






今天我给大家带来了超强的免费AI绘画工具Stable
Diffusion的保姆级安装教程,大家可以自行修炼。
首先我们先介绍一下Stable Diffusion:

Stable Diffusion是一个文本到图像的潜在扩散模型,由CompVis、Stability
AI和LAION的研究人员和工程师创建。它使用来自LAION-5B数据库子集的512x512图像进行训练。使用这个模型,可以生成包括人脸在内的任何图像,因为有开源的预训练模型,所以我们也可以在自己的机器上运行它。

一、文末扫码获取SD安装包
二、下载“Stable Diffusion(win)”(约13.8GB)并解压到本地(文件比较大,解压时间会比较长)
三、根据文件包内的教程进行安装即可

Stable
Diffusion是开源系统,和平常软件安装不同,不是下载的安装软件,点击安装就可以完成;通常开源系统,需要准备执行环境、编译源码,针对不同操作系统(操作系统依赖)、不同电脑(硬件依赖)还有做些手工调整。之后,会陆续提供其他系统的安装教程。
以下每一步都是精炼过的,务必一字不落的阅读,并按步骤执行!!!
仅仅适用于【苹果系列电脑(非M芯片)】!!!
硬件要求:
苹果系列电脑:台式或笔记本都可以;非M芯片。笔者的电脑配置:MacBook Pro、2.9GHz Intel Core i7。
一、下载Stable Diffusion
从github网站上直接下载源码,代码是托管在github上;有代码能力的同学可以自己通过git工具clone,其他同学直接下载就可以。
打开链接 https://github.com/CompVis/stable-diffusion?refer=17yongai.com
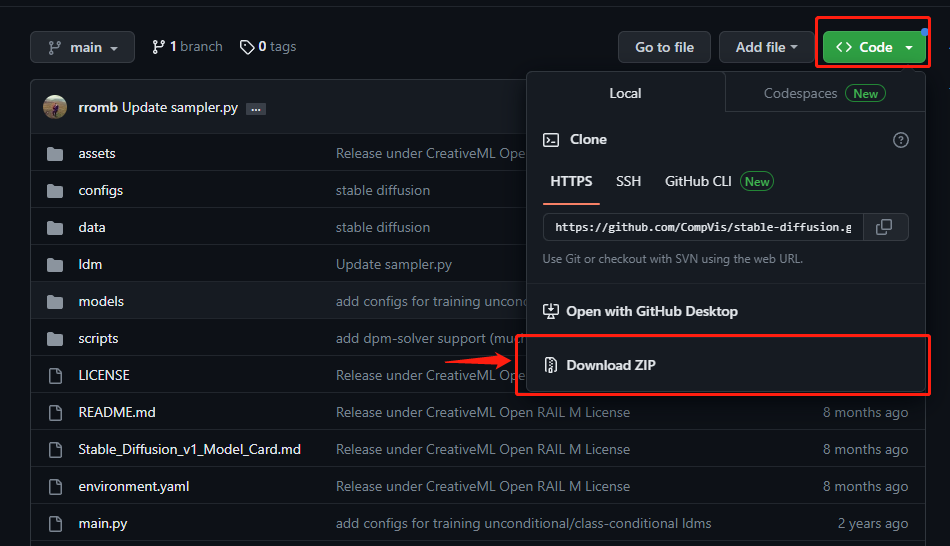
二、修改源代码
苹果系统上还不支持高版本cudatoolkit,只能使用9.0版本【待补充 代码的修改】
三、创建图片存放目录
在项目目录下载,创建目录,用于之后存放图片:【./stable-diffusion-main/Workspace】
到这里所以的准备工作基本完成,接下来通过命令进行环境的安装。
四、下载模型文件
从hugging face上下载模型文件
步骤:
必须确定好,模型的名称是【stable-diffusion-v-1-4-original】,下载的文件是
【sd-v1-4.ckpt】有4.27GB。下载的文件,放到之前的项目工程的目录下:【./stable-diffusion-
main/models/ldm/sd-v1-4.ckpt】;请勿改变位置,之后会用到。
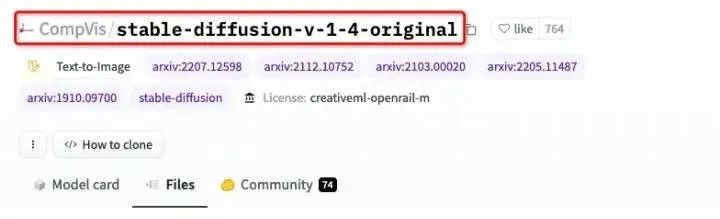
在【Files】分页中,下载 sd-v1-4.ckpt
**注意:**必须 在hugging face上注册账号。必须 在页面的【Model card】选项卡下,勾选接受协议。

接受协议,然后才能下载
完成这两步后,才可以在【Files and versions】选项卡里,下载到模型文件;否则看到的就是 403报错页面。
五、安装运行环境
下载conda安装软件
下载地址:https://docs.conda.io/en/latest/miniconda.html?refer=17yongai.com
笔者选择的 Python3.8版本的conda
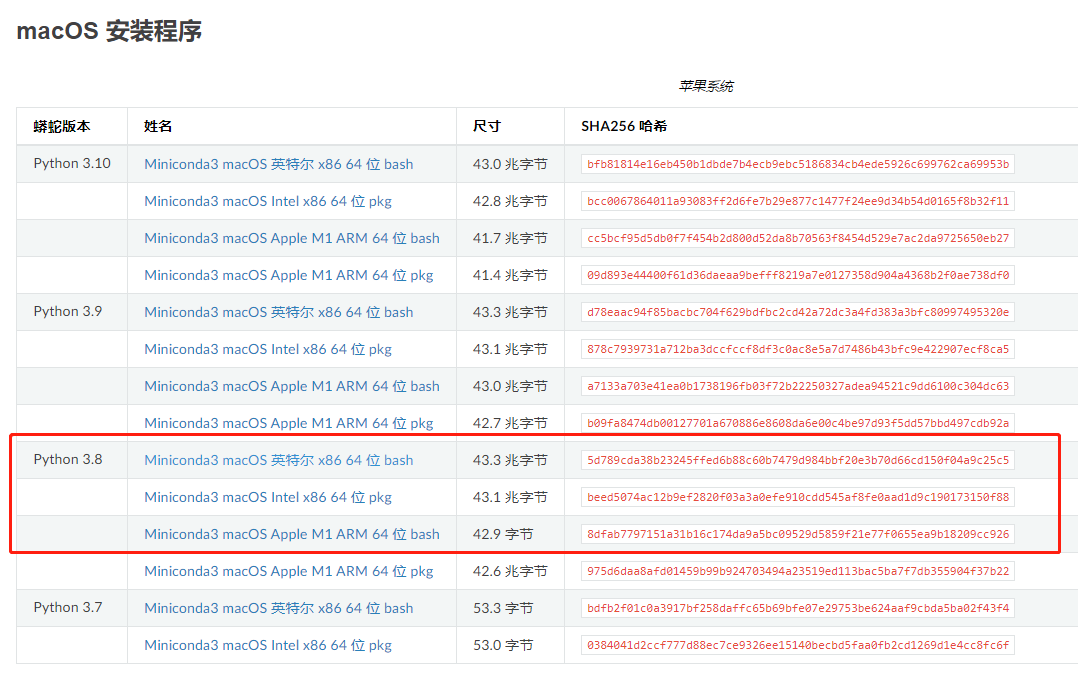
Conda
是一个python环境管理系统,用于安装多个版本的软件包及其依赖关系,并在它们之间轻松切换。这样就方便在各个版本python之间切换。也不会和电脑系统已经安装的python有冲突。
在工程目录下,执行以下命令
conda env create -f environment.yaml conda activate ldm
更新latent diffusion模型(不知道干啥的?不要紧,照样执行就可以)
conda install pytorch torchvision -c pytorch pip install transformers==4.19.2
diffusers invisible-watermark pip install -e .
注意:
第一次执行命令的时候,会自动从网上下载必要的模型文件;因此务必保证电脑在联网的状态。由于使用CPU进行计算,因此出图的数据非常慢;在我的电脑上是
3张图用时40分钟。
文末扫码获取SD懒人安装包
六、出图



(以上图片来源于网络,如有侵权联系删除)
但由于AIGC刚刚爆火,网上相关内容的文章博客五花八门、良莠不齐。要么杂乱、零散、碎片化,看着看着就衔接不上了,要么内容质量太浅,学不到干货。
这里分享给大家一份Adobe大神整理的《AIGC全家桶学习笔记》,相信大家会对AIGC有着更深入、更系统的理解。
有需要的朋友,可以长按下方二维码,免费领取!

AIGC所有方向的学习路线思维导图
这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。如果下面这个学习路线能帮助大家将AI利用到自身工作上去,那么我的使命也就完成了:
AIGC工具库
AIGC工具库是一个利用人工智能技术来生成应用程序的代码和内容的工具集合,通过使用AIGC工具库,能更加快速,准确的辅助我们学习AIGC

有需要的朋友,可以点击下方卡片免费领取!
精品AIGC学习书籍手册
书籍阅读永不过时,阅读AIGC经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验,结合自身案例融会贯通。
AI绘画视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,科学有趣才能更方便的学习下去。

有需要的朋友,可以长按下方二维码,免费领取!

















 6233
6233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









