







READ ME
代码最后更新时间:2023-6-10
1、环境要求
python3.9+windows 10
测试csv文件需要的相关库:(test-only.py)
numpy、csv、time、re、jieba_fast(可用jieba替代,只是运行时间会延长)
从零开始建模测试需要的相关库:(main.py)
numpy、csv、time、re、jieba_fast(可用jieba替代,只是运行时间会延长)
random、nltk(nltk用于自然语言文本处理,非分类)
2、代码文件
test-only.py
专门用于实验验收时测试,读取测试文件“test.csv"后直接运行即可。
调用原本已有的stopwords.txt(停用词)、vocabList.csv(已跑好的词汇表)、model.npz(已跑好的模型)
最终生成result.csv文件保存结果。
import numpy as np
import csv
import time
import re
import jieba_fast as jieba
#加载测试集
def loadTestFile(dataFileName):
file = open(dataFileName, encoding='UTF-8')
headers = next(file)#读取时跳过第一行的label和review
# 读取文件中的所有行
contents = file.readlines()
file.close()
# 分词处理
classVec = []
contentList = []
for line in contents:
classVec.append(int(line[0]))
# 利用正则表达式u'[\u4e00-\u9fa5]+'过滤掉输入数据中的所有非中文字符;
contentstr = "".join(re.findall(u'[\u4e00-\u9fa5]+', line[2:]))
content = (" ".join(jieba.cut(contentstr))).strip('\n').split(' ')
content = [item for item in content if len(item) > 1]
contentList.append(content)
return contentList, classVec
def Words_to_vec(vocabList, wordSet):
"""
1.函数说明:根据vocabList词汇表 将每个评价分词后再进行向量化 即出现为1 不出现为0
2.vocablit: 词汇表
3.wordSet: 生成的词向量
return:返回的词向量
"""
featureVec = [0] * len(vocabList)
for word in wordSet:
if word in vocabList:
# 如果在词汇表中的话 便将其所在位置赋为1
featureVec[vocabList.index(word)] = 1
else:
pass
return featureVec
def classifyNB(vec2Classify, pVec, p):
"""
1.函数说明:分类 比较p0、p1、p2、p3的大小 并返回相应的预测类别
2.vec2Classify:返回的词汇表对应的词向量
"""
p0 = sum(np.log(vec2Classify *
pVec[0] + (1 - vec2Classify) * (1 - pVec[0]))) + np.log(p[0])
p1 = sum(np.log(vec2Classify *
pVec[1] + (1 - vec2Classify) * (1 - pVec[1]))) + np.log(p[1])
p2 = sum(np.log(vec2Classify *
pVec[2] + (1 - vec2Classify) * (1 - pVec[2]))) + np.log(p[2])
p3 = sum(np.log(vec2Classify *
pVec[3] + (1 - vec2Classify) * (1 - pVec[3]))) + np.log(p[3])
pmax = max(p0, p1, p2, p3)
if p0 == pmax:
return 0
elif p1 == pmax:
return 1
elif p2 == pmax:
return 2
else:
return 3
def main():
# 加载测试集数据进行测试
testList, testLable = loadTestFile("testshuffle_label.csv")
#加载词汇表
vocabList = []
file = open("vocabList.csv", encoding='gb18030')
contents = file.readlines()
file.close()
for line in contents:
for word in line.strip('\n').split(' '):
if word != '':
vocabList.append(word)
print("加载词汇表完成")
# 加载模型
model = np.load("model.npz")
pVec = model['pVec']
p = model['p']
predictLable = []
nn = 0
print("开始测试")
for test in testList:
doc = np.array(Words_to_vec(vocabList, test))
nn += 1
if nn % 200 == 0:
print("正在处理第%s条数据" % nn)
if classifyNB(doc, pVec, p) == 0:
predictLable.append(0)
elif classifyNB(doc, pVec, p) == 1:
predictLable.append(1)
elif classifyNB(doc, pVec, p) == 2:
predictLable.append(2)
else:
predictLable.append(3)
print("测试完毕")
result = open("result.csv", 'w', encoding='gb18030')
for label in predictLable:
result.write(str(label) + '\n')
result.close()
TP = [0, 0, 0, 0]
labelNum = [0, 0, 0, 0]
for i in range(len(testLable)):
if testLable[i] == 0:
labelNum[0] += 1
if predictLable[i] == 0:
TP[0] += 1
elif testLable[i] == 1:
labelNum[1] += 1
if predictLable[i] == 1:
TP[1] += 1
elif testLable[i] == 2:
labelNum[2] += 1
if predictLable[i] == 2:
TP[2] += 1
else:
labelNum[3] += 1
if predictLable[i] == 3:
TP[3] += 1
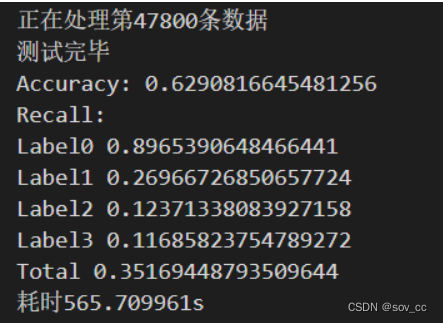
print("Accuracy: " + str(sum(TP) / sum(labelNum)))
result0 = TP[0] / labelNum[0]
result1 = TP[1] / labelNum[1]
result2 = TP[2] / labelNum[2]
result3 = TP[3] / labelNum[3]
result_max=max(result0,result1,result2,result3)
print("MAX_Accuracy:")
print(result_max)
# print("Recall:")
# print("Label0 " + str(TP[0] / labelNum[0]))
# print("Label1 " + str(TP[1] / labelNum[1]))
# print("Label2 " + str(TP[2] / labelNum[2]))
# print("Label3 " + str(TP[3] / labelNum[3]))
# print("Total " + str((TP[0] / labelNum[0] + TP[1] /
# labelNum[1] + TP[2] / labelNum[2] + TP[3] / labelNum[3]) / 4))
if __name__ == "__main__":
start = time.perf_counter()
main()
print("耗时{}s".format(time.perf_counter() - start))
运行结束示例:
delete.py
用于删掉csv文件中review行重复的内容。保留出现的第一条,后续再有重复的就删掉。
读取train.csv,运行后生成train_after.csv作为main.py文件读取的内容。
import csv
import pandas as pd
frame = pd.read_csv('train.csv', encoding='gb18030')
data = frame.drop_duplicates(subset=['review'], keep='first', inplace=False)
data.to_csv('train_after.csv', encoding='gb18030')
# df.drop_duplicates(subset=['A', 'B', 'C'], keep='first', inplace=True)
# subset:表示要进去重的列名,默认为 None。
# keep:有三个可选参数,分别是 first、last、False,
# 默认为 first,表示只保留第一次出现的重复项,删除其余重复项,last 表示只保留最后一次出现的重复项,False 则表示删除所有重复项。
# inplace:布尔值参数,默认为 False 表示删除重复项后返回一个副本,若为 Ture 则表示直接在原数据上删除重复项。
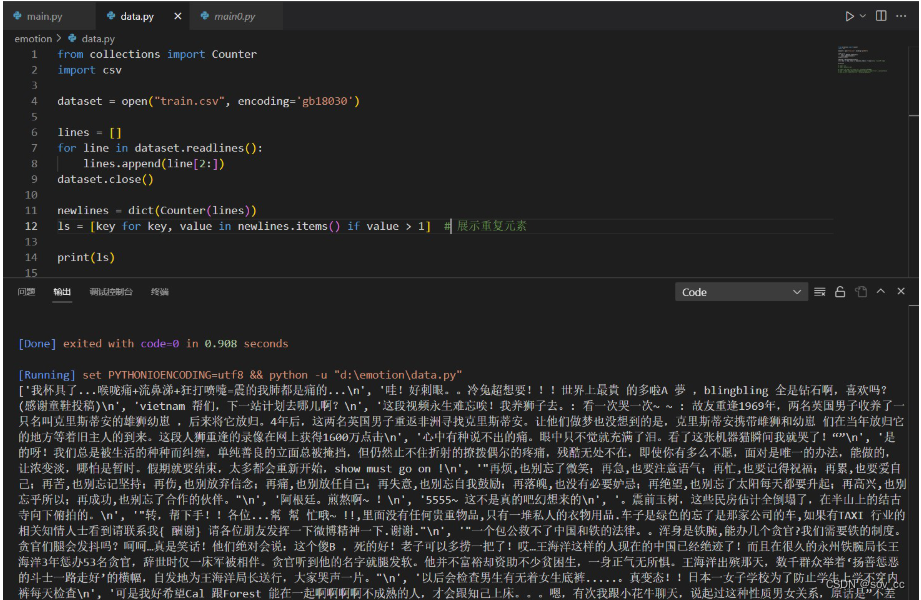
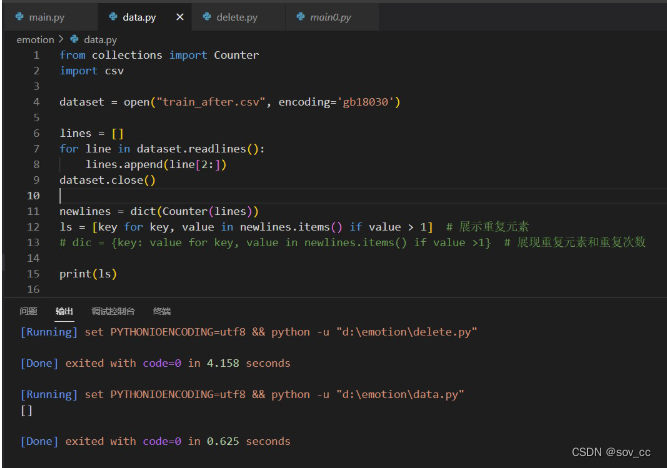
data.py
判断文件预处理的效果用,可以检测csv文件中review列是否还有重复,并输出有重复的内容。
from collections import Counter
import csv
dataset = open("train_after.csv", encoding='gb18030')
lines = []
for line in dataset.readlines():
lines.append(line[2:])
dataset.close()
newlines = dict(Counter(lines))
ls = [key for key, value in newlines.items() if value > 1] # 展示重复元素
# dic = {key: value for key, value in newlines.items() if value >1} # 展现重复元素和重复次数
print(ls)
有重复的时候:
没重复的时候:
main.py
主代码,含测试集与训练集的划分(80%测试集),基于朴素贝叶斯建模后保存模型,并且读取测试集测试得出准确率等全套步骤。
跑一次大概需要40-60min。
读取train_after.csv,调用已有的stopwords.txt
运行后会生成train_demo.csv、test_demo.csv、result_demo.csv、vocabList_demo.csv、model_demo.npz
import jieba_fast as jieba
import numpy as np
import re
import random
import time
import csv
#nltk库用于自然语言文本处理,非分类
from nltk.probability import FreqDist, ConditionalFreqDist
from nltk.metrics import BigramAssocMeasures
#具体分离出训练集和测试集中的内容
def data_split(full_list, ratio):
n_total = len(full_list)
offset = int(n_total * ratio)
random.shuffle(full_list)
sublist_1 = full_list[:offset]
sublist_2 = full_list[offset:]
return sublist_1, sublist_2
#加载整个train_after.csv,分离出训练集和测试集,80%作为训练集,20%测试集
def split_train_test(dataFileName, ratio):
dataset = open(dataFileName, encoding='gb18030')
headers = next(dataset) # 读取时跳过第一行的label和review
contents = dataset.readlines()
dataset.close()
trainls, testls = data_split(contents, ratio)
trainset = open("train_demo.csv", "w", encoding='gb18030')
for row in trainls:
trainset.write(row)
trainset.close()
testset = open("test_demo.csv", "w", encoding='gb18030')
for row in testls:
testset.write(row)
testset.close()
#加载分离出的训练集文件
def dataProsessing(dataFileName):
file = open(dataFileName, encoding='gb18030')
# 读取文件中的所有行
contents = file.readlines()
file.close()
# 分词处理
classVec = []
contentList = []#用于存储过滤后的语句
label0Words = []
label1Words = []
label2Words = []
label3Words = []
labelNum = [0, 0, 0, 0]
for line in contents:
classVec.append(line[0])
# 利用正则表达式u'[\u4e00-\u9fa5]+'过滤掉输入数据中的所有非中文字符;
#\u4e00和\u9fa5正好是中文编码的开始和结束的两个值
mytext = "".join(re.findall(u'[\u4e00-\u9fa5]+', line[2:]))
content = (" ".join(jieba.cut(mytext))).strip('\n').split(' ')
stop = [row.strip() for row in open(
'stopwords.txt', 'r', encoding='gb18030').readlines()] # 停用词
content = [item for item in content if item not in stop] # 去除停用词
content = [item for item in content if len(item) > 1] # 一字词语过滤
contentList.append(content)
if line[0] == '0':
labelNum[0] += 1
for item in content:
label0Words.append(item) #把一整行存进去
elif line[0] == '1':
labelNum[1] += 1
for item in content:
label1Words.append(item)
elif line[0] == '2':
labelNum[2] += 1
for item in content:
label2Words.append(item)
elif line[0] == '3':
labelNum[3] += 1
for item in content:
label3Words.append(item)
return contentList, classVec, label0Words, label1Words, label2Words, label3Words, labelNum
# 获取信息量较高(前number个)的词的特征(卡方统计)
def jieba_feature(number, label0Words, label1Words, label2Words, label3Words, labelNum):
word_fd = FreqDist() # 可统计所有词的词频
con_word_fd = ConditionalFreqDist() # 可统计积极文本中的词频和消极文本中的词频
for word in label0Words:
word_fd[word] += 1
con_word_fd['0'][word] += 1
for word in label1Words:
word_fd[word] += 1
con_word_fd['1'][word] += 1
for word in label2Words:
word_fd[word] += 1
con_word_fd['2'][word] += 1
for word in label3Words:
word_fd[word] += 1
con_word_fd['3'][word] += 1
label0_word_count = con_word_fd['0'].N() # label0词的数量
label1_word_count = con_word_fd['1'].N() # label1词的数量
label2_word_count = con_word_fd['2'].N() # label2词的数量
label3_word_count = con_word_fd['3'].N() # label3词的数量
# 一个词的信息量等于积极卡方统计量加上消极卡方统计量
total_word_count = label0_word_count + label1_word_count + \
label2_word_count + label3_word_count
label0_word = {}
label1_word = {}
label2_word = {}
label3_word = {}
for word, freq in word_fd.items():
label0_score = BigramAssocMeasures.chi_sq(con_word_fd['0'][word], (freq,
label0_word_count), total_word_count)
label0_word[word] = label0_score
label1_score = BigramAssocMeasures.chi_sq(con_word_fd['1'][word], (freq,
label1_word_count), total_word_count)
label1_word[word] = label1_score
label2_score = BigramAssocMeasures.chi_sq(con_word_fd['2'][word], (freq,
label2_word_count), total_word_count)
label2_word[word] = label2_score
label3_score = BigramAssocMeasures.chi_sq(con_word_fd['3'][word], (freq,
label3_word_count), total_word_count)
label3_word[word] = label3_score
vocabList = []
ll = []
ll.append(sorted(label0_word.items(), key=lambda item: item[1], reverse=True)[
:int(labelNum[0] * number)])
ll.append(sorted(label1_word.items(), key=lambda item: item[1], reverse=True)[
:int(labelNum[1] * number)])
ll.append(sorted(label2_word.items(), key=lambda item: item[1], reverse=True)[
:int(labelNum[2] * number)])
ll.append(sorted(label3_word.items(), key=lambda item: item[1], reverse=True)[
:int(labelNum[3] * number)])
for item in ll:
for w, f in item:
vocabList.append(w)
vocabList = list(set(vocabList))
return vocabList
#加载测试集
def loadTestFile(dataFileName):
file = open(dataFileName, encoding='gb18030')
# 读取文件中的所有行
contents = file.readlines()
file.close()
# 分词处理
classVec = []
contentList = []
for line in contents:
classVec.append(int(line[0]))
# 利用正则表达式u'[\u4e00-\u9fa5]+'过滤掉输入数据中的所有非中文字符;
contentstr = "".join(re.findall(u'[\u4e00-\u9fa5]+', line[2:]))
content = (" ".join(jieba.cut(contentstr))).strip('\n').split(' ')
content = [item for item in content if len(item) > 1]
contentList.append(content)
return contentList, classVec
def Words_to_vec(vocabList, wordSet):
"""
1.函数说明:根据vocabList词汇表 将每个评价分词后再进行向量化 即出现为1 不出现为0
2.vocablit: 词汇表
3.wordSet: 生成的词向量
return:返回的词向量
"""
featureVec = [0] * len(vocabList)
for word in wordSet:
if word in vocabList:
# 如果在词汇表中的话 便将其所在位置赋为1
featureVec[vocabList.index(word)] = 1
else:
pass
return featureVec
def trainNB(trainMat, trainLabel):
"""
1.函数说明:朴素贝叶斯训练函数
2.trainMat:训练文本的词向量矩阵
3.trainLable:训练数据的类别标签
4.return:
pVecList:
p0vec:label为0的评论
p1vec:label为1的评论
p2vec:label为2的评论
p3vec:label为3的评论
pList:对应概率
"""
# 训练集的数量
numTraindocs = len(trainMat)
# 单词数
numWords = len(trainMat[0])
# 各类情感类评论数量及概率
p0Num = 0
p1Num = 0
p2Num = 0
p3Num = 0
for label in trainLabel:
if label == 0:
p0Num = p0Num + 1
elif label == 1:
p1Num = p1Num + 1
elif label == 2:
p2Num = p2Num + 1
else:
p3Num = p3Num + 1
p0 = p0Num / float(numTraindocs)
p1 = p1Num / float(numTraindocs)
p2 = p2Num / float(numTraindocs)
p3 = p3Num / float(numTraindocs)
label0Num = np.ones(numWords)
label1Num = np.ones(numWords)
label2Num = np.ones(numWords)
label3Num = np.ones(numWords)
for i in range(numTraindocs):
if trainLabel[i] == 0:
label0Num += trainMat[i]
elif trainLabel[i] == 1:
label1Num += trainMat[i]
elif trainLabel[i] == 2:
label2Num += trainMat[i]
else:
label3Num += trainMat[i]
p0vec = label0Num / (p0Num + 2)
p1vec = label1Num / (p1Num + 2)
p2vec = label2Num / (p2Num + 2)
p3vec = label3Num / (p3Num + 2)
pVec = np.array([p0vec, p1vec, p2vec, p3vec])
p = np.array([p0, p1, p2, p3])
return pVec, p
def classifyNB(vec2Classify, pVec, p):
"""
1.函数说明:分类 比较p0、p1、p2、p3的大小 并返回相应的预测类别
2.vec2Classify:返回的词汇表对应的词向量
"""
p0 = sum(np.log(vec2Classify *
pVec[0] + (1 - vec2Classify) * (1 - pVec[0]))) + np.log(p[0])
p1 = sum(np.log(vec2Classify *
pVec[1] + (1 - vec2Classify) * (1 - pVec[1]))) + np.log(p[1])
p2 = sum(np.log(vec2Classify *
pVec[2] + (1 - vec2Classify) * (1 - pVec[2]))) + np.log(p[2])
p3 = sum(np.log(vec2Classify *
pVec[3] + (1 - vec2Classify) * (1 - pVec[3]))) + np.log(p[3])
pmax = max(p0, p1, p2, p3)
if p0 == pmax:
return 0
elif p1 == pmax:
return 1
elif p2 == pmax:
return 2
else:
return 3
def main():
split_train_test("train_after.csv", 0.95)
trainList, trainLable, label0Words, label1Words, label2Words, label3Words, labelnum = dataProsessing(
"train_demo.csv")
vocabList = jieba_feature(
0.1, label0Words, label1Words, label2Words, label3Words, labelnum)
i = 0
file = open("vocabList_demo.csv", 'w', encoding='gb18030')
for item in vocabList:
file.write(item + " ")
i = i + 1
if i % 20 == 0:
file.write('\n')
file.close()
print("创建词汇表完成")
vocabList = []
file = open("vocabList_demo.csv", encoding='gb18030')
contents = file.readlines()
file.close()
for line in contents:
for word in line.strip('\n').split(' '):
if word != '':
vocabList.append(word)
print("加载词汇表完成")
trainMat = []
cnt = 0
for train in trainList:
cnt += 1
if cnt % 200 == 0:
print("正在处理第%s条训练数据" % cnt)
trainMat.append(Words_to_vec(vocabList, train))
print("训练集数据处理完毕")
pVec, p = trainNB(np.array(trainMat, dtype='float16'),
np.array(trainLable, dtype='float16'))
print("生成训练集指标")
print("训练样本数 %s" % cnt)
print("特征维度 %s" % len(vocabList))
print(pVec)
print(p)
# 保存模型
np.savez("model_demo.npz", pVec=pVec, p=p)
# 加载测试集数据进行测试
testList, testLable = loadTestFile("test_demo.csv")
# 加载模型
model = np.load("model_demo.npz")
pVec = model['pVec']
p = model['p']
predictLable = []
nn = 0
print("开始测试")
for test in testList:
doc = np.array(Words_to_vec(vocabList, test))
nn += 1
if nn % 200 == 0:
print("正在处理第%s条数据" % nn)
if classifyNB(doc, pVec, p) == 0:
predictLable.append(0)
elif classifyNB(doc, pVec, p) == 1:
predictLable.append(1)
elif classifyNB(doc, pVec, p) == 2:
predictLable.append(2)
else:
predictLable.append(3)
print("测试完毕")
result = open("result_demo.csv", 'w', encoding='gb18030')
for label in predictLable:
result.write(str(label) + '\n')
result.close()
TP = [0, 0, 0, 0]
labelNum = [0, 0, 0, 0]
for i in range(len(testLable)):
if testLable[i] == 0:
labelNum[0] += 1
if predictLable[i] == 0:
TP[0] += 1
elif testLable[i] == 1:
labelNum[1] += 1
if predictLable[i] == 1:
TP[1] += 1
elif testLable[i] == 2:
labelNum[2] += 1
if predictLable[i] == 2:
TP[2] += 1
else:
labelNum[3] += 1
if predictLable[i] == 3:
TP[3] += 1
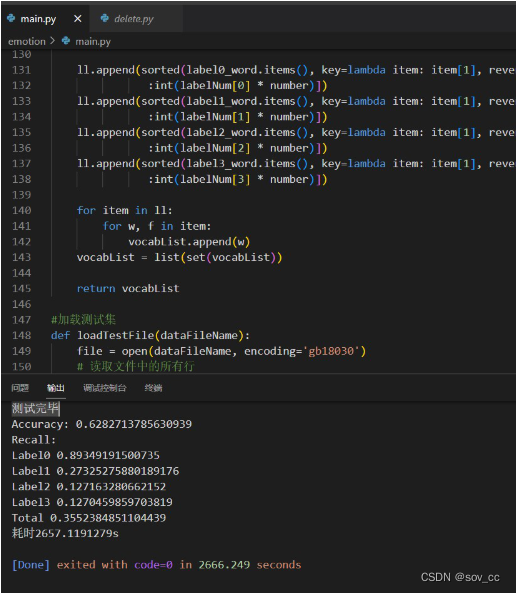
print("Accuracy: " + str(sum(TP) / sum(labelNum)))
print("Recall:")
print("Label0 " + str(TP[0] / labelNum[0]))
print("Label1 " + str(TP[1] / labelNum[1]))
print("Label2 " + str(TP[2] / labelNum[2]))
print("Label3 " + str(TP[3] / labelNum[3]))
print("Total " + str((TP[0] / labelNum[0] + TP[1] /
labelNum[1] + TP[2] / labelNum[2] + TP[3] / labelNum[3]) / 4))
if __name__ == "__main__":
start = time.perf_counter()
main()
print("耗时{}s".format(time.perf_counter() - start))
运行结束示例:















 6534
6534











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









