






本代码使用的是欧几里得公式:
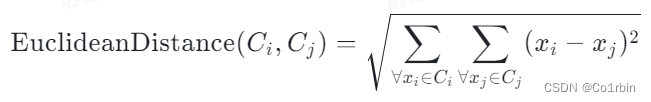
其中,C代表着簇,x代表着簇中的点。
代码如下:
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0)
#设置了随机数种子,让随机数生成变得可重复,即在设置过后,每次运行代码得到的随机数都是一样的。
cluster1 = np.random.randn(30, 2) + np.array([0, 7])
cluster2 = np.random.randn(30, 2) + np.array([8, 0])
cluster3 = np.random.randn(30, 2) + np.array([8, 8])
#np.array([x1, x2])相当于生成一个数组[x1,x2]用于在前面的随机二元数组生成的情况下每个元素加上x1、x2
data = np.vstack([cluster1, cluster2, cluster3])
#np.vstack用于沿着垂直方向(行方向)堆叠数组,得到一个总的数据集
# 1. 初始化每个数据点为一个独立的簇
def initialize_clusters(data):
return [[point] for point in data]
#这里创建的是一个包含每个数据点的列表,创建这样的结构是为了确保每个数据点在后续处理当中仍然保持一致的数据结构。
# 2. 计算簇中心之间的距离,并找到最近的两个簇
def compute_distances(clusters):
distances = np.zeros((len(clusters), len(clusters)))
for i in range(len(clusters)):
for j in range(len(clusters)):
if i != j:
# 使用欧式距离计算两个簇的距离
distances[i][j] = np.sqrt(sum((np.mean(clusters[i], axis=0) - np.mean(clusters[j], axis=0))**2))
#这里的欧氏距离公式是错的
print(distances) #这个是为了我自己验算计算的距离是否按照欧氏距离公式运算正确
return distances
def find_closest_clusters(distances):
min_distance = np.inf #min_distance用于保存最小的距离值,这里将其初始化为无穷大,有利于在后面的迭代阶段找到合适的值
#如果不初始化就会报错:cannot access local variable 'min_distance' where it is not associated with a value
closest_clusters = None #closest_clusters用于保存最近两个簇对应的索引,这里将其初始化为无
for i in range(len(distances)):
for j in range(len(distances)):
if i != j and distances[i][j] < min_distance:
min_distance = distances[i][j]
closest_clusters = (i, j)
return closest_clusters
# 3. 合并最近的两个簇为一个新的簇,并更新簇中心点
def merge_clusters(clusters, closest_clusters):
i, j = closest_clusters
merged_cluster = clusters[i] + clusters[j] #将最近的两个簇更新为一个簇
new_clusters = [cluster for idx, cluster in enumerate(clusters) if idx not in (i, j)]
#这里将没有合并的簇放进新的簇列表里面
new_clusters.append(merged_cluster)
#append()是python中列表对象操作的一个方法,用于在末尾添加新的元素
return new_clusters
def hierarchical_clustering(data):
#这是一个总函数,直接输入数据就能进行聚类计算了,对应第68行
# 初始化每个数据点为一个独立的簇
clusters = initialize_clusters(data)
# 开始迭代合并最相似的簇直到只剩下一个簇
while len(clusters) > 1:
# 计算簇中心之间的距离,并找到最近的两个簇
distances = compute_distances(clusters)
closest_clusters = find_closest_clusters(distances)
# 合并最近的两个簇为一个新的簇,并更新簇中心点
clusters = merge_clusters(clusters, closest_clusters)
return clusters[0]
# 执行层次聚类算法
clusters = hierarchical_clustering(data)
# 打印聚类结果
for idx, cluster in enumerate(clusters):
print(f"Cluster {idx+1}: ", cluster)
#enumerate()是一个python内置函数,用于将一个可迭代对象(例如:列表、元组等)组合为一个索引序列,同时列出索引和对应值
# 绘制聚类结果的图表
a=np.mean(clusters[1], axis=0)
c=clusters[1]
b=len(clusters)
plt.figure(figsize=(8, 6))
colors = ["red", "green", "blue"]
#for idx, cluster in enumerate(clusters):
# plt.scatter(*zip(*cluster), color=colors[1])
for idx, cluster in enumerate(clusters):
if idx <= 29:
plt.scatter(*cluster, color=colors[0])
elif 29 < idx <= 59:
plt.scatter(*cluster, color=colors[1])
elif 59 < idx <= 89:
plt.scatter(*cluster, color=colors[2])
#'*'用于解压序列包,比如clusters是一个二维数组,代表这在一个包内(数组)有多个点(小数组),解压之后相当于把所有的点提取出来。
plt.xlabel("X")
plt.ylabel("Y")
plt.title("Hierarchical Clustering")
plt.show()最后分成了三类:
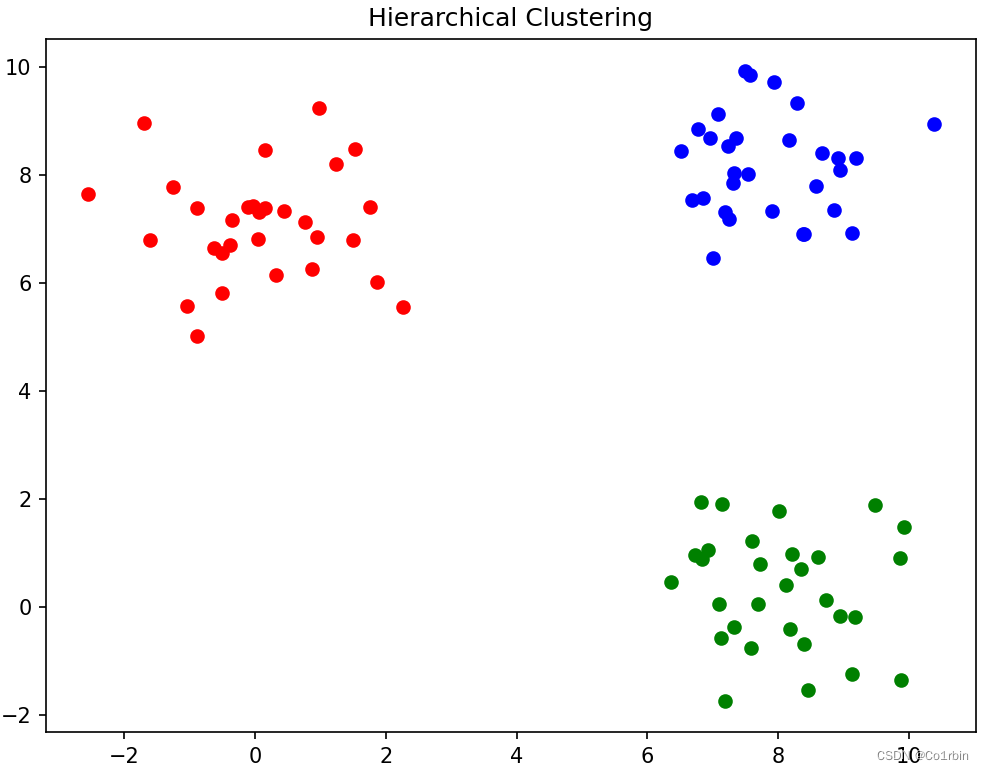
源代码来自 gzh:Johngo学长,本人将修改了一些代码,并解读了一些小白较为难懂的代码,用于学习的过程中对层次聚类的理解。















 748
748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









