







吴恩达-机器学习公开课 学习笔记 Week3-1 Logistic Regression
3-1 Logistic Regression 课程内容
此文为Week3 中Logistic Regression的部分。
3-1-1 Classification and Representation
Classification
在分类问题中是离散的值。
0和1的分类问题:

多类别问题:

eg.尝试用一条直线来拟合数据。假设函数 h(x) = θ T x。将分类器的输出阈值设为0.5,如果假设输出的值大于等于 0.5你就预测 y 值等于1 ,如果小于0.5 预测y等于0。

eg. 当增加一个训练样本后,线性回归直线发生改变,我们可以发现结果并不好。

在线性回归中,我们得到的值可能大于1,或者小于0,但分类问题值要么为1要么为0。
因此,逻辑回归算法作为分类算法,适用于标签y为离散值0或1的问题。

Hypothesis Representation
我们希望想出一个满足某个性质的假设函数,这个性质是它的预测值要在0和1之间。
一种假设函数的形式 其中 h(x) 等于 θ 的转置乘以 x,把假设函数改成 g(θ 的转置乘以 x)。
定义函数g如下: **当z是一个实数时 g(z)=1/(1+e^(-z))。这称为 S 型函数 (sigmoid function) 或逻辑函数。
我们需要做的是用参数θ拟合我们的数据,拿到一个训练集需要给参数 θ 选定一个值,然后用这个假设函数做出预测。

假设函数的输出是对于新输入样本 x 的 y=1的概率的估计值。
这就是说 y=0 的概率 加上 y=1 的概率必须等于1。
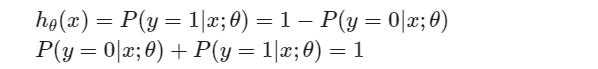
Decision Boundary
假设函数输出y=1的概率 大于或等于0.5,预测y=1。如果预测y=1 的概率小于0.5,那么预测y=0。因此,只要θTx 大于或等于0,预测y=1。θTx小于0,预测y=0。

具体地说,这条直线满足x1+x2=3 它对应一系列的点,它对应 h(x)=0.5的区域。
这条线被称为决策边界(decision boundary),将整个平面分成了两部分。
***决策边界是假设函数的一个属性,它包括参数θT。假设函数的属性决定于其参数,它不是数据集的属性 ***我们将使用训练集来确定参数的取值,但是 一旦我们有确定的参数取值,我们就将完全确定决策边界。
当我们谈论多项式回归或线性回归时,我们谈到可以添加额外的高阶多项式项。同样我们也可以对逻辑回归使用相同的方法。具体地说,假设函数添加了两个额外的特征 x12和x22。

3-1-2 Logistic Regression Model
Cost Function
这个成本函数在线性回归中很好用。但这里,我们感兴趣的是逻辑回归。但是,如果我们使用这个特殊的代价函数,它将是参数的一个非凸函数。

逻辑回归的代价函数:
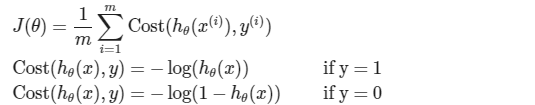


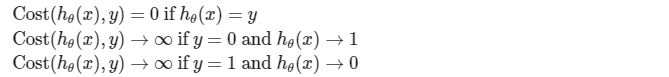
Simplified Cost Function and Gradient Descent
这个新的代价函数的定义是更为简洁的形式 包括了 y=1 和 y=0 这两种情况。

将之前我们得到的代价函数定义替换进式子里。使用最大似然估计法从统计数据中可以得出这个代价函数。这是统计学中的一种思想 即如何有效地为不同模型找到参数值。这个代价函数有一个十分优秀的属性——凸属性。为了拟合参数,尝试找到使 J 函数最小化的参数 θ。
输出的预测函数可以这样理解,即 y 等于1的可能性。

最小化代价函数的方法是梯度下降法。
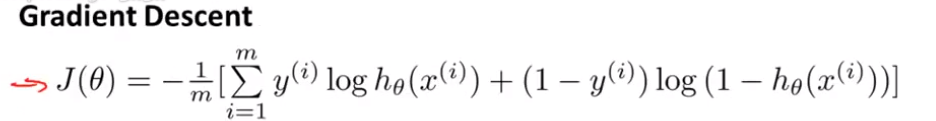
通常,我们梯度下降的模板如下:

将J偏导函数代入:
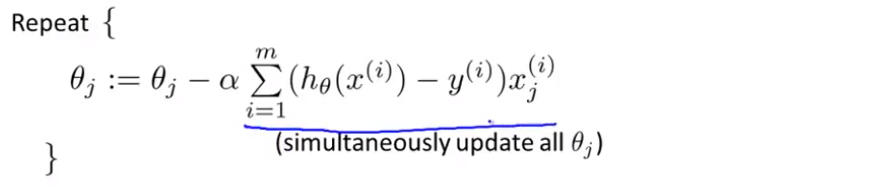
这里虽然逻辑回归和线性回归的形式一样,但假设函数不同。
特征缩放同样适用于逻辑回归,使梯度下降收敛更快。
Advanced Optimization
我们有个代价函数 J 而我们想要使其最小化。我们需要做的是编写代码,当输入参数 θ 时,会计算出两样东西 J(θ) 以及 J等于0到n 时的偏导数项。
因此另一种考虑梯度下降的思路是,我们需要写出代码来计算 J(θ) 这些偏导数,然后把这些插入到梯度下降中 ,就可以为我们最小化这个函数。从技术上讲,你实际并不需要编写代码来计算代价函数 J(θ) ,只需要编写代码来计算导数项。 但是如果你希望还要能够监控这些 J(θ) 的收敛性,那么我们就需要自己编写代码来计算代价函数和偏导数项。

梯度下降并不是我们可以使用的唯一算法,还有其他一些算法更高级更复杂。它们需要有一种方法来计算 J(θ), 以及需要一种方法计算导数项,然后使用比梯度下降更复杂的算法来最小化代价函数。

幸运的是 有 Octave 和 与它密切相关的 MATLAB 语言。我们将会用到它们 Octave 有一个非常理想的库用于实现这些先进的优化算法。所以如果你直接调用它自带的库,你就能得到不错的结果。
你想要代价函数找到这个最小值,要做的就是运行像Octave中的 costFunction这样的一个函数。
它会返回两个值,第一个是 jVal,是我们计算的代价函数。第二个值是梯度值。
fminunc 它表示 Octave 里无约束最小化函数。你现在要给这个算法提供一个梯度,然后设置最大迭代次数。

因此,我们需要做的是写一个 costFunction 函数,为逻辑回归求得代价函数。

由于这些算法的运行速度通常远远超过梯度下降,因此当我有一个很大的机器学习问题时,我会选择这些高级算法,而不是梯度下降。
3-1-3 Multiclass Classification
Multiclass Classification: One-vs-all
一对多(一对余)的分类工作:
使用一个训练集,将其分成三个二元分类问题。创建一个新的"伪"训练集,类型2和类型3定为负类,类型1设定为正类。

现在我们便有了三个分类器,且每个分类器都作为其中一种情况进行训练。
最后,为了做出预测,我们给出输入一个新的 x 值,用这个做预测。我们要做的就是,在我们三个分类器里面输入 x 然后,我们选择一个让 h 最大的 i。

测验 Logistic Regression





课程链接
https://www.coursera.org/learn/machine-learning/home/week/3















 161
161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









