








目录
一、优化器演进史:从SGD到智能自适应
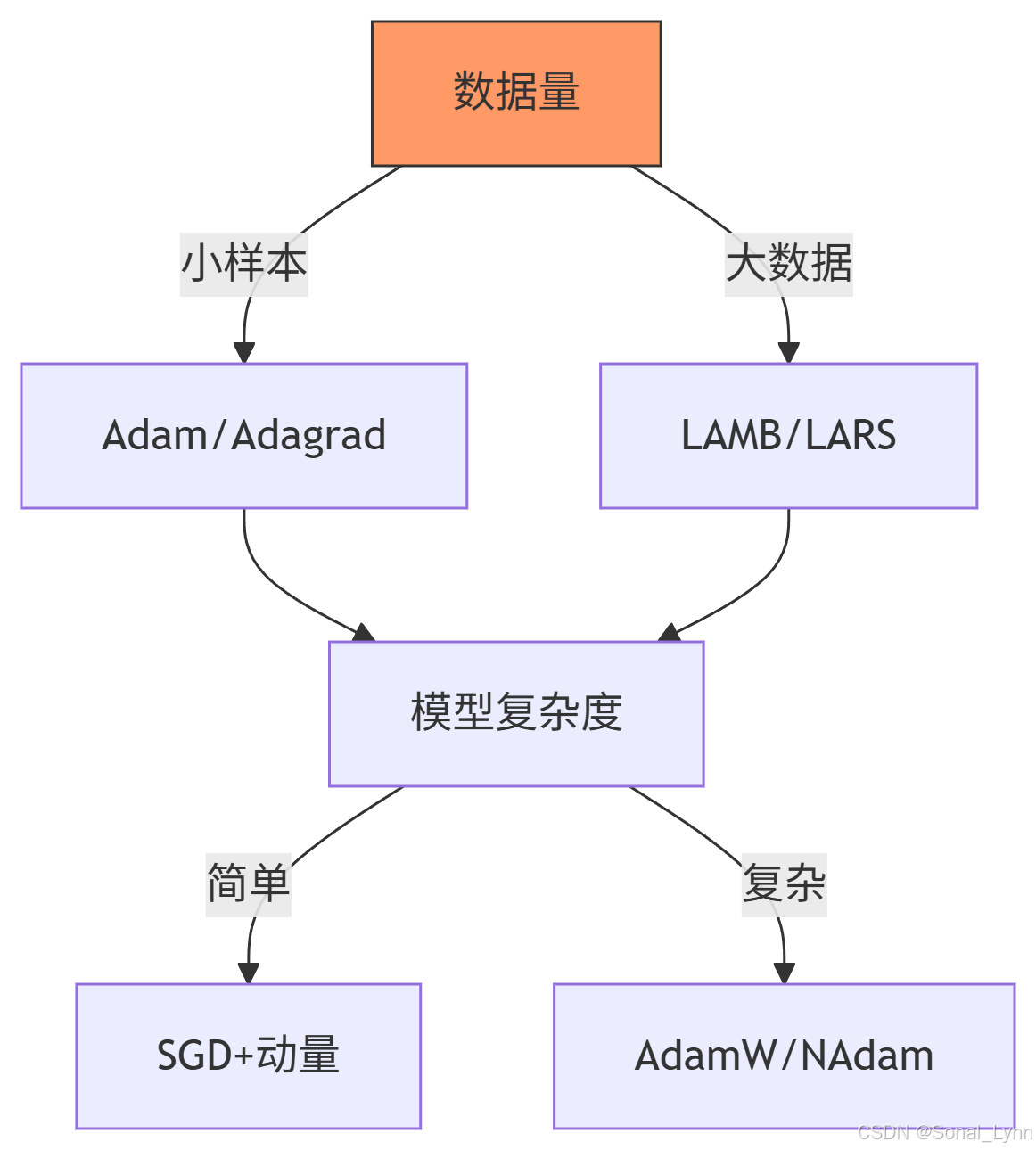
1.1 优化器选择决策树
二、核心优化器原理与代码实现
2.1 动量优化:保龄球下山算法
物理类比:
保龄球从山顶滚落,初始速度慢但动量逐渐累积,最终高速抵达谷底
数学本质:
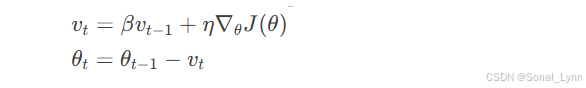
Keras实现:
keras.optimizers.SGD(
learning_rate=0.01,
momentum=0.9,
nesterov=False
)2.2 Nesterov加速梯度:预见性动量
优化关键:
在动量方向的前瞻点计算梯度,提前修正路径
公式升级:
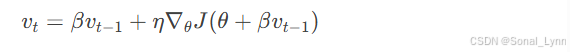
代码对比:
# 启用Nesterov加速
keras.optimizers.SGD(
learning_rate=0.01,
momentum=0.9,
nesterov=True
)2.3 Adam:动量与自适应的完美融合
核心公式:
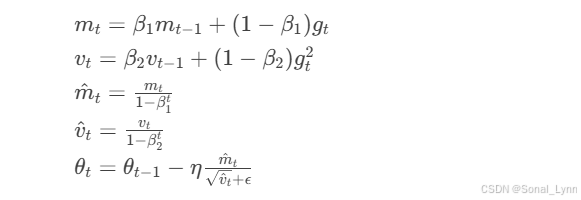
工业级配置:
keras.optimizers.Adam(
learning_rate=0.001,
beta_1=0.9,
beta_2=0.999,
epsilon=1e-07,
amsgrad=False
)三、优化器性能可视化实验
3.1 二维损失曲面轨迹对比
# 定义测试函数(Beale函数)
def beale(x, y):
return (1.5 - x + x*y)**2 + (2.25 - x + x*y**2)**2 + (2.625 - x + x*y 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3454
3454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











