








本文字数:7791;估计阅读时间:20 分钟
作者:Dmitry Pavlov
本文在公众号【ClickHouseInc】首发

在 ClickHouse,我们的使命是为客户和用户提供一个高性能的云分析数据库,既用于内部分析,也面向客户的分析需求。ClickHouse Cloud 让客户能够存储和处理海量数据,帮助他们在决策中依赖数据而非假设。对如今的成功企业来说,基于事实做出决策至关重要。
同样,我们的团队在内部也遵循这一理念。开发和运营我们的云数据库产品会生成大量数据,这些数据用于容量规划、定价、深入了解客户需求和财务报告。我们目前处理来自数十个数据源的数百TB数据,服务约一百名 BI 和临时查询用户……正如你所猜的,我们也是用 ClickHouse Cloud 来完成这些工作的 :)
在这篇文章中,我将分享我们是如何构建内部数据仓库(DWH)的,介绍所使用的技术栈,以及未来几个月内 DWH 的发展方向。
DWH 的需求和数据源
我们于 2022 年 5 月发布了 ClickHouse Cloud 私有预览版,同时意识到需要更深入地了解客户的使用情况:他们如何使用我们的服务,遇到了哪些挑战,我们如何为他们提供帮助,并制定合理的定价方案。为此,我们需要整合多个内部数据源,包括数据平面 (Data Plane),负责管理客户的数据库节点;控制平面 (Control Plane),负责客户界面和数据库操作;以及 AWS 计费,提供我们运行客户工作负载的成本数据。
在早期阶段,产品副总裁 Tanya Bragin 曾一度通过 Excel 每日手动分析客户的工作负载。作为一名前数据仓库架构师,我看到这种情况后决定打造一个内部数据仓库系统,从而诞生了第一个版本的概念。
我们在设计 DWH 时,目标是满足内部各团队的关键需求,以下是部分任务列表:
| 内部团队 | 任务 |
| 产品团队 | 跟踪转换率、留存率、功能使用、服务数量和规模,发现最常见的问题,并进行深入的临时分析。 |
| 运营团队 | 跟踪收入预估,并为公司大部分团队提供 Salesforce 数据的只读访问权限。 |
| 销售团队 | 查看客户的设置与使用情况:服务数量、数据量、常见问题等。 |
| 工程团队 | 优化自动扩展,跟踪查询错误率和数据库功能的使用情况。 |
| 支持团队 | 查看客户的设置:服务数量、使用情况、数据量等。 |
| 市场团队 | 跟踪漏斗顶部的转换率、客户获取成本及其他营销指标。 |
| 成本优化团队 | 分析云服务提供商 (CSP) 的成本,并主动优化 CSP 的使用承诺。 |
| CI-CD 团队 | 监控 CI-CD 成本。 |
请注意:在内部数据仓库中,我们不会收集、存储或处理客户的任何数据(大部分是加密的),例如表数据、查询文本、网络数据等。我们只收集查询相关的元信息,如使用的函数列表、查询运行时间、内存使用情况等,而不会涉及查询数据或文本内容。
为了实现这一目标,我们计划从数十个数据源中摄取数据,主要包括以下内容:
| 数据源 | 类型与大小 | 数据内容 |
| 控制平面 (Control Plane) | DocumentDB ~5 个集合,每小时约 500 Mb | 包含数据库服务的元信息,如类型、大小、CSP 区域、状态、财务计划、扩展设置等。 |
| 数据平面 (Data Plane) | ClickHouse Cloud ~5 张表,每小时约 15 Gb | 包含数据库系统的各类指标统计,如查询、表、节点分配等。 |
| AWS 成本与使用报告 (CUR) | S3 存储桶,1 张表,每小时约 1 Gb | 记录我们 AWS 基础设施的使用情况和成本。 |
| GCP 计费 | BigQuery 1 张表,每小时约 500 Mb | 记录我们 GCP 基础设施的使用情况和成本。 |
| Salesforce (CRM) | 自定义,~30 张表,每小时约 1 Gb | 包含客户账户、使用计划、订阅、折扣、区域、潜在客户及支持问题等信息。 |
| M3ter | 自定义 API,2 个 API,每小时约 500 Mb | 提供精确的使用信息和账单数据。 |
| Galaxy | ClickHouse Cloud 1 张表 | Galaxy 是我们基于事件的可观测性和监控系统,覆盖控制平面/UI 层。 |
| Segment | S3 存储桶,1 张表 | 包含一些额外的营销数据。 |
| Marketo | 自定义 | 发送电子邮件的元信息。 |
| AWS 公共价格 | 自定义 API,3 张表 | 每个 AWS SKU 在各区域的价格信息。 |
| GCP 价格 | CSV 文件 | 发送电子邮件的元信息。 |
根据我们的核心目标,我们做了以下假设:
-
在现阶段,每小时的粒度足够满足需求,即每小时收集和存储汇总数据即可。
-
目前无需使用 CDC(变更数据捕获)方法,因为这会大幅增加数据仓库基础设施的成本。
我们可以通过传统的直接加载或 ETL 来处理需求,并在必要时执行全量数据重新加载。
-
我们拥有高扩展性和高性能的数据库,因此 ETL 转换直接在 ClickHouse 中通过 SQL 执行即可,无需在数据库外进行转换。
-
ClickHouse 是开源的,我们也希望我们的技术栈完全由开源组件构成,并且我们乐于为开源社区做出贡献。
-
面对多种数据源类型,我们需要采用不同的工具和方法进行数据提取,同时保持标准化的中间存储。
然而,我们最初的一个假设不正确。我们以为数据结构简单,只需要两个逻辑层:原始数据层和“数据集市”层。但实际上,我们还需要第三个中间层来存储内部业务实体。我们将在后文中进一步解释。
架构
我们设计了以下架构:
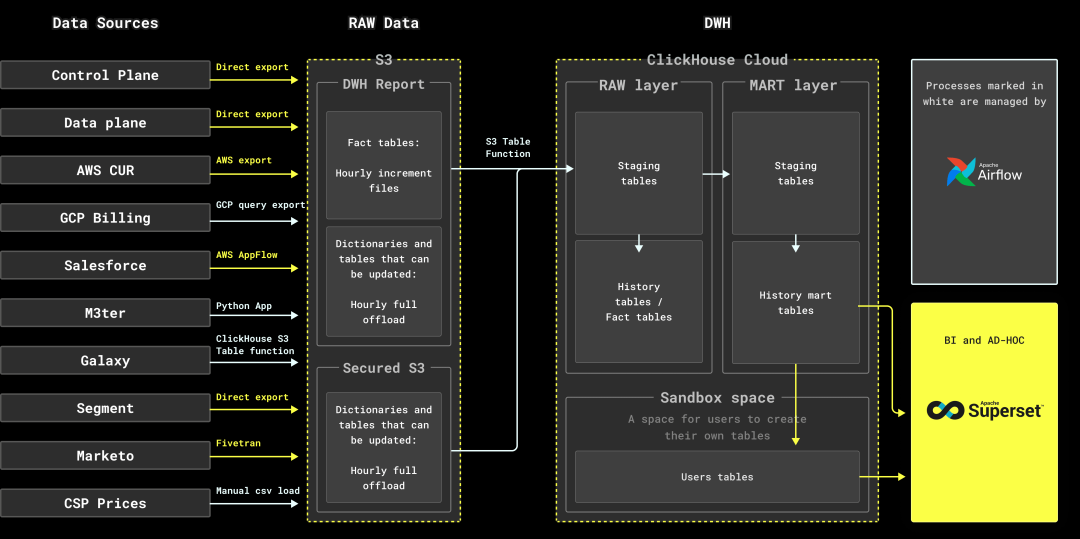
1. 从整体来看,我们的技术栈包括:
-
ClickHouse Cloud 作为核心数据库
-
Airflow 作为开源调度器
-
AWS S3 用于原始数据的中间存储
-
Superset 用作内部 BI 和即席分析工具
2. 我们采用了多种工具和方法来从数据源中获取数据,并将其导入多个 S3 存储桶:
-
对于控制平面、数据平面、Segment 和 AWS CUR,使用其原生导出功能
-
GCP 计费数据通过 BigQuery 导出到 GCS,随后用 ClickHouse S3 表函数导入
-
Salesforce 数据通过 AWS AppFlow 传输
-
为捕获 M3ter 数据,我们开发了自己的应用程序,最初基于 Kotlin,后迁移到 Python
-
Galaxy 数据(由 ClickHouse Cloud 集群管理)通过 ClickHouse S3 表函数导出至 S3
-
Marketo 数据由 Fivetran 处理
-
AWS 和 GCP 的价格数据变化较少,因此我们通过脚本手动更新,而非自动化处理
3. 对于大型事实表,我们每小时收集增量数据。对于既接收新行又有更新的表格,采用“全表替换”方法,每小时下载完整表格。
4. 数据被收集到 S3 存储桶后,使用 ClickHouse S3 表函数将数据导入 ClickHouse 数据库。S3 表函数在副本之间扩展,处理大数据量时表现出色。
5. 数据首先进入数据库的原始层,该层与数据源的表结构保持一致。
6. 之后,Airflow 执行一系列数据转换(如表关联操作),将处理后的数据插入 MART 表,这些表体现业务实体,并满足内部团队的需求。
在数据转换过程中,我们使用了许多临时表。转换结果会先写入暂存表,随后再插入目标表。这种方式虽然增加了复杂性,但能有效复用增量数据,无需重新计算或扫描目标表。每次 Airflow DAG 运行都会生成具有唯一名称的暂存表。
7. 最后,通过 Superset BI 工具,内部用户可以直接查询 MART 表,创建图表和仪表板:
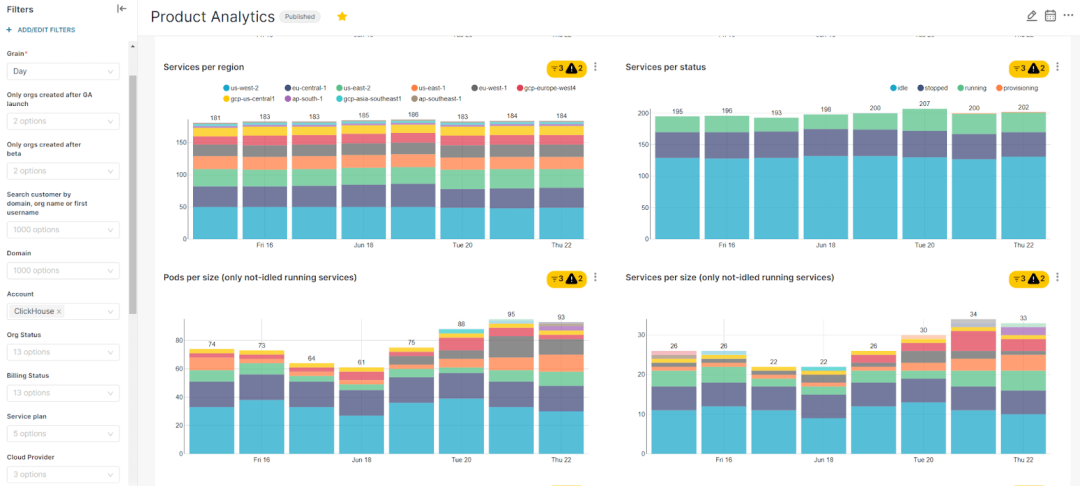
示例 Superset 仪表板。注意:此处为演示目的,使用了虚构的示例数据。
幂等性
我们大多数 ClickHouse 表使用的是 ReplicatedReplacingMergeTree 引擎。这允许我们无需担心重复数据问题,具有相同键的记录会自动合并,仅保留最后一条记录。这也意味着,即使我们多次插入同一小时的数据,最终每行只保留最新版本。在进一步的数据处理步骤中,为了确保数据的一致性,我们会在表上使用 ClickHouse 的 “FINAL” 功能,例如防止 sum() 函数重复计算某行数据。
结合 Airflow 的作业和 DAG(有向无环图),它们能够在同一时间段多次运行,我们的整个数据处理管道实现了幂等性,这意味着可以放心地多次重跑而不会产生重复数据。关于 Airflow 的更多设计细节,我们将在后续章节详细介绍。
一致性
ClickHouse 默认提供的是最终一致性。也就是说,虽然插入操作可能成功,但不能保证新数据会立即同步到所有副本中。对于实时分析,这种一致性已经足够,但在数据仓库场景下可能导致问题。比如,如果你在暂存表插入数据后立即开始后续查询,可能只会得到部分数据。
为了解决这个问题,ClickHouse 提供了一种模式,适用于数据一致性优先于数据立即可用性的场景。为确保数据在所有副本接收后才返回“成功”,我们在所有插入操作中使用了 insert_quorum=3 这一设置(因为我们的集群包含三个节点)。我们避免使用 “auto” 模式,因为在进行如 ClickHouse 升级等操作时,某个节点可能会暂时不可用,这时剩下的两个节点仍然可以接受插入操作。当宕机的节点恢复后,它可能缺失部分数据。因此,我们宁愿在插入少于三个副本时收到错误提示(副本不足错误)。由于节点升级通常较快,Airflow 会在重试后成功执行查询。
虽然这种方法不能完全避免未提交数据被查询看到,但由于我们支持幂等性机制,这并不会影响最终结果。另一种方案是让所有的 ELT 处理仅使用一个副本,但这可能会影响系统性能。
内部基础设施设计
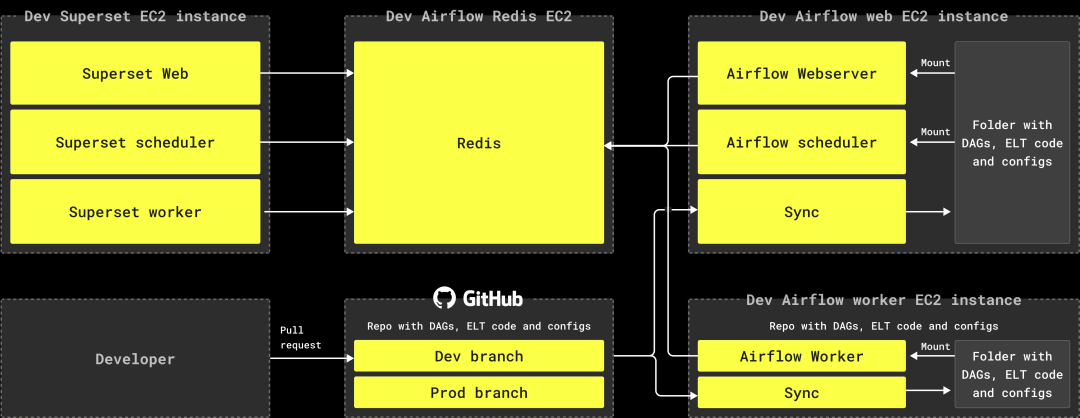
为了满足我们的规模需求,我们的 DWH 基础设施必须简单、易操作、且易于扩展。最初在 AWS EC2 上进行 PoC 后,我们将所有基础设施组件迁移至 Docker 容器中。
-
我们为 Airflow 和 Superset 分配了独立的机器,并将所有组件打包在 Docker 容器中。
-
在 Airflow 机器上,我们每 5 秒运行一个容器来同步 DAG 代码、ELT 查询和配置文件。
-
Superset 使用仪表盘和告警功能,因此设置了调度程序和 worker 容器。
-
所有的 Airflow 和 Superset 组件通过一个 Redis 实例进行同步。
Redis 存储了 Airflow 的作业状态、Superset 的缓存查询结果等服务信息。
-
我们使用 AWS RDS 中的 PostgreSQL 作为 Airflow 和 Superset 的内部数据库。
-
目前,我们在不同区域拥有两个独立运行的环境,各自有自己的 ClickHouse Cloud 实例、Airflow 和 Superset 安装。
-
即使一个环境被称为 Preprod,另一个是 Prod,我们保持 Preprod 环境的同步,以确保在 Prod 不可用时可以快速切换。
这样的架构使我们的发布流程变得更加安全和高效:
-
开发人员从开发或生产分支创建新分支
-
开发人员完成更改
-
开发人员向 Preprod 分支提交 PR
-
PR 审核通过后,变更会部署到 Preprod 环境进行测试
-
当准备好上线时,会从 Preprod 分支向生产分支提交 PR
Airflow 内部设计
最初,我们计划创建一个复杂的 DAG 系统,包含众多依赖关系。然而,Airflow 的现有 DAG 依赖机制无法满足我们的架构需求(这也是 Airflow 常见的问题):
-
Airflow 不允许在不同执行过程中使用不同的数据集名称。
因此,新数据集无法使用临时名称。
如果使用静态名称,下游 DAG 只能处理最后一个增量数据。
-
触发器虽然可行,但会导致系统过于复杂。
对 10-20 个带有触发器的 DAG 进行操作和维护,从运营角度看是非常困难的。
因此,我们最终选择了以下结构:
-
为每个数据源到 S3 的数据加载创建独立的 DAG(例如,M3ter -> S3)。
-
一个处理所有数据转换的大型主 DAG,在数据传输到 S3 后执行。
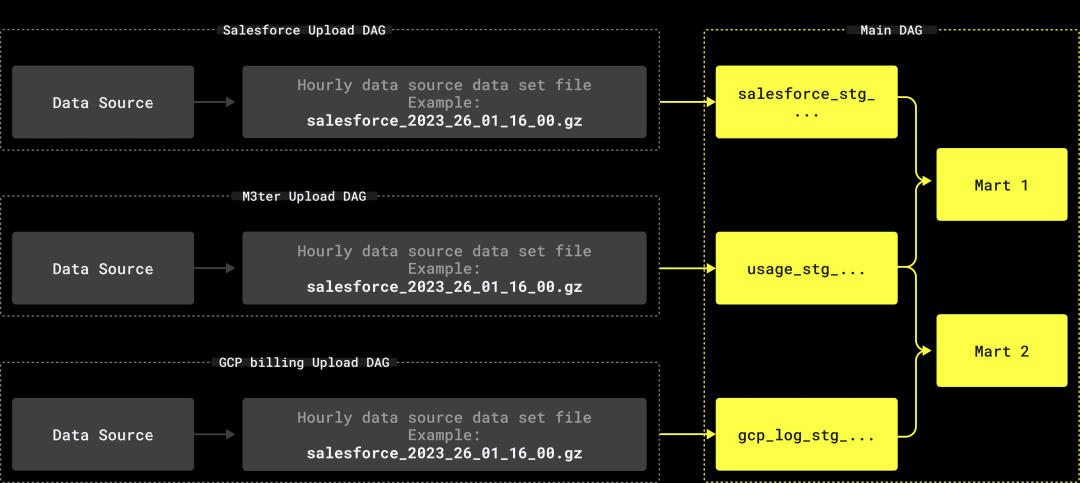
这种结构的主要优势在于,主 DAG 清晰列出了所有依赖关系,同时还能够构建与失败数据集无关的实体。
安全性
我们的内部 DWH 系统存储着敏感数据,包括个人身份信息(PII)和财务数据,因此安全性是架构的基础。我们实施了一系列基本规则和框架来确保系统的安全。
一般规则
-
不同的数据应根据公司角色模型自动分配给相应的用户。
-
权限应在数据库级别进行分离,而不是在 BI 工具端。
-
各个层面都应有网络访问限制(例如,从使用 Okta 认证到 IP 过滤)。
实现
我们通过 Google 群组控制内部用户的权限。这使我们能够使用现有的公司群组,并且群组所有者(无需具备 SQL 技术的非技术人员)也可以管理对不同数据的访问。群组之间可以嵌套。例如:
-
general_data@clickhouse.com
-
company@clickhouse.com
-
-
financial_data@clickhouse.com
-
thor@clickhouse.com
-
ironman@clickhouse.com
-
thehulk@clickhouse.com
-
scrooge@clickhouse.com
-
-
hr_data@clickhouse.com
-
captain_clickhouse@clickhouse.com
-
chip@clickhouse.com
-
superman@clickhouse.com
-
为了将 Google 群组与数据库中的具体权限匹配,我们建立了一个系统表,其中包括以下关联信息:
-
Google 群组名称
-
数据库名称
-
表名
-
列的数组
-
过滤条件(例如,"where organization='clickhouse'")
-
访问类型(SELECT, INSERT)
我们编写了一个脚本来执行以下操作:
-
获取群组及其用户的递归列表
-
在数据库中创建或替换用户,并分配唯一密码
-
创建与 Google 群组对应的角色
-
为用户分配角色
-
根据权限表为角色授予权限,并使用 “WITH REPLACE OPTION” 子句,这将清除之前可能手动授予的权限
在 Superset 端,我们通过 DB_CONNECTION_MUTATOR 函数,将发送到数据库的用户名替换为 Superset 用户名。我们还在 Superset 中启用了 Google Oauth。
def DB_CONNECTION_MUTATOR(uri, params, username, security_manager, source):
# Only enable mutator on clickhouse cloud endpoints
if not uri.host.lower().endswith("clickhouse.cloud"):
return uri, params
user = security_manager.find_user(username=username)
generated_username = str(user.email).split('@')[0] + '--' + str(user.username)
uri.username = generated_username
# Password generation logic - hidden in this example
uri.password = ...
return uri, params这意味着 Superset 会为每个用户生成一个唯一的数据库用户名,其权限由 Google 群组控制。
GDPR 合规性
ClickHouse Cloud 用户可以请求删除其所有个人数据,包括姓名、电子邮件等信息。当然,在这种情况下,我们也会从数据仓库中删除这些数据。值得注意的是,我们无需在 ClickHouse 表中执行更新或删除操作。由于我们的引擎只会保留相同键值的最新记录,因此我们只需插入一条新版本的行,替换掉已删除用户的数据。旧数据会在几小时内消失,而 GDPR 规定的数据删除期限通常在 3 至 30 天内,因此这一流程完全符合要求。具体步骤如下:
-
在源系统中找到一个标记,表示该用户 ID 需要被删除或屏蔽
-
从表中筛选出与该 ID 相关的所有记录
-
屏蔽或删除需要处理的字段
-
将处理后的数据重新插入表中
-
运行 “optimize table … final” 命令,确保旧记录从磁盘中彻底清除
-
在新数据插入时,我们会与已删除 ID 的列表进行比对,确保未被完全删除的用户数据也会自动屏蔽
改进与未来计划
虽然我们对现有的数据仓库系统总体上感到满意,但我们计划在未来几个月内做一些改进:
引入第三层逻辑结构
原本我们设想的数据仓库只需要两层逻辑结构,但在实际操作中,这种设计在处理复杂数据时存在局限。特别是需要从多个数据源提取信息并回填的情况下,数据集市之间会产生相互依赖,甚至出现递归依赖。为了解决这个问题,我们计划引入一个名为“详细数据存储(DDS)”的中间层,用于存储账户、组织和服务等内部业务实体。此中间层不会对终端用户开放,但它有助于简化各个数据集市之间的依赖关系。
DBT 集成
Airflow 是一个出色的调度器,但我们还需要一个工具来处理其他任务,例如:重新加载数据集市、质量检查、数据描述和文档生成等。为此,我们计划将 Airflow 与 DBT 集成。由于我们的数据基础设施都运行在 Docker 容器中,因此通过 Airflow DAG 触发的 DBT 容器可以很方便地创建和运行。
命名规范
虽然我们从一开始就意识到需要为表格、字段和图表的命名制定一定的规则,但我们并没有投入足够的资源来优化这一过程。因此,现在的命名方式较为混乱,用户难以准确理解某些表格或字段的具体用途。我们计划对此进行改善,确保命名更加清晰和一致。
资源情况
ClickHouse 作为一家相对年轻的公司,数据仓库(DWH)团队规模较小,目前仅有三名成员:
-
数据工程师,负责构建并维护整个基础设施;
-
产品分析师,协助用户获取数据洞察、构建图表并理解数据;
-
团队负责人,将大约 30% 的时间花在 DWH 相关任务上。
在基础设施方面,我们部署了两个独立环境,每个环境都使用 ClickHouse Cloud 服务,每个服务包含三个节点(即副本,且所有副本都可同时接受查询)。我们的 ClickHouse 云服务内存使用量约为 200 GB。由于我们是 ClickHouse Cloud 团队的一部分,所以不需要为这些服务支付费用。我们也研究了市场上的其他云分析数据库,发现它们的成本相对较高。
此外,我们的基础设施还包括 8 台 EC2 服务器以及一个存储原始数据的 S3 存储桶。综合起来,这些服务每月的总成本大约为 1,500 美元。
运行成果
我们的数据仓库已经稳定运行一年多,目前拥有 70 多名活跃用户、数百个仪表板和上千个图表。每天大约处理 40,000 次查询,下面的图表展示了每天查询量的变化,数据已按用户分类(系统用户和 ELT 用户除外):
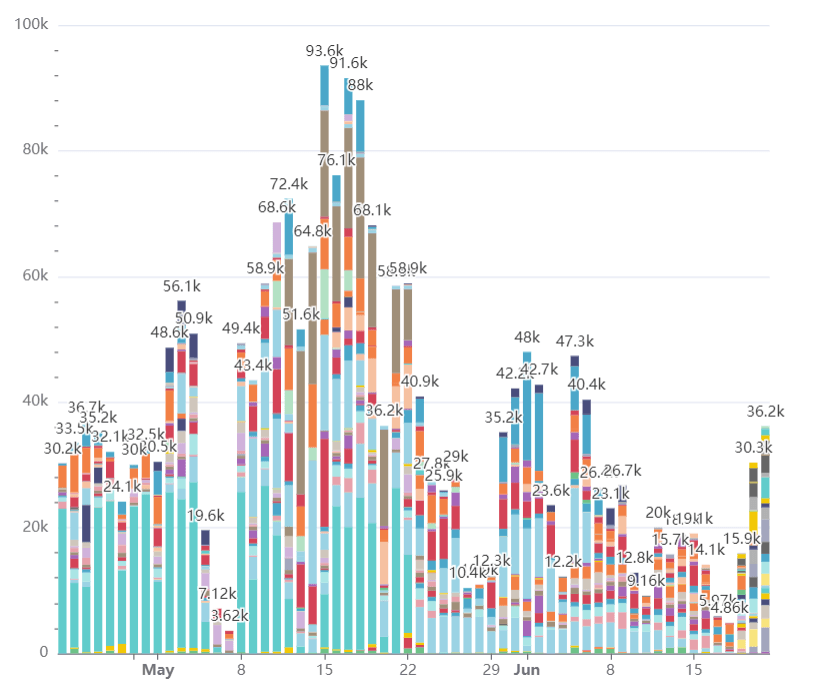
是的,我们的用户甚至在周末也在工作。
我们在 150 张表中存储了大约 115 TB 的未压缩数据,但由于 ClickHouse 的高效压缩,实际存储的数据量仅为 13 TB。
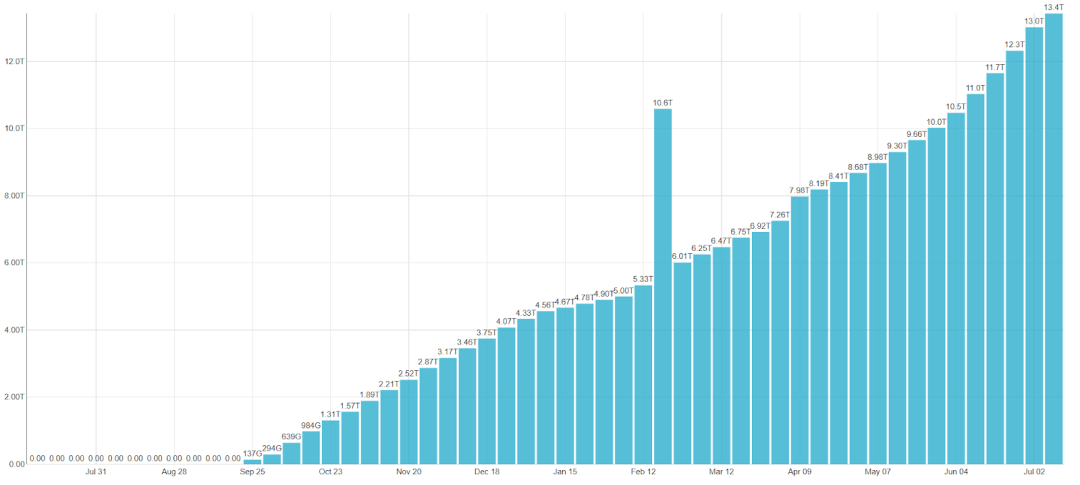
以下图表显示了我们数据仓库中的数据量每周增长的情况。2 月份的峰值是由于我们进行了一项内部实验,该实验需要对所有数据进行复制。
总结
在过去的一年里,我们基于开源技术构建了一个广受用户好评的数据仓库(DWH)。尽管该系统已让用户能轻松处理和分析数据,但我们也认识到许多可以进一步优化的地方。我们相信,ClickHouse Cloud 的使用验证了它在构建可靠数据仓库中的潜力。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









