







RISC 下使用访存指令读取或写入数据单元时,目标地址必须是所访问之数据单元字节数的整数倍,这个叫做地址对齐。
高级语言中一般不会遇到这种问题,编译器常常会处理好数据类型的对齐。但万一遇到、抑或在汇编里遇到,避不开怎么办?
可以使用 MIPS 的指令集里提供的 lwr/lwl, swr/srl, ldr/ldl, sdr/sdl 指令对。关于他们的原理可以用下图来简单的示意一下(以ldr/ldl 为例,其他类似):
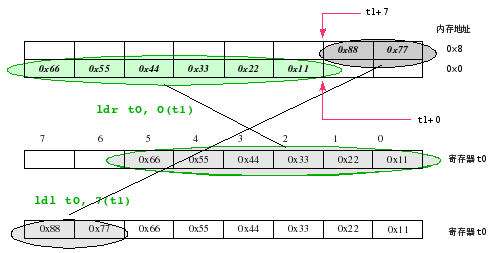
上图解释的是小端模式下的情况,大端模式的情况则相反:首先 ldl t0, 0(t1),然后再 ldr t0, 7(t1)。
可 以看到无论大端模式还是小端模式,非对齐访问的解决都是将原来的一条指令(对齐访问)完成的事分两步完成,即首先取始地址 addr 到下一个对齐地址处的部分数据,置入寄存器右部(小端),(大端置入左部(高位)),然后取从该对齐地址到 addr + len - 1 处的部分数据(len 为数据单元长度,半字为2, 双字为8),置入寄存器左部(小端)。
如小端机器上,始地址为 t1 = 0x1022,则:
ldr t0, 0(t1) 取 0x1022~0x1027 到 t0 的右部
ldl t0, 7(t1) 取 0x1028~0x1029 到 t0 的左部
注 意上述指令的后缀 r(right), l(left) 都是相对寄存器而言,load 操作是把取到的部分数据,置入寄存器的 left 或者 right, store 操作是将寄存器中数据的 left 或者 right 部分,写入目标地址而已。无论大端和小端寄存器的格式都是固定的,即右端为低位,左端为高位。任意第一条 ldr/ldl/lwr/lwl/sdr/sdl/swr/swl 只能访问内存的始地址到下一个对齐地址处。
现在的cpu 中海cache,cache 和内存是成块交换数据的,如果数据没有对齐,也会是cache的命中率降低吧,个人观点。
(发现写博客却是有难度,因为要对一个问题真正的了解透了才可以解释的十分明白,而知识又是相互联系的!)















 1727
1727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









