









论文笔记 之 Low-Latency Video Semantic Segmentation
1,要解决的问题:
提高视频语义分割的速度,同时降低最大延迟。
所谓最大延迟,是指视频中每一帧的处理时间的最大值。
本文提出模型的结构与DFF[31]很相似,几乎是同一个框架,只是替换了其中某些模块的实现,本文解决的最大延迟问题,也可以看作是对DFF中问题的思考:
DFF通过特征传递,降低了对视频处理的整体计算量,但是对于关键帧,其计算量仍然保持在单帧语义分割的水平,由此造成了一个问题,就是尽管对视频的处理速度很快,但是其中某些帧的处理速度很慢,这在实际应用中往往是不合适的。
关于DFF论文的笔记,请见论文笔记 之 Deep Feature Flow for Video Recognition
要想理解本论文或者本笔记,请务必阅读DFF。
本文相比于DFF的进步(也是本文的创新点):
1,自适应策略选取关键帧。作用:降低计算量(关键帧数量更少),提高精度(关键帧更合理)
2,新的特征传播方法,能应对视频存在的复杂变化( complex variations in videos),如相机运动、场景结构变化等等。作用:降低计算量(作者称其特征传播方法比光流要快),提高精度
3,降低最大延迟。
2,本文提出的方法:
如图Figure2,基本和DFF一致:
注:
1,我在此处用的符号与图中不太一致,但与下文一致。
2,下面叙述省略了fuse(AdaptNet)模块和降低最大延迟的处理流程。
对于新的一帧:
1,首先使用低级特征提取网络Sl,提取低级特征图Ftl
2,将Ftl和上一个关键帧的低级特征图Ftk输入到自适应关键帧选取网络Devs,判定是否将当前帧作为新的关键帧,如是,设置为关键帧转3,反之,转4
3,将Ftl输入Sh,获得Fkh,再通过Ntask输出结果。Ntask文中没有提到,我是根据DFF猜测的
4,将Ftl和Fkl输入卷积核预测网络(kernel weight predictor,即图Figure2中的w),w将输出一系列的卷积核,利用这些卷积核将Fkh卷积,结果作为Fth,输入到Ntask输出结果。
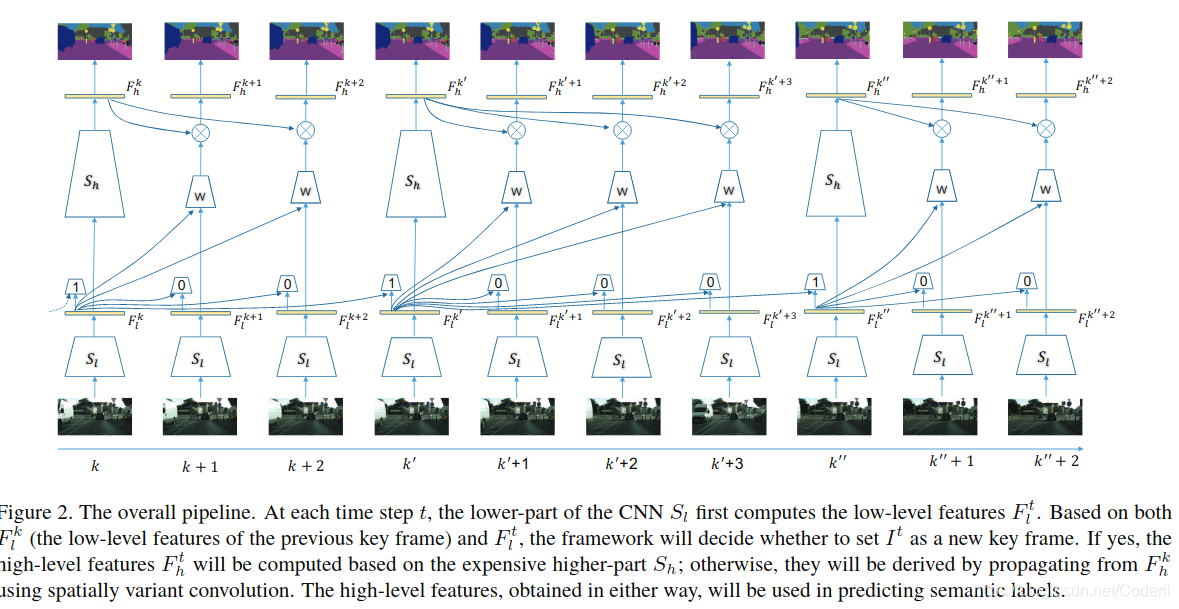
3,网络结构:
使用ResNet-101[12]提取视觉特征,以conv4_3为split point将该模型分成Sl和Sh两部分,见图Figure2。
Sl的输出深度为1024,该部分占总体计算量的1/6。
3.1,自适应关键帧选取网络Devs:
关键帧选取的目标是:尽量降低关键帧的频率,并在同样数量的关键帧前提下达到最好的精度。
直观上看是否应该将当前帧作为关键帧取决于当前帧和的上一个关键帧的语义不同的像素数量多少(作者称之为 deviation),但我们在实际中无法计算 deviation。作者在Cityscapes和 Camvid 数据集上研究发现,当前帧与关键帧之间低级特征的不同与deviation有很强的相关性,于是作者决定使用低级特征预测是否应该将当前帧作为关键帧。
作者设计了一个小规模网络Devs,其将上一个关键帧和当前帧的低级特征(Fkl和Ftl)作为输入,输出deviation,如果deviation超过阈值则将当前帧作为新关键帧。
Devs的结构:
conv1:3x3卷积核,输出深度256
conv2:3x3卷积核,输出深度256
global pooling
全连接网络
3.2,自适应特征传递网络spatially variant convolution
3.2.1,特征传递策略
怎样高效且有效将关键帧的特征传播给当前帧?
已有工作往往采用以下两个方法:
方法1:文献[31]采用的光流传播算法。该方法存在2点不足:
1,光流计算量大
2,点对点的映射(Point-to-point)过于严格。由于是对经过高级特征进行传播,而每个高级特征(即,高级特征图中的一个像素点)蕴含了原图上一块区域而不是一个点上的信息,一个线性组合可能能够提供更大的范围来更准确的表达传播。
方法2:文献[20]采用的translation-invariant convolution。尽管一般来说卷积计算量更小且更灵活,但是在整个特征图上使用固定的卷积核是病态的(problematic)。因为场景的不同部分有着不同的模式(patterns),也就是说可能朝着不同方向运动,于是需要不同的权重来传递特征。
基于以上分析,作者提出使用spatially variant convolution来传递特征。
所谓spatially variant convolution,简单来说就是改进了上面提到的方法2,仍然使用卷积进行特征传递,但是每个位置使用的卷积核均不同。而这些卷积核是由Fkl和Ftl计算出来的。
文中用W(k,t)ij,表示计算Fth的ij位置的元素时用到的卷积核,其尺寸是HKxHK。ij位置各个通道使用的卷积核相同。
由Fkh计算Fth的ij位置c通道的值的方法见公式(1):
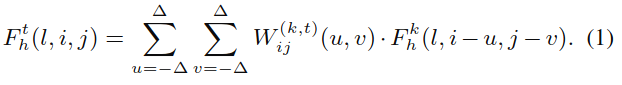
符号定义如前所述。
3.2.1,卷积核预测kernel weight predictor
那么怎么获得这些卷积核呢?
作者设计了一个kernel weight predictor来完成这个任务。这好似一个小型卷积神经网络(relu激活)。它以Fkl和Ftl作为输入,输出深度为HK2,尺寸与Fth一致。对该输出的使用softmax,保证每个卷积核内权重之和为1。由于这些卷积核是从低级特征中计算的,因此能自适应位置和特征内容。
kernel weight predictor的结构:
conv1:3x3卷积核,输出深度256
conv2:3x3卷积核,输出深度256
conv3:1x1卷积核,输出深度81
注:将Fkl和Ftl分别输入到conv1,分别变为256深度的深度图,然后接在一起输入到conv2,此处存疑。
3.2.3,Ftl和Fth融合网络AdaptNet:
为了增强鲁棒性作者还设计了一个AdaptNet网络,用它处理Ftl,然后将处理后的特征图与Fth 结合(fuse)
输入:Ftl
AdaptNet的结构:
conv1:3x3卷积核,输出深度256
conv2:3x3卷积核,输出深度256
conv3:3x3卷积核,输出深度256
将AdaptNet输出与Fth连接起来,输入到一个卷积层(3x3卷积核,输出深度256),该卷积层的输出作为最终的Fth。
3.2.4,自适应特征传递网络流程
见图Figure4
注:图中没有标识AdaptNet过程
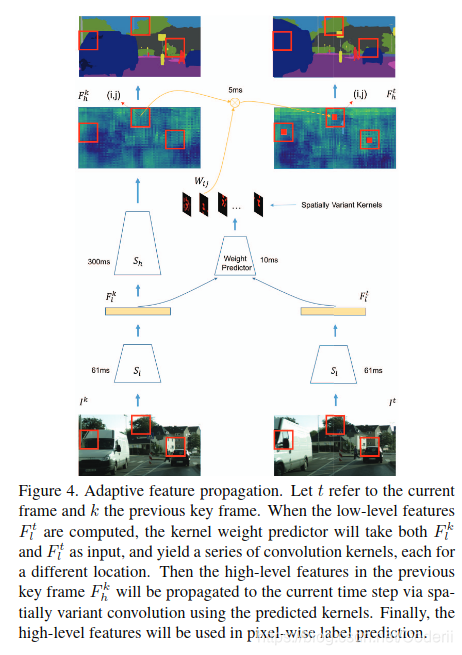
3.3,低延迟调度Low-Latency Scheduling
作者采用了一个很直观很工程的方法解决了这个问题。
延迟来自于key frame的计算,于是当判定当前帧为关键帧后,作者仍然用特征传递的方法计算新关键帧的Fkh,这个过程称为"fast track",同时开辟一个back-ground process线程,使用Sh计算Fkh,这个过程称为"slow track",当slow track计算完成后,用其结果替代fast track的结果。
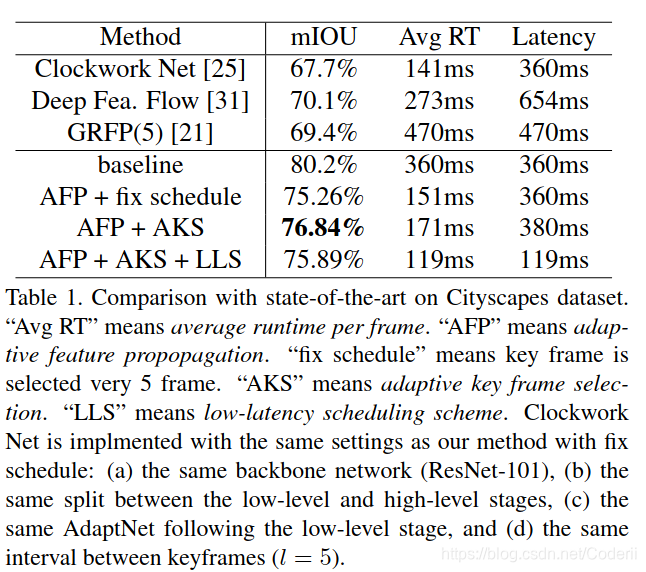
作者称,这将最大延迟从360ms 降低到119ms,代价是精度从76.84%降低到75.89%。
4,实验:
4.1,总体性能比较:
通过表Table1证明了本文方法的有效性:
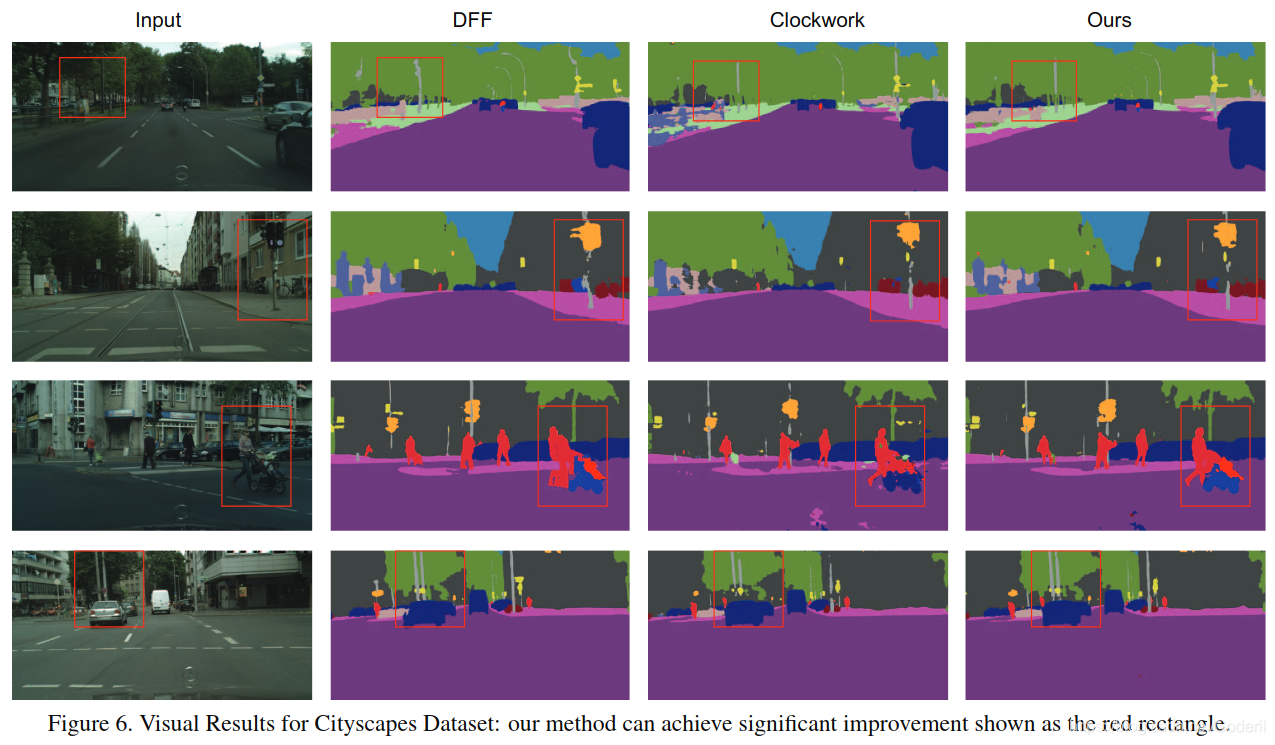
 另外,在该实验过程中,作者还发现本文方法对视频变化比较大的地方有更强的处理能力,见图Figure6:
另外,在该实验过程中,作者还发现本文方法对视频变化比较大的地方有更强的处理能力,见图Figure6:
4.2,本文特征传播策略的有效性验证实验:
本实验中取消了自适应关键帧选取网络,使用每5帧选取一个关键帧的方式,结果见表Table2:
 其中:Unified Propagation 是: globally learned unified propagation,我猜测是将本文各个位置不同的W(k,t)ij变为各个位置相同
其中:Unified Propagation 是: globally learned unified propagation,我猜测是将本文各个位置不同的W(k,t)ij变为各个位置相同
Weight by Image Difference是:将W(k,t)ij的由Fkl和Ftl计算,替换成由关键帧和当前帧原图计算
结果表明了spatially variant convolution(使用自适应权重卷积核)的有效性,因为能利用空间关系
以及,fuse(AdaptNet)的有效性,因为其能够与 weight predictor 互补
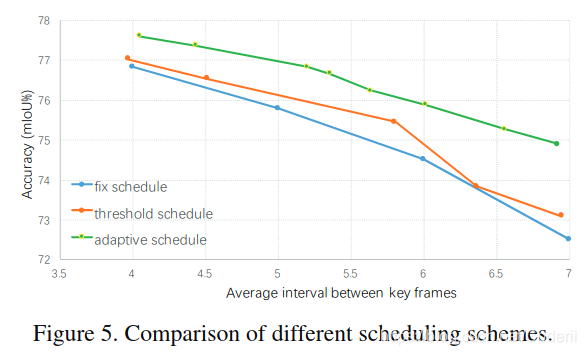
4.3,自适应关键帧选取策略验证:
比较了本文方法,固定间隔选取关键帧策略(fix),按阈值选取策略(threshold), 结果见图Figure5。文中没有详述按阈值选取策略,应该是[25]中提到的策略。我没有看[25],但作者认为本文方法比按阈值选取策略好的原因是:

5,参考文献:
[12]K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learningfor image recognition.CoRR, abs/1512.03385, 2015.
[20] B. Mahasseni, S. Todorovic, and A. Fern. Budget-awaredeep semantic video segmentation. InProceedings of theIEEE Conference on Computer Vision and Pattern Recogni-tion, pages 1029–1038, 2017.
[25] E. Shelhamer, K. Rakelly, J. Hoffman, and T. Darrell.Clockwork convnets for video semantic segmentation. InComputer Vision–ECCV 2016 Workshops, pages 852–868.Springer, 2016.
[31] X. Zhu, Y. Xiong, J. Dai, L. Yuan, and Y. Wei. Deep featureflow for video recognition. InProceedings of the IEEE Con-ference on Computer Vision and Pattern Recognition, pages2349–2358, 2017


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









