┌─────────────────hash─┬────count─┐
│ 14452214628073740040 │ 34315802 │
└──────────────────────┴──────────┘同样,训练集和验证集可以通过以下查询获得,每个占据 10% 的数据:
-- validation
SELECT * EXCEPT Row
FROM predict_bounce_model
WHERE (Row % 100) BETWEEN 80 AND 89
ORDER BY EventTime, Row ASC
-- test
SELECT * EXCEPT Row
FROM predict_bounce_model
WHERE (Row % 100) BETWEEN 90 AND 100
ORDER BY EventTime, Row ASC用户可能会根据自己划分训练集和测试集的需求来选择具体的方法。对于我们的模型来说,可能更适合使用某个固定时间点之前的所有数据进行训练,而将测试集设为之后的数据。上述示例中,我们的训练和测试样本数据覆盖了整个时间段。这可能会导致两组数据之间的信息泄漏,例如来自同一次页面访问的事件。为了示例目的,我们忽略了这一点。建议根据实际需求调整模型表上的排序键——关于选择排序键的建议,请参见此处【https://clickhouse.com/docs/en/data-modeling/schema-design#choosing-an-ordering-key】。
构建与采用
上述过程涉及多个查询和复杂的操作。在使用 ClickHouse 构建离线特征存储时,用户通常采取以下几种方法:
-
构建自己的特征存储:这是最为先进且复杂的一种方法,用户可以根据特定数据优化流程和架构。通常适用于那些特征存储对业务至关重要且涉及大量数据的公司,如广告技术领域。
-
Dbt + Airflow:Dbt 是一种流行的工具,用于管理数据转换和处理复杂查询及数据建模。当与强大的工作流编排工具 Airflow 结合使用时,用户可以自动化并调度上述流程。该方法提供了模块化且易于维护的工作流,在不需要完全定制特征存储的情况下,平衡了定制解决方案与现有工具的使用,适用于处理大数据量和复杂查询的场景。
-
采用 ClickHouse 的特征存储:如 Featureform 等特征存储集成了 ClickHouse,用于数据存储、转换和提供离线特征。这些平台可以管理流程、版本控制特征,并执行治理和合规性规则,从而减轻数据科学家在数据工程方面的负担。是否采用这些技术取决于其抽象和工作流与具体使用场景的适配程度。
来源:Featureform 特征存储
在推理阶段使用 ClickHouse
本文讨论了如何使用 ClickHouse 作为离线存储来生成模型训练所需的特征。在模型训练完成后,模型可以被部署用于预测,这时需要实时数据,如用户 ID 和域名。一些预计算的特征(如“过去一小时访问的域名”)在预测时是必要的,但在推理阶段计算这些特征成本过高。因此,这些特征需要基于最新数据版本进行提供,尤其是在进行实时预测时。
ClickHouse 作为一个实时分析数据库,得益于其日志结构合并树,能够处理高并发查询,提供低延迟和高写入负载。这使其非常适合用于在线特征存储。离线存储中的特征可以通过现有功能物化到同一 ClickHouse 集群中的新表或不同实例中。关于这一过程的更多细节将会在后续文章中介绍。
结论
本文概述了使用 ClickHouse 作为离线特征存储和转换引擎的常见数据建模方法。虽然内容并不全面,但这些方法为使用 ClickHouse 提供了一个起点,并且与像 Featureform 这样集成了 ClickHouse 的特征存储中的技术相契合。我们欢迎大家的贡献和改进建议。如果您也在使用 ClickHouse 作为特征存储,请与我们分享您的经验!
了解如何在 ClickHouse 中建模机器学习数据,以加速您的数据管道,并快速构建可能涉及数十亿行的数据特征。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求















 1552
1552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









