






前言
Stable Diffusion也能生成视频 了!
你没听错,StabilityAI发布了StableAnimation SDK文本动画生成工具包。这个全新工具支持多种输入方式,包括纯文本、文本+初始图像以及文本+视频组合输入。

使用者可以调用包括Stable Diffusion 2.0、Stable Diffusion XL在内的所有Stable
Diffusion模型,来生成动画。
Stable Animation SDK的强大功能一经展现,网友惊呼:
哇哦,等不及想试试了!

目前,Stability AI疑似还在对这个新工具进行技术优化,不久后将公开驱动动画API的组件源代码。
3D漫画摄影风,不限时长自动生成
Stable Animation SDK可支持三种 创建动画的方式:
1、 文本转动画 :用户输入文prompt并调整各种参数以生成动画(与Stable Diffusion相似)。
2、文本输入+初始图像输入 :用户提供一个初始图像,该图像作为动画的起点。图像与文本prompt结合,生成最终的输出动画。
3、视频输入+文本输入 :用户提供一个初始视频作为动画的基础。通过调整各种参数,根据文本prompt生成最终的输出动画。

除此之外,Stable Animation SDK对生成视频的时长没有限制,但是长视频将需要更长的时间来生成。

Stability AI发布了Stable Animation SDK后,有很多网友分享了自己测试效果,让我们一起看下吧:



Stable Animation SDK可以设置许多参数,例如steps、sampler、scale、seed。
还有下面这么多的预设风格 可选择:
3D模型、仿真胶片、动漫、电影、漫画书、数码艺术、增强幻想艺术、等距投影、线稿、低多边形、造型胶土、霓虹朋克、折纸、摄影、像素艺术。

目前,动画功能API的使用是以积分计费的,10美元 可抵1000积分。
使用Stable Diffusion
v1.5模型,在默认设置值(512x512分辨率,30steps)下,生成100帧(大约8秒)视频将消耗37.5积分 。
默认情况下,每生成1帧,Cadence值设置为1个静止图像,可根据不同的动画模式选择较低或较高的Cadence值。Cadence值的上限是动画中的总帧数,即至少生成一张静止图像。视频转视频的Cadence必须为
1:1。
官方也给出了一个示例,可以看出生成100帧标准动画的标准静止图像(512x512/768x768/1024x1024,30 steps),
随着Cadence值变化,积分的使用情况:
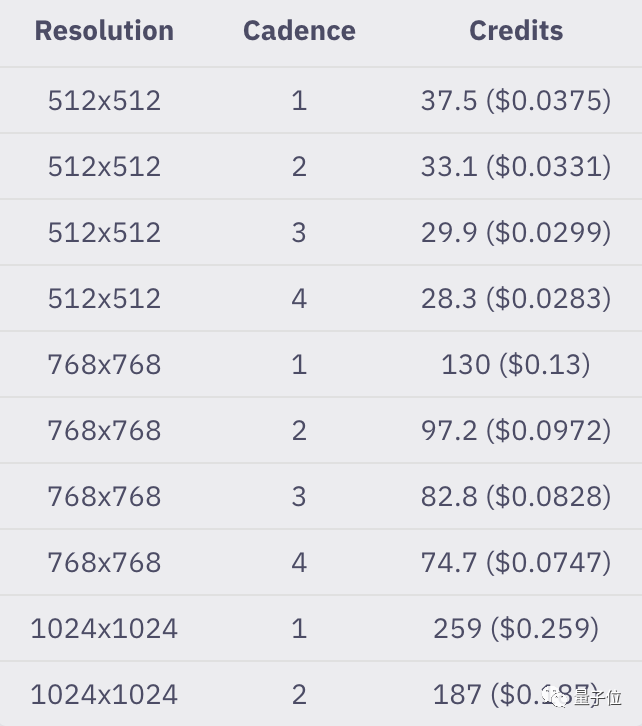
简单来说,受参数、时长等各种因素的影响,生成视频的费用并不固定。
效果和价格我们都了解了,那如何安装并调用API呢?
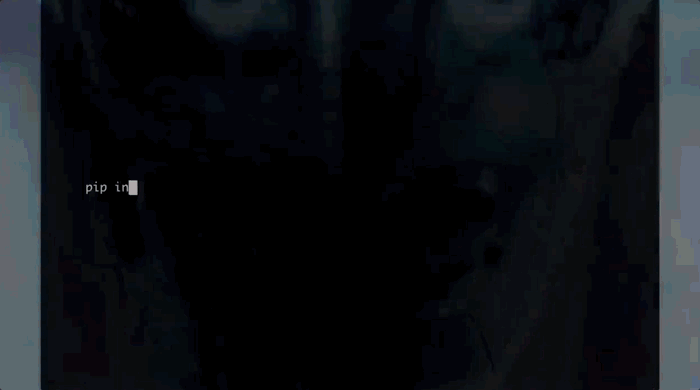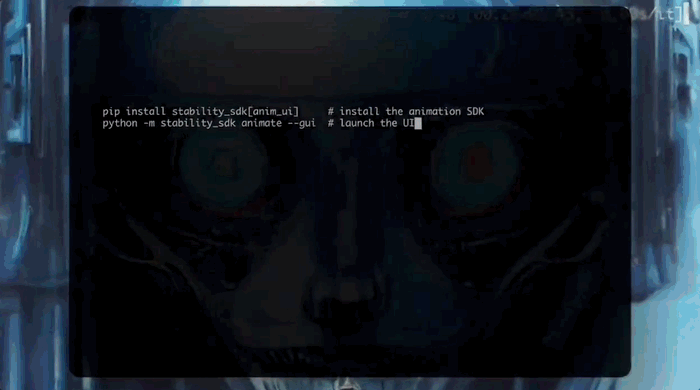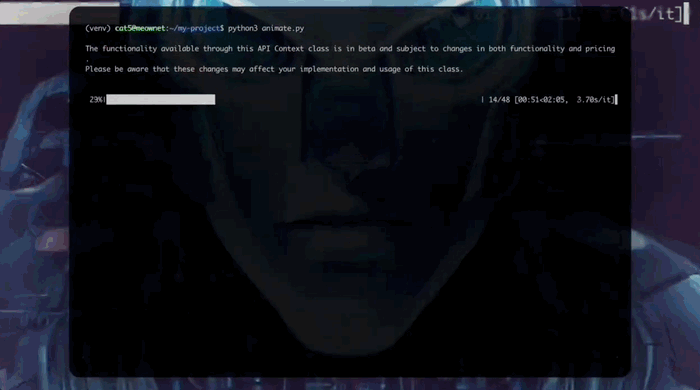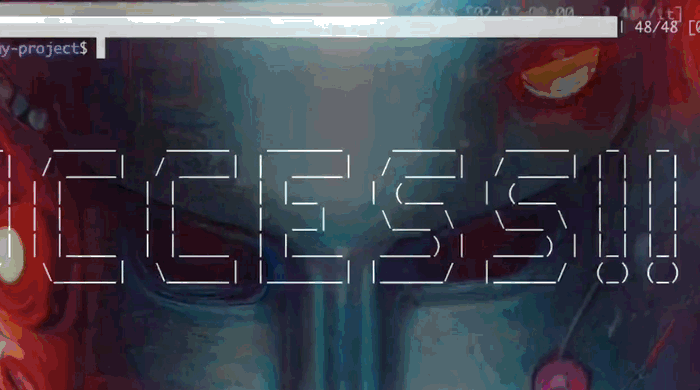
要创建动画并测试SDK的功能,只需要两个步骤即可运行用户界面:

在开发应用程序时,需要先设置一个Python虚拟环境,并在其中安装Animation SDK:
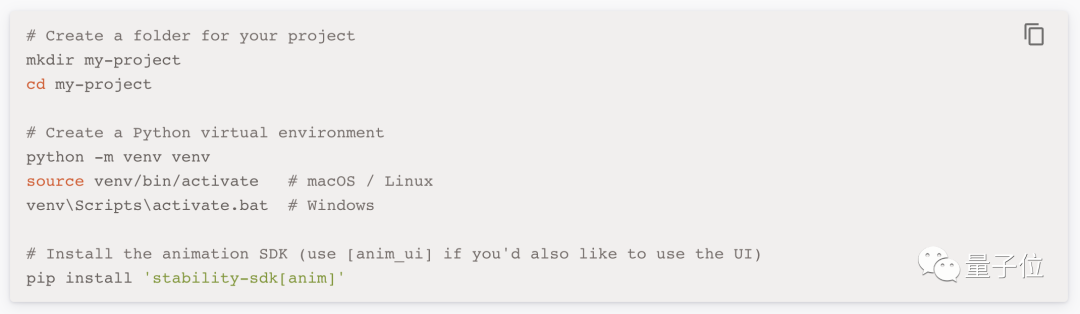
具体使用说明书放在文末啦!

越发火热的视频生成
最近,视频生成领域变得越来越热闹了。
比如,AI视频生成新秀Gen-2内测作品流出,网友看完作品直呼:太不可思议了!

Gen-2的更新更是一口气带来了八大功能:
文生视频、文本+参考图像生视频、静态图片转视频、视频风格迁移、故事板(Storyboard)、Mask(比如把一只正在走路的小白狗变成斑点狗)、渲染和个性化(比如把甩头小哥秒变海龟人)。
还有一位名叫Ammaar Reshi的湾区设计师用ChatGPT和MidJourney两个生成AI模型,成功做出一部蝙蝠侠的动画小电影,效果也是非常不错。

自Stable Diffusion开源后,一些开发者通过Google Colab等形式分享了各种魔改后的功能,自动生成动画功能一步步被开发出来。
像国外视频特效团队Corridor,他们基于Stable Diffusion,对AI进行训练,最终能让AI把真人视频转换为动画版本……
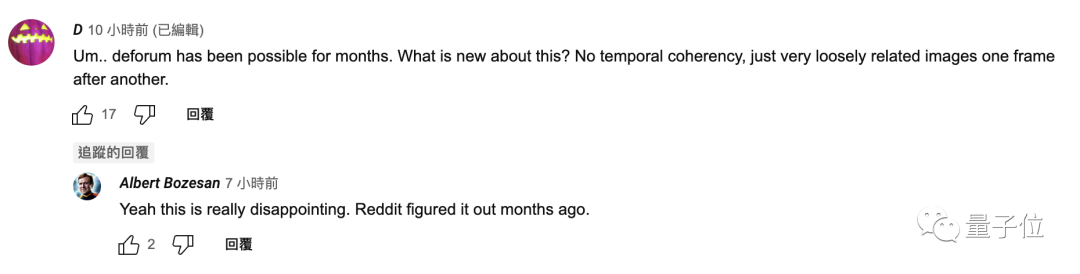
大家在对新工具的出现兴奋不已的同时,也有网友对Stable Animation SDK生成的视频所展现出的效果发出质疑:
这与 deforum有什么区别?没有时间线都不连贯,只有非常松散的一帧接一帧的图像。
那么你玩过这些工具了吗?感觉效果如何?
这是一位SD资深大神整理的,100款Stable Diffusion超实用插件,涵盖目前几乎所有的,主流插件需求。
全文超过4000字。
我把它们整理成更适合大家下载安装的【压缩包 】,无需梯子,并根据具体的内容,拆解成一二级目录 ,以方便大家查阅使用。
单单排版就差不多花费1个小时。
希望能让大家在使用Stable Diffusion工具时,可以更好、更快的获得自己想要的答案,以上。
如果感觉有用,帮忙点个支持,谢谢了。
想要原版100款插件整合包的小伙伴,可以来点击下方插件直接免费获取

100款Stable Diffusion插件:
面部&手部修复插件:After Detailer
在我们出图的时候,最头疼的就是出的图哪有满意,就是手部经常崩坏。只要放到 ControlNet 里面再修复。
现在我们只需要在出图的时候启动 Adetailer 就可以很大程度上修复脸部和手部的崩坏问题
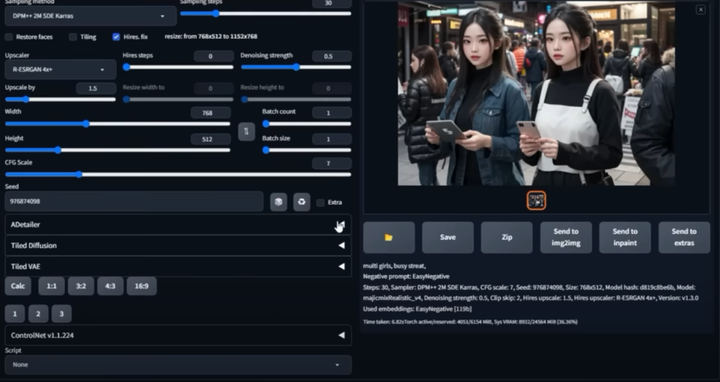
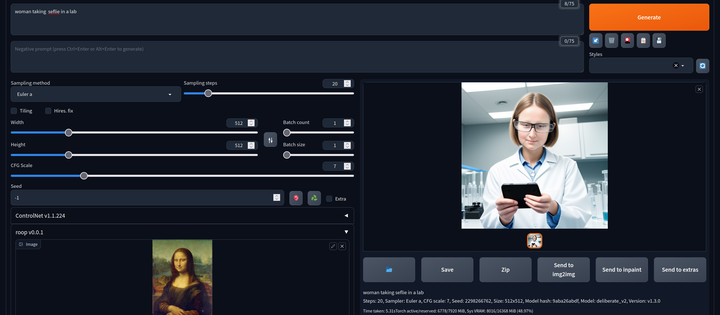
AI换脸插件:sd-webui-roop
换脸插件,只需要提供一张照片,就可以将一张脸替换到另一个人物上,这在娱乐和创作中非常受欢迎。
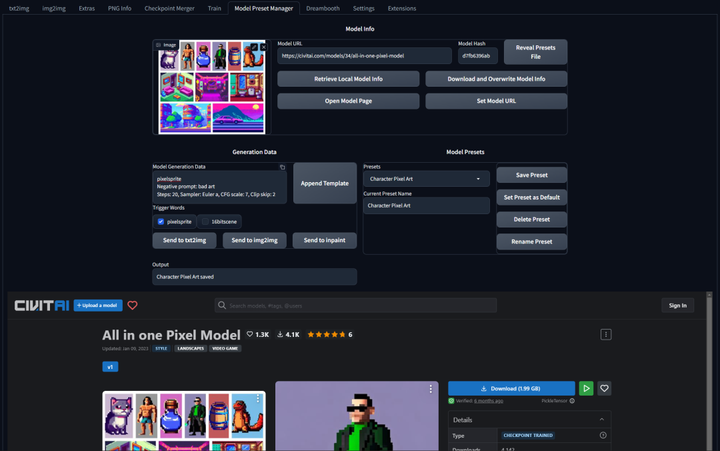
模型预设管理器:Model Preset Manager
这个插件可以轻松的创建、组织和共享模型预设。有了这个功能,就不再需要记住每个模型的最佳
cfg_scale、实现卡通或现实风格的特定触发词,或者为特定图像类型产生令人印象深刻的结果的设置!
现代主题:Lobe Theme
已经被赞爆的现代化 Web UI 主题。相比传统的 Web UI 体验性大大加强。

提示词自动补齐插件:Tag Complete
使用这个插件可以直接输入中文,调取对应的英文提示词。并且能够根据未写完的英文提示词提供补全选项,在键盘上按↓箭头选择,按 enter 键选中

提示词翻译插件:sd-webui-bilingual-localization
这个插件提供双语翻译功能,使得界面可以支持两种语言,对于双语用户来说是一个很有用的功能。
提示词库:sd-webui-oldsix-prompt
提供提示词功能,可能帮助用户更好地指导图像生成的方向。
上千个提示词,无需英文基础快速输入提示词,该词库还在不断更新。
以后再也不担心英文写出不卡住思路了!
由于篇幅原因,有需要完整版Stable Diffusion插件库的小伙伴,点击下方插件即可免费领取
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 366
366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









