






三、DeepSpeed
有了对分布式训练技术的基本情况的了解,我们现在可以开始看看DeepSpeed。
DeepSpeed是微软创建的一个开源深度学习优化工具库,涵盖了模型训练、推理和模型压缩领域。这里,我将只关注与训练相关的优化,并将推理和压缩的主题留给未来的探索。
如前所述,我们可以通过在多个设备上复制整个模型(数据并行)和/或分割模型并将其不同部分存储在不同设备上(模型并行/流水线并行)来进行分布式训练。通常,数据并行在计算效率上比模型并行更高;然而,在模型太大而无法适应单个设备的可用内存的情况下,模型并行是必要的。
DeepSpeed提供的培训优化的核心是Zero Redundancy Optimizer(ZeRO),这是一套减少分布式模型训练所需内存的技术。
四、ZeRO
数据并行在设备之间引入了显著的内存冗余。例如,考虑在8个GPU上训练一个10亿参数模型。存储模型参数本身所需的内存(假设是32位浮点数)约为3.7GB。当使用数据并行时,每个设备必须存储整个模型的副本,这意味着在所有设备上总共使用了约29.8GB的内存。换句话说,26.1GB的设备内存被冗余的模型参数占据。激活和优化器内存也在设备之间类似地冗余。
ZeRO-DP通过以下方式解决这种冗余:
- 分割优化器状态
- 分割梯度
- 分割模型参数
当使用deepspeed库时,我们通过指定ZeRO Stage 来选择应用哪些内存优化。可用的 Stage 包括:

在接下来的部分中,我们将详细探讨每个 Stage 。所有示例脚本已在装有8个16GB NVIDIA V100 GPU的单台机器上进行了测试。
Stage 0 - 入门
DeepSpeed库像任何其他Python包一样安装:
当使用DeepSpeed执行数据并行训练时,我们不需要像使用PyTorch的DistributedDataParallel那样设置进程组或显式地启动多个进程。相反,我们通过调用deepspeed.initialize将模型包装在DeepSpeedEngine中,它在内部处理所有的分布式训练逻辑。
对于这些示例,我们将使用HuggingFace的预训练的、560M参数变体的BLOOM模型[9]。
# deepspeed_stage_0.py
#
# DeepSpeed自动设置LOCAL_RANK环境变量
# 为当前设备的索引。
rank = int(os.getenv("LOCAL_RANK", "0"))
model = BloomForCausalLM
.from_pretrained("bigscience/bloom-560m")
deepspeed_config = {
"train_micro_batch_size_per_gpu": 1
}
model_engine, _, _, _ = deepspeed.initialize(
model=model,
model_parameters=model.parameters(),
config=deepspeed_config
)
print(f"Device {rank} - ZeRO Stage: {model_engine.zero_optimization_stage()}")
要启动分布式训练作业,我们使用deepspeed命令行实用程序,它与deepspeed Python包一起安装:
deepspeed deepspeed_stage_0.py
Device 1 - ZeRO Stage: 0
Device 4 - ZeRO Stage: 0
Device 2 - ZeRO Stage: 0
Device 3 - ZeRO Stage: 0
Device 6 - ZeRO Stage: 0
Device 7 - ZeRO Stage: 0
Device 0 - ZeRO Stage: 0
Device 5 - ZeRO Stage: 0
在这里我们看到模型复制在所有四个设备上。要允许DeepSpeed创建和管理训练期间使用的优化器,我们向deepspeed_config对象添加适当的配置选项:
deepspeed_config = {
"train_micro_batch_size_per_gpu": 1,
"optimizer": {
"type": "Adam",
"params": {
"lr": 5e-5
}
},
}
model_engine, optimizer, _, _ = deepspeed.initialize(
model=model,
model_parameters=model.parameters(),
config=deepspeed_config
)
# 打印优化器状态信息
optimizer_state = optimizer.param_groups[0]
print(f"Device {rank} - Optimizer: lr={optimizer_state['lr']}; "
f"betas={optimizer_state['betas']}; eps={optimizer_state['eps']}; "
f"parameter count={sum([torch.numel(p) for p in optimizer_state['params']]):,}")
Device 1 - Optimizer: lr=5e-05; betas=(0.9, 0.999); eps=1e-08; parameter count=559,214,592
Device 4 - Optimizer: lr=5e-05; betas=(0.9, 0.999); eps=1e-08; parameter count=559,214,592
Device 2 - Optimizer: lr=5e-05; betas=(0.9, 0.999); eps=1e-08; parameter count=559,214,592
Device 3 - Optimizer: lr=5e-05; betas=(0.9, 0.999); eps=1e-08; parameter count=559,214,592
Device 6 - Optimizer: lr=5e-05; betas=(0.9, 0.999); eps=1e-08; parameter count=559,214,592
Device 7 - Optimizer: lr=5e-05; betas=(0.9, 0.999); eps=1e-08; parameter count=559,214,592
Device 0 - Optimizer: lr=5e-05; betas=(0.9, 0.999); eps=1e-08; parameter count=559,214,592
Device 5 - Optimizer: lr=5e-05; betas=(0.9, 0.999); eps=1e-08; parameter count=559,214,592
训练DeepSpeedEngine与使用数据并行训练PyTorch模型非常相似。唯一的区别是backward()和step()方法直接在DeepSpeedEngine对象上调用,而不是在损失或优化器上:
# DeepSpeed自动设置WORLD_SIZE环境变量
# 为参与训练作业的设备数量。
world_size = int(os.getenv("WORLD_SIZE", "1"))
tokenizer = AutoTokenizer.from_pretrained("bigscience/bloom-560m")
collator = DataCollatorForLanguageModeling(tokenizer, mlm=False)
# 辅助函数加载wikitext数据集
# 实现可以在这里找到:
# https://github.com/gnovack/distributed-training-and-deepspeed/blob/main/util.py
train_dataset = load_wikitext(tokenizer, collator).select(range(64))
train_dataloader = DataLoader(
train_dataset,
batch_size=1,
shuffle=False,
sampler=DistributedSampler(train_dataset, num_replicas=world_size)
)
for batch in train_dataloader:
device = torch.device("cuda", rank)
input_ids = batch['input_ids'].to(device)
labels = batch['labels'].to(device)
outputs = model_engine(input_ids, labels=labels)
model_engine.backward(outputs.loss)
model_engine.step()
Stage 1 - 优化器状态分割
ZeRO Stage-1将优化器状态(例如,当使用Adam时,一阶和二阶动量)在所有设备上进行分割,使得每个设备只包含这部分状态的一部分。
下图展示了使用传统数据并行(顶部)和ZeRO Stage-1(底部)训练BLOOM模型时每个设备的内存分配情况:
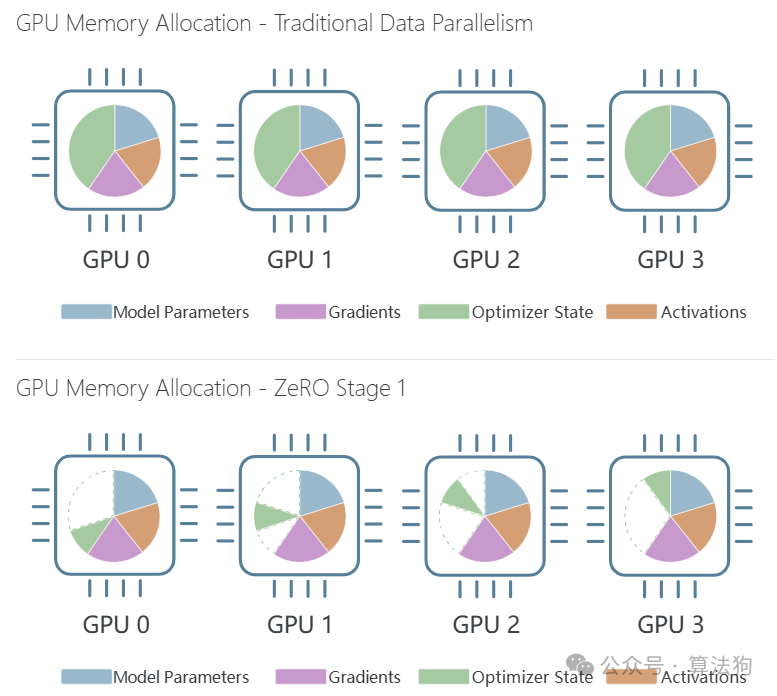
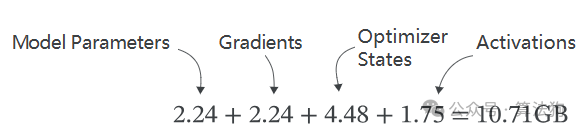
基于之前讨论的Transformer模型内存公式,我们可以估计存储一个560M参数模型的模型参数所需的内存约为2.24GB。当以32位模式使用Adam时,优化器状态将占用每个模型参数8字节的内存,因此优化器将需要4.48GB的内存。
假设我们以批量大小1和输入序列长度512来训练模型,我们可以使用上述公式估计激活所需的内存为1.75GB。
因此,使用传统数据并行训练BLOOM 560M模型所需的总内存大致为:
deepspeed库包括几个实用工具函数,我们可以使用它们来分析训练期间的内存使用情况。例如,要测量当前和峰值内存使用情况,我们在训练循环内调用memory_status()函数:
from deepspeed.runtime.utils import memory_status
for batch in train_dataloader:
input_ids = batch['input_ids'].to(device)
labels = batch['labels'].to(device)
outputs = model_engine(input_ids, labels=labels)
model_engine.backward(outputs.loss)
model_engine.step()
if rank == 0:
memory_status("Memory stats after training step")
如果我们现在使用deepspeed CLI执行训练脚本,我们将在每个步骤后看到以下行打印出来:
RANK=0 MEMSTATS Memory stats after training step device=cuda:0 current alloc=6.8847GB (delta=0.0000GB max=10.8823GB) current cache=13.4453GB (delta=0.0000GB max=13.4453GB)
如所示,GPU的峰值内存使用量为10.88GB,非常接近我们估计的10.71GB。接下来,让我们看看使用ZeRO Stage-1可以节省多少内存。要启用ZeRO Stage-1,我们更新deepspeed_config对象以包含zero_optimization配置选项:
deepspeed_config = {
"train_micro_batch_size_per_gpu": 1,
"optimizer": {
"type": "Adam",
"params": {
"lr": 5e-5
}
},
"zero_optimization": {
"stage": 1,
}
}
model_engine, optimizer, _, _ = deepspeed.initialize(
model=model,
model_parameters=model.parameters(),
config=deepspeed_config
)
现在执行训练脚本时,我们会注意到一些差异。首先,在每个设备上打印优化器参数数量时,显示的参数数量现在是69,901,824,或者是模型中总参数数量的18分之1:
Device 0 - Optimizer: lr=5e-05; betas=(0.9, 0.999); eps=1e-08; parameter count=69,901,824
Device 6 - Optimizer: lr=5e-05; betas=(0.9, 0.999); eps=1e-08; parameter count=69,901,824
Device 7 - Optimizer: lr=5e-05; betas=(0.9, 0.999); eps=1e-08; parameter count=69,901,824
Device 4 - Optimizer: lr=5e-05; betas=(0.9, 0.999); eps=1e-08; parameter count=69,901,824
Device 5 - Optimizer: lr=5e-05; betas=(0.9, 0.999); eps=1e-08; parameter count=69,901,824
Device 3 - Optimizer: lr=5e-05; betas=(0.9, 0.999); eps=1e-08; parameter count=69,901,824
Device 2 - Optimizer: lr=5e-05; betas=(0.9, 0.999); eps=1e-08; parameter count=69,901,824
Device 1 - Optimizer: lr=5e-05; betas=(0.9, 0.999); eps=1e-08; parameter count=69,901,824
其次,当打印每个训练步骤后的内存使用情况时,GPU的峰值内存使用量现在是7.48GB,比使用传统数据并行时测量的10.88GB少了3.4GB:
RANK=0 MEMSTATS Memory stats after training step: device=cuda:0 current alloc=3.4843GB (delta=0.0000GB max=7.4816GB) current cache=12.7695GB (delta=0.0000GB max=12.7695GB)
那么这额外的3.4GB来自哪里呢?回想一下,优化器状态占用了大约4.48GB。以前,当使用传统数据并行时,每个设备都持有所有4.48GB的优化器状态。现在,有了ZeRO Stage-1,每个设备只持有优化器状态的18分之1,即0.56GB。
理论上,这意味着使用ZeRO Stage-1时的峰值GPU内存应该是:
2.24 + 2.24 + 0.56 + 1.75 = 6.79GB
我们测量的7.48GB而不是6.79GB可能归因于用于通信更新模型权重的中间缓冲区的使用,但需要进一步调查以确认这一点。
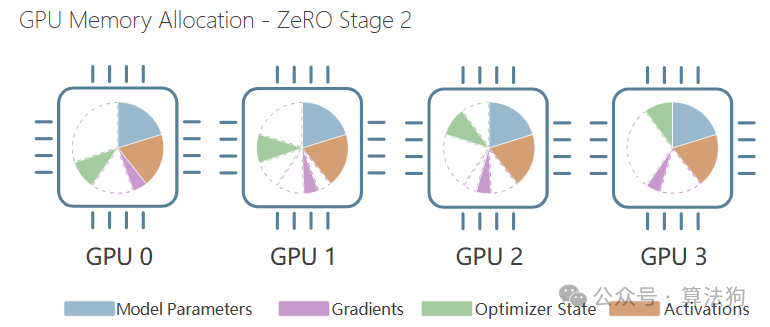
Stage 2 - 梯度分割
ZeRO Stage-2通过在设备间分割优化器状态和梯度,更进一步。下图展示了使用ZeRO Stage-2训练时每个设备的内存分配情况:
Stage-2同样可以通过在deepseed_config中设置stage选项来启用:
deepspeed_config = {
"train_micro_batch_size_per_gpu": 1,
"optimizer": {
"type": "Adam",
"params": {
"lr": 5e-5
}
},
"zero_optimization": {
"stage": 2
}
}
如果我们启用ZeRO Stage-2并执行训练脚本,我们将发现GPU的峰值内存使用量略有增加,达到8.22GB,相比之下,使用 Stage-1训练时为7.48GB:
RANK=0 MEMSTATS Memory stats after training step: device=cuda:0 current alloc=3.4843GB (delta=0.0000GB max=8.2187GB) current cache=12.7715GB (delta=0.0000GB max=12.7715GB)
为了理解GPU峰值内存意外增加的原因,我们需要了解一下ZeRO Stage-2的实现。在后向传递过程中,梯度被平均化并通过一系列Reduce操作放置在一个设备上。
虽然我们可以在计算每个梯度后执行Reduce操作,但通过分块减少梯度可以实现更好的性能。
这些块的大小由deepspeed_config中的reduce_bucket_size选项控制,默认值为5×10^8个元素,或者当每个元素是一个32位浮点数时为2GB。虽然这个默认值适用于更大的模型,但对于我们的560M模型来说太大了,它的梯度总共只占用了大约2.24GB。
如果我们将reduce_bucket_size减少到5×10^6个元素,我们可以将峰值内存使用量降低到6.37GB,与 Stage-1相比额外减少了1.11GB:
RANK=0 MEMSTATS Memory stats after training step: device=cuda:0 current alloc=3.4843GB (delta=0.0000GB max=6.3750GB) current cache=10.9277GB (delta=0.0000GB max=10.9277GB)
值得考虑的是6.37GB的峰值内存是否符合我们的预期。鉴于每个设备持有优化器状态的18分之1和梯度的18分之1,我们应该预期峰值内存在:
2.24 + 2.24/8 + 4.48/8 + 1.75 = 4.83GB
这个理论估计假设后向传递中每个操作产生的梯度小于桶大小。 这篇文章探讨了在多个GPU上分布式训练神经网络的技术,并检验了微软的DeepSpeed库提供的多种分布式训练优化。
阶段3 - 参数分割
ZeRO第三阶段在第二阶段的基础上,进一步分割模型参数以及优化器状态和梯度。当我们使用ZeRO第三阶段训练BLOOM 560M模型时,我们会注意到每个训练步骤后分配的内存从第二阶段的3.48GB减少到1.94GB。然而,GPU的峰值增加到7.48GB。
RANK=0 MEMSTATS Memory stats after training step: device=cuda:0 current alloc=1.9410GB (delta=0.0000GB max=7.4082GB) current cache=10.7129GB (delta=0.0000GB max=10.7129GB)
目前,GPU峰值内存使用量增加的原因尚不清楚,但我在DeepSpeed GitHub仓库中有一个开放的问题,以更好地理解这种行为:DeepSpeed/issues/3734
通信开销
虽然ZeRO可以减少训练所需的总内存量,但它确实引入了额外的通信开销,因为优化器状态、梯度和模型参数必须在设备之间频繁交换。
DeepSpeed允许我们通过其通信日志设置来测量通信操作所花费的时间。通信日志通过在deepspeed_config中添加comms_logger部分来启用:
deepspeed_config = {
"train_micro_batch_size_per_gpu": 1,
"optimizer": {
"type": "Adam",
"params": {
"lr": 5e-5
}
},
"zero_optimization": {
"stage": 0
},
"comms_logger": {
"enabled": True,
"verbose": False,
"prof_all": True,
"debug": False
}
}
现在,执行训练脚本时,每个通信操作(AllReduce、AllGather、Reduce Scatter等)将被捕获和测量。要查看这些测量结果,我们调用deepspeed.comm.log_summary()函数:
## 训练循环后
import deepspeed.comm as dist
dist.log_summary()
Comm. Op Message Size Count Total Latency(ms) Avg Latency(ms) tput_avg (Gbps) busbw_avg (Gbps)
broadcast
4.0 KB 221 20.58 0.09 0.36 0.36
8.0 KB 1 0.17 0.17 0.38 0.38
16.0 KB 24 2.55 0.10 1.25 1.25
113.27 KB 1 0.09 0.09 10.70 10.70
2.0 MB 1 0.44 0.44 38.01 38.01
4.0 MB 97 71.00 0.72 46.41 46.41
16.0 MB 48 155.34 3.23 41.67 41.67
113.27 MB 1 178.26 178.26 5.33 5.33
all_reduce
1.24 GB 50 22385.67 445.17 48.11 36.08
log_summary_barrier
0B 1 69.95 69.95 0.00 0.00
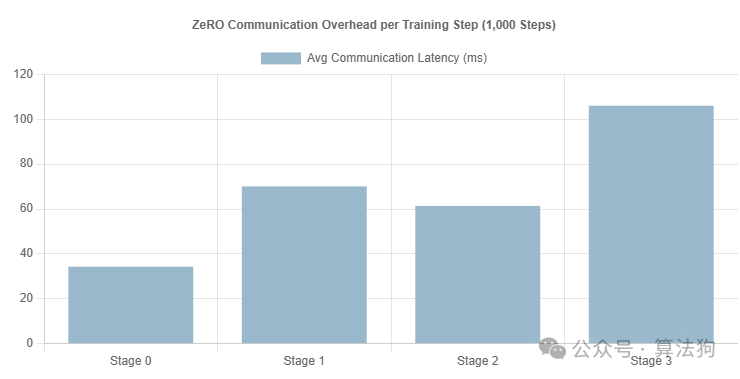
利用这些日志,我测量了ZeRO每个阶段引入的通信开销。结果如下所示:
多节点训练
到目前为止,我们所看到的所有示例都在单个节点上展示了多个GPU的分布式训练。DeepSpeed也可以应用于多节点训练。要执行多节点训练DeepSpeed,我们可以使用与之前相同的训练脚本,但需要一些额外的设置,以允许多个节点相互通信。本节概述了在多个AWS EC2实例上执行多节点训练的步骤。
假设我们有三个能够相互通信的所有端口的EC2实例。使用AWS CDK创建这些实例的示例包含在GitHub仓库中:distributed-training-and-deepspeed/aws/multi_node_training_stack.py。
为简化此示例,我将使用worker-1、worker-2和worker-3代替三个GPU实例的实际IP地址,并使用localhost来指代我的本地机器。如果你想使用工作器名称进行操作,你可以将它们添加到你的~/.ssh/config文件中,如下所示,将HostNames替换为你的实例的实际IP地址,将IdentityFile替换为你的AWS密钥对的路径:
Host worker-1
HostName ec2-34-222-121-132.us-west-2.compute.amazonaws.com
IdentityFile /home/me/keypair.pem
User ubuntu
Host worker-2
HostName ec2-32-27-113-7.us-west-2.compute.amazonaws.com
IdentityFile /home/me/keypair.pem
User ubuntu
Host worker-3
HostName ec2-52-88-92-190.us-west-2.compute.amazonaws.com
IdentityFile /home/me/keypair.pem
User ubuntu
要运行多节点训练作业,每个节点都需要能够通过无密码SSH连接到每个其他节点。为此,我们将创建一个新的SSH密钥对并将其分发到每个节点:
# 在localhost上
# 创建一个新的SSH密钥对
mkdir -p multi-node-training-keys
ssh-keygen -t rsa -N "" -f ./multi-node-training-keys/id_rsa
# 将SSH密钥复制到worker-1
scp ./multi-node-training-keys/id_rsa.pub worker-1:/home/ubuntu/.ssh/id_rsa.pub
scp ./multi-node-training-keys/id_rsa worker-1:/home/ubuntu/.ssh/id_rsa
# 在工作器节点上将SSH密钥添加到authorized_keys
ssh worker-1 'cat /home/ubuntu/.ssh/id_rsa.pub >> /home/ubuntu/.ssh/authorized_keys'
# 为worker-2和worker-3重复上述三个命令
接下来,我们需要在每个工作器上安装DeepSpeed及其依赖项。这个页面的GitHub仓库包括一个requirements.txt文件和一个worker-prereqs.sh脚本,可以用来安装所有先决条件。在每个节点上,我们将克隆GitHub仓库并安装先决条件:
# 在localhost上
# 在worker-1上安装依赖项
ssh worker-1 'rm -rf distributed-training-and-deepspeed && git clone https://github.com/gnovack/distributed-training-and-deepspeed.git && pip install -r distributed-training-and-deepspeed/requirements.txt && distributed-training-and-deepspeed/scripts/worker-prereqs.sh'
# 为worker-2和worker-3重复上述命令
最后,虽然不是必需的,但在每个工作器上配置SSH主机名别名是很好的。我们可以通过在每个工作器上写入/home/ubuntu/.ssh/config文件来实现:
# 在localhost上;假设你已经在你的~/.ssh/config文件中添加了SSH主机名别名
worker_ip_1=$(ssh -G worker-1 | awk '$1 == "hostname" { print $2 }')
worker_ip_2=$(ssh -G worker-2 | awk '$1 == "hostname" { print $2 }')
worker_ip_3=$(ssh -G worker-3 | awk '$1 == "hostname" { print $2 }')
ssh worker-1 'cat > /home/ubuntu/.ssh/config' << EOF
Host worker-1
HostName $worker_ip_1
StrictHostKeyChecking no
Host worker-2
HostName $worker_ip_2
StrictHostKeyChecking no
Host worker-3
HostName $worker_ip_3
StrictHostKeyChecking no
EOF
# 为worker-2和worker-3重复上述命令
通过设置StrictHostKeyChecking no,我们绕过了手动接受每个工作器的SSH主机密钥的需要。这简化了这个例子,但不建议在生产环境中这样做。
一个执行所有这些命令的完整脚本适用于所有三个工作器节点,在distributed-training-and-deepspeed/scripts/generate-keys.sh中可用。
现在每个节点都可以通过无密码SSH连接到每个其他节点,下一步是创建一个hostfile,列出每个节点的IP地址,并指定每个节点上可用的GPU数量。假设我们的~/.ssh/config中有每个工作器节点的别名,我们可以使用这些别名而不是IP地址在我们的hostfile中:
worker-1 slots=1
worker-2 slots=1
worker-3 slots=1
随着hostfile的创建,我们准备 运行一个多节点训练作业。我们可以从任何一个工作器节点启动作业。对于这个例子,我们将从worker-1开始作业,通过将hostfile从localhost复制到worker-1,然后使用--hostfile参数运行训练脚本:
# 在localhost上
# 将hostfile复制到worker-1
scp hostfile worker-1:/home/ubuntu/distributed-training-and-deepspeed/hostfile
# 从SSH配置文件中获取worker-1的IP地址
MASTER_ADDR=$(ssh -G worker-1 | awk '$1 == "hostname" { print $2 }')
# ssh到第一个工作器节点并启动训练
ssh worker-1 'cd distributed-training-and-deepspeed && PATH="/home/ubuntu/.local/bin:$PATH" deepspeed --master_addr=$MASTER_ADDR --hostfile=./hostfile zero_dp_training.py --stage=2 --model_name=facebook/opt-125m'
五、总结
这次对分布式训练和DeepSpeed的探索让我学到了很多关于分布式模型训练的细微差别和挑战,以及零冗余优化器如何在多个GPU上训练时减少内存需求。DeepSpeed中还有许多其他优化没有在本文中涵盖,这为我未来的探索留下了几个话题:
-
卸载:DeepSpeed提供了将优化器状态和模型参数卸载到CPU内存和磁盘的能力,这可以进一步减少内存消耗,以训练时间为代价。
-
专家混合(MoE):MoE模型是一类使用稀疏激活层(即在每次前向传递中选择一部分权重使用的层)来增加模型参数总数而不增加计算复杂性的模型。DeepSpeed库包括稀疏激活的PyTorch模型层,可以用来实现MoE模型。
-
渐进式层丢弃(PLD):PLD是一种通过允许在训练过程中的不同点切换特定的Transformer层来加速Transformer模型训练的技术。
六、如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

参考文献
References
[1] Sohoni, Nimit S., et al. “Low-memory neural network training: A technical report.” arXiv preprint arXiv:1904.10631 (2019).
[2] https://huggingface.co/docs/transformers/v4.20.1/en/perf_train_gpu_one#anatomy-of-models-memory
[3] Korthikanti, Vijay Anand, et al. “Reducing activation recomputation in large transformer models.” Proceedings of Machine Learning and Systems 5 (2023).
[4] Li, Shen, et al. “Pytorch distributed: Experiences on accelerating data parallel training.” arXiv preprint arXiv:2006.15704 (2020).
[5] Sergeev, Alexander, and Mike Del Balso. “Horovod: fast and easy distributed deep learning in TensorFlow.” arXiv preprint arXiv:1802.05799 (2018).
[6] Huang, Yanping, et al. “Gpipe: Efficient training of giant neural networks using pipeline parallelism.” Advances in neural information processing systems 32 (2019).
[7] https://huggingface.co/docs/transformers/v4.15.0/parallelism#naive-model-parallel-vertical-and-pipeline-parallel
[8] Rajbhandari, Samyam, et al. “Zero: Memory optimizations toward training trillion parameter models.” SC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2020.
[9] Scao, Teven Le, et al. “Bloom: A 176b-parameter open-access multilingual language model.” arXiv preprint arXiv:2211.05100 (2022).

















 1388
1388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









