







字,双字,四字,八字对齐不必在内存的自然边界上对齐。自然边界对于字,双字,四字来说是偶数地址,偶数地址可以被对应的4和8整除。也就是数据对齐,数据的内存地址能够被1,2,4,8整除,或数据地址可以被2的幂整除。然而,为了改善程序的性能,数据结构(尤其是栈)无论什么情况下都应该尽可能在自然边界上对齐。原因是,处理器要求用2次内存访问来完成一次非对齐的内存访问,而对齐的内存访问仅需1次内存访问。
跨越了4字节边界的一个字或者是双字操作或跨越了8字节边界的一个四字操作被认为是非对齐的操作,这要求两个单独的内存总线周期来完成访问。这里强调的就是对齐操作,一个字2字节,一个双字4字节,按4字节边界地址对齐访问内存,认为按自然边界对齐的,但是跨越四字节边界却不行。同理,一个4字8字节,按8字节边界地址对齐访问内存地址,认为按自然边界对齐,但是跨越8字节边界地址却不行。
一些操作8字的指令要求内存操作在自然边界上对齐。如果发生了非对齐操作,这些指令会产生一个通用保护异常#GP(general-protection)。一个8字的自然边界对齐地址是可以被16整除的任何偶数地址。而其它的一些在8字上操作的指令允许非对齐访问(即除开产生通用异常保护的指令)。然而,访问内存上非对齐的数据会增加额外的内存总线周期。
下图展示了CPU是如何用一个4字节的内存粒度来访问一个4字节的内存块:从内存到CPU缓存的映射图。
图中,前面是按4字节内存地址对齐,姑且认为从0地址开始,后面是非4字节内地址址对齐,即从1地址开始。按4字节地址对齐访问,一步到位完成。
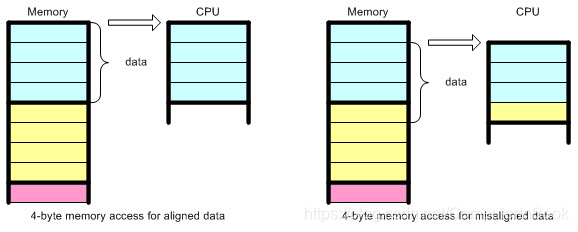
从下面的图可以看出,对于非内存对齐访问的情况,CPU需要做一些额外的工作,首先要载入两个数据块,除出不需要的字节,再将两个合并成一个内存块。这个操作明显的减慢了访问内存的速度,浪费了CPU时钟周期。
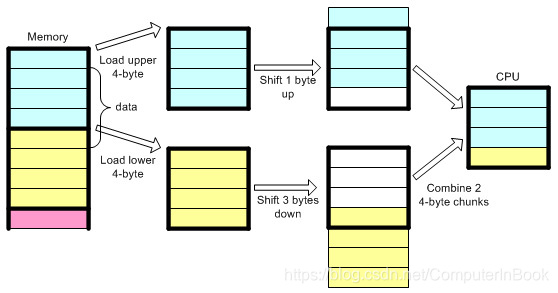
上图中,因为内存地址不是按4字节对齐,从地址1开始,如果是按4字节边界对齐,那么起始地址应该是0,或者4,但是这个从1开始,这样处理器首先要载入两个4字节内存块,然后从第一个块中移除第1个字节,再从第二个块中移除后3个字节,将第一个的后3字节与第二块中的第1个字节合并,从而得到4个字节的内存。这明显浪费了CPU时间,降低了性能。

















 4452
4452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









