







 本文介绍了HMM的基础概念,包括过渡矩阵A、初始概率向量Π和观测矩阵B,以及如何用它来解决三个基本问题:计算显性状态链概率、找可能性最大隐性状态序列和估计模型参数。通过骰子问题举例,阐述了前向算法和维特比算法,并简述了Baum-Welch算法在模型参数估计中的应用。
本文介绍了HMM的基础概念,包括过渡矩阵A、初始概率向量Π和观测矩阵B,以及如何用它来解决三个基本问题:计算显性状态链概率、找可能性最大隐性状态序列和估计模型参数。通过骰子问题举例,阐述了前向算法和维特比算法,并简述了Baum-Welch算法在模型参数估计中的应用。
Hidden Markov Model, HMM 隐马尔可夫模型,是一种描述隐性变量(状态)和显性变量(观测状态)之间关系的模型。该模型遵循两个假设,隐性状态i只取决于前一个隐性状态i-1,而与其他先前的隐形状态无关。观测状态也只取决于当前的隐形状态。因此我们常常将隐马尔科夫模型表现为一种如下图所示链式的模型。
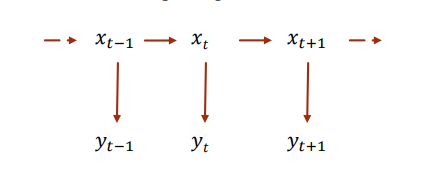
其中, x t x_t xt代表某一时刻的隐形状态链,其N个状态取值集合为 { s 1 , s 2 , s 3 , . . . , N } \{s_1,s_2,s_3,...,_N\} {
s1,s2,s3,...,N}。 y t y_t yt表示为对应的该时刻的显性状态(观测状态),其M个状态取值集合为 { o 1 , o 2 , o 3 , . . . , o k , . . . , o M } \{o_1,o_2,o_3,...,o_k,...,o_M\} {
o1,o2,o3,...,ok,...,oM}。隐马尔科夫模型 θ \theta θ可以由三个矩阵来进行描述 θ = ( A , B , Π ) \theta = (A,B,\Pi) θ=(A,B,Π)。
1. 大小为 N*N (N代表N种隐性的状态)的过渡矩阵 A:
A = { a i j } = { P ( x t + 1 = s j ∣ x t = s i ) } = { P ( s j ∣ s i ) } A = \{a_{ij}\} = \{P(x_{t+1}=s_j|x_t=s_i)\} = \{P(s_j|s_i)\} A={
aij}={
P(xt+1=sj∣xt=si)}={
P(sj∣si)}
过渡矩阵A中的每一个元素表示由上一个隐性状态 s i s_i si变为下一个隐性状态的条件概率。
2. 大小为 1*N 的初始概率向量 Π \Pi Π :
Π = π i = P ( x 1 = s i ) = P ( s i ) \Pi ={\pi_i} = {P(x_1 = s_i)} = {P(s_i)} Π=πi=P(x1=si)=P(si)
初始概率向量 Π \Pi Π中的每一个元素,表示初始隐性状态为 s i s_i si的概率,该向量的长度N与隐性状态的可能取值个数相同。
3. 大小为 M*N 的观测矩阵 B :
B = { b k i } = { P ( y t = o k ∣ x t = s i ) } = { P ( o k ∣ s i ) } B = \{b_{ki}\} = \{P(y_t=o_k|x_t=s_i)\} = \{P(o_k|s_i)\} B={ bki}={ P(yt=ok∣xt=si)}={ P(ok∣si)}
观测矩阵B中的每个元素,是用来描述N个隐形状态对应M个观测状态的概率。即在隐形状态为 s i s_i si 的条件下,观测状态为 o k o_k ok的概率。
上述三个矩阵构成了一个完整的隐马尔可夫模型。
掷骰子问题可以帮助我们更好地理解显性状态链和隐性状态链。例如我们有三个面数不一样的骰子可供选择投掷,三个骰子一个面数为4,一个面数为6,一个面数为8。每次选择的骰子是随机的且满足继续选到同一个骰子的概率是选到其他骰子概率的两倍。此时,隐性状态链 x t x_t xt就是我们每次选择的骰子,取值集合就是骰子1,骰子2,骰子3。显性状态链就是我们掷出的一系列数值,取值集合为 { 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 } \{1,2,3,4,5,6,7,8\} {
1,2,3,4,5,6,7,8}。
根据上述的信息,我们不难整理出这个骰子问题HMM模型的三个核心矩阵 :
过渡矩阵A
| previous state \ current state | D4 | D6 | D8 |
|---|---|---|---|
| D4 | 2 3 \frac{2}{3} 32 | 1 6 \frac{1}{6} 61 | 1 6 \frac{1}{6} 61 |
| D6 | 1 6 \frac{1}{6} 61 | 2 3 \frac{2}{3} 32 | 1 6 \frac{1}{6} 61 |
| D8 | 1 6 \frac{1}{6} 61 | 1 6 \frac{1}{6} 61 | 2 3 \frac{2}{3} 32 |
初始概率向量 Π \Pi Π
由于一开始是随机选取骰子,因此初始抽到三个骰子的概率是相同的 1 3 \frac{1}{3} 31。
| D4 | D6 | D8 |
|---|---|---|
| 1 3 \frac{1}{3} 31 | 1 3 \frac{1}{3} 31 | 1 3 \frac{1}{3} 31 |
观测矩阵B :
观测矩阵存放了每种隐性状态下各观测状态的条件概率
| observed state \ hidden state | D4 | D6 | D8 |
|---|---|---|---|
| 1 | 1 4 \frac{1}{4} 41 | 1 6 \frac{1}{6} 61 | 1 8 \frac{1}{8} 81 |
| 2 | 1 4 \frac{1}{4} 41 | 1 6 \frac{1}{6} 61 | 1 8 \frac{1}{8} 81 |
| 3 | 1 4 \frac{1}{4} 41 | 1 6 \frac{1}{6} 61 | 1 8 \frac{1}{8} 81 |
| 4 | 1 4 \frac{1}{4} 41 | 1 6 \frac{1}{6} 61 | 1 8 \frac{1}{8} 81 |
| 5 | 0 | 1 6 \frac{1}{6} 61 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









