







零. 引言
什么是Ollama:
Ollama是一个开源的大型语言模型服务工具,它帮助用户快速在本地运行大模型,通过简单的安装指令,可以让用户执行一条命令就在本地运行开源大型语言模型,例如 Llama2。这个框架简化了在Docker容器内部署和管理LLM的过程,使得用户能够快速地在本地运行大型语言模型。
Ollama 将模型权重、配置和数据捆绑到一个包中,定义成 Modelfile。它优化了设置和配置细节,包括 GPU 使用情况。
Ollama的优势:
①易于使用:Ollama提供了一个简单的API,使得即使是没有经验的用户也可以轻松使用。此外,它还提供了类似ChatGPT的聊天界面,用户无需开发即可直接与模型进行聊天交互。
②轻量级:Ollama的代码简洁明了,运行时占用资源少。这使得它能够在本地高效地运行,不需要大量的计算资源。
③可扩展:Ollama支持多种模型架构,并可以扩展以支持新的模型。它还支持热加载模型文件,无需重新启动即可切换不同的模型,这使得它非常灵活多变。
④预构建模型库:Ollama提供了一个预构建模型库,可以用于各种任务,如文本生成、翻译、问答等。这使得在本地运行大型语言模型变得更加容易和方便。
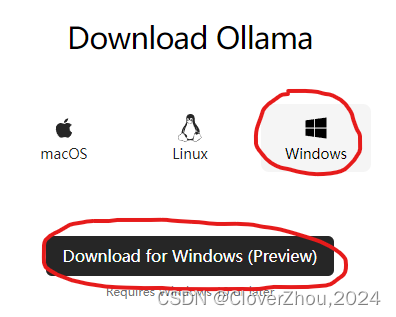
一. 下载 Ollama 安装文件
访问 https://ollama.com/download,选择 Windows,单击 “Download for Windows (Preview)” 进行下载。
二. 安装 Ollama
双击下载的 “OllamaSetup.exe”,进行安装。
三. 环境变量
Ollama 下载的模型默认保存在 C 盘。
强烈建议更改默认路径,可以通过新建环境变量 OLLAMA_MODELS 进行修改。
OLLAMA_MODELS
E:\OllamaCache
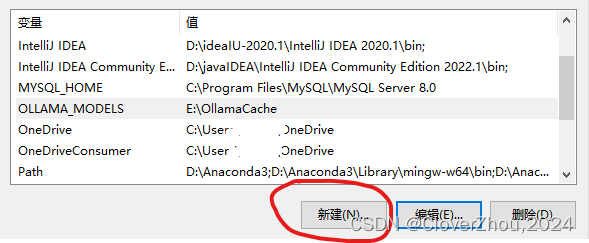
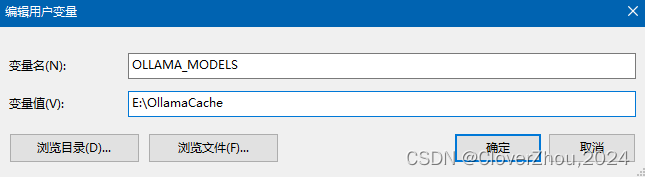
设置成功后重启电脑生效修改
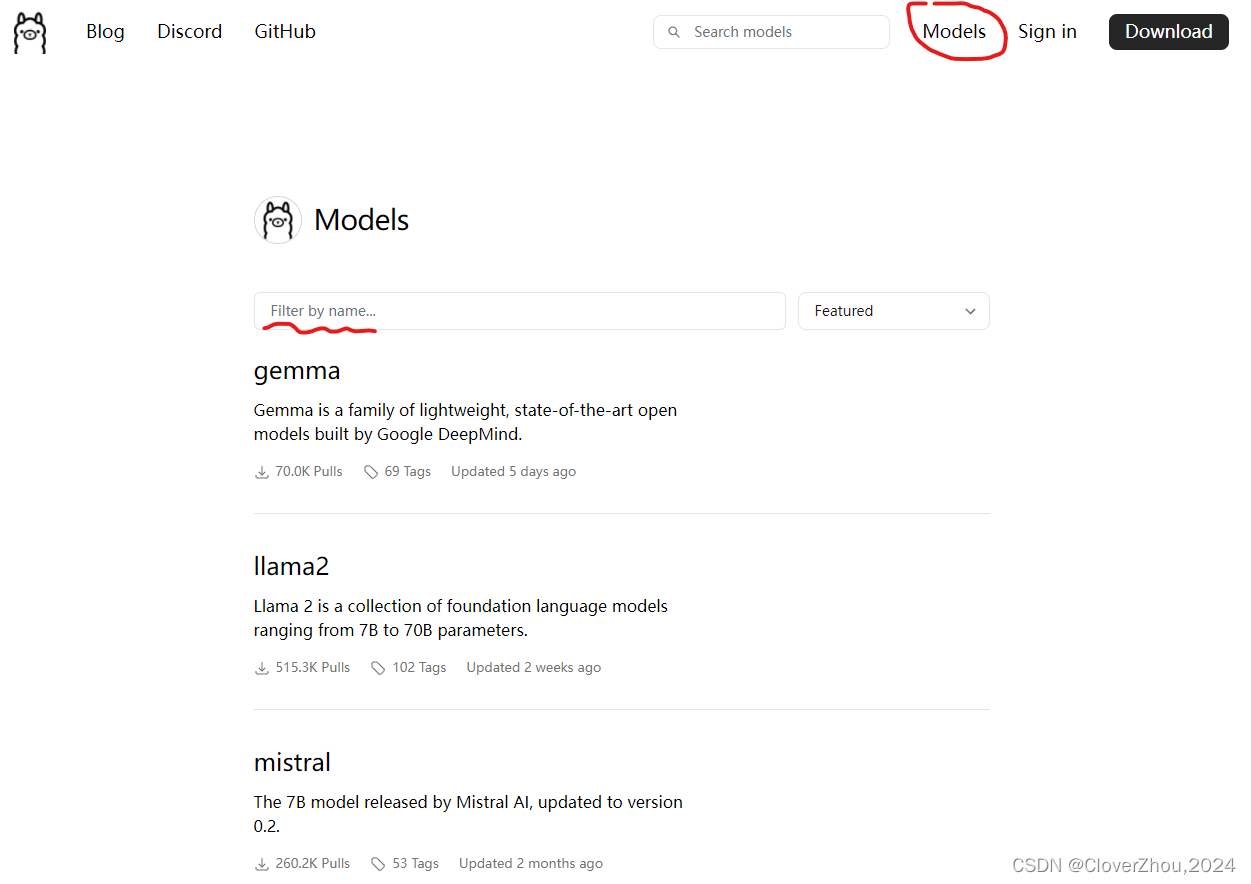
四. 使用 Ollama
访问 https://ollama.com/library,搜索需要使用的模型,主流的模型。
记得先启动Ollma,确保Ollma在任务栏

再下面以 qwen-7b 为例,选择运行 7b 的模型,

拷贝上面红框的命令并在cmd或者PowerShell运行(推荐使用cmd),
ollama run qwen:7b
等待模型下载与加载,目前前95%下载速度快,99%到100%速度较慢。
当出现 Send a nessage 即可开始模型的使用

qwen-7b效果图:
ollama run qwen:7b
orion14b-q4效果图:
ollama run orionstar/orion14b-q4
llama2-chinese效果图:
ollama run llama2-chinese
网络上搜集的问题与回答:

五. 再次使用
确保Ollama正常运行后,
在cmd输入运行代码即可免下载安装直接使用(已在第4步模型安装成功)
如:
ollama run llama2-chinese六. 结语
本人使用的是8GB-2070super,16GB内存,i7-10700K。
在运行qwen-7b和llama2-chinese相当流畅,直接反馈出回复。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









