







可怕,我已经overdue了两个星期的课程了,前天花了一整天把视频看完,作业完成,这看似很平淡的叙述其实充满了艰辛,大哭,Octave的编程让我好心累,来回调了好多次,经历了从信心满满到万念俱灰,又重拾信心,告诫自己要冷静,最后submit成功的一个曲折过程,看到最后全部程序测试通过,我真的好感动。。。
好,下面来总结一下学习内容。
一开始就讲了non-linear hypothesis(非线性估计),这是当数据无法用简单的线性模型处理的时候采用的方法,然后Andrew就开始讲神经网络了,这一周的内容没有很详细,就是大概地让你知道一下神经网络,产生一个初步的印象。
还是先来把用到的符号交代了吧。
| 符号 | 含义 |
|---|---|
| θ(j) | 从
j
到 |
| a(j)i | 第
i
个单元在第 |
还用到一个 θ , 这是前文讲过的,就不多说了,好,我觉得这里需要一张图,等等我去找下。
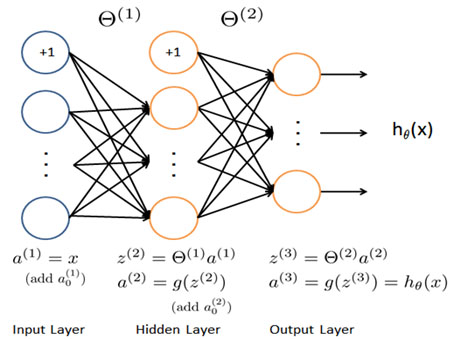
虽然不熟悉Markdown的语法,但我还是用自己的方法注明了引用,教授我们都是中国人…用一下你的图不要打我。
最左边那一层蓝色的圆圈就是 a(1) ,也就是输入的x,然后加入一个“bias unit”,看到没有就是上面的+1,给每个圆圈一个权值,把他们按权相加,就得到了第二层的第一个值,也就是 z(2)1 ,换一组权值再进行计算,就算出了 z(2)2 ,如此进行下去就得到了一列第二行的初始值。
那么怎么让这些
z
变成
我不知道这是哪里来的,反正教授这么教,我就这么用,效果还不错。
图上其实也有这个公式:
再给第二层加一个bias unit,进行同样的步骤就可以算出第三层、第四层,甚至一直算下去。好到这里有个问题,那些权值是谁定的?从第一层到第二层的各种权值可以组成一个叫做 Θ1 的 矩阵,一组权值对应 Θ1 中一行。后面也是依样画葫芦,出现了一个 Θ2 。这些权值哪里来的课程内容还没有涉及,写程序的时候教授也是提前帮我们把这些权值设定好了,这样我们在学习神经网络的时候就可以先忽略一些暂时不是很重要的细节,哈哈哈,Stanford Rock!
So far, 只是说了这个模型怎么计算,它是用来干什么的呢?这周的学习介绍了神经网络可以用来分类数据,作业里的例子是识别手写数字,输入一张规定大小的灰度图片,用神经网络来预测它上面写的是什么。
输入的数据是 20×20 的灰度图片所转化成的400个代表亮度的数字,训练量5000次,训练难道是用来确定那些权值的吗?留个疑问,训练完成以后用此模型进行预测,就是按照上面的步骤一直算算算,算到最后得到了一个 10×5000 的矩阵,因为有10个类别(0-9),指定行的每一列代表了这个图像属于这个分类的概率,于是我们用一个max函数取每行最大值所在的索引序号,这个序号就是预测出的数字。
成功率95%呢,可高了。
好吧,这周干掉了,还有一个overdue的第五周,很快第六周又要overdue了,路漫漫兮,其修远!
Reference
[1] Programming Exercise 3: Multi-class Classification and Neural Networks, Andrew Ng, Stanford University















 5222
5222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









