







62 序列到序列学习(seq2seq)【动手学深度学习v2】
深度学习学习笔记
学习视频:https://www.bilibili.com/video/BV16g411L7FG/?spm_id_from=autoNext&vd_source=75dce036dc8244310435eaf03de4e330
一个句子翻译到另一个句子。
seq2seq 最早是用来做机器翻译(给定个源句子,自动翻译成目标语言)。
Seq2Seq 是一个encoder和decoder的架构。
encoder给你一个句子,解码器翻译输出。编码器用的是一个RNN,每次不断的给到一个Seq,最后的隐藏状态传给解码器。可以是双向的,encoder可以双向,而decoder不能,双向RNN经常用在encoder里面。
解码器用一个RNN输出:隐藏状态过来给一个< bos > 表示开始翻译,然后上一次翻译作为下一个时刻的输入,隐藏状态也过去,不断这样过去得到输出。
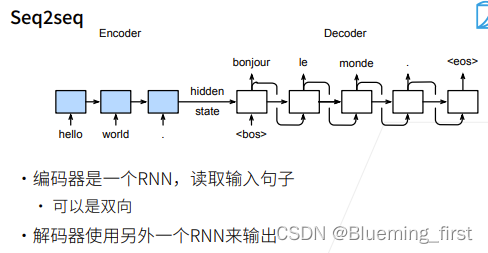
RNN 不需要规定句子的长度,按照时刻时刻往前走,最后返回最后时刻的隐藏层。Seq2Seq可以处理任意长度的句子。
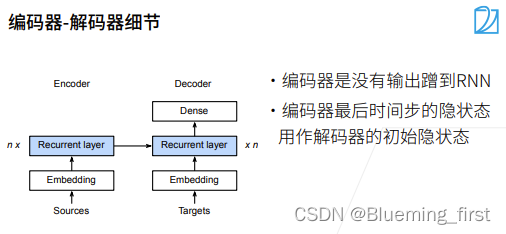
隐藏状态如何传的?最后一层的RNN在最后的时刻的隐藏状态,跟句子的输入embedding结合起来作为Recurrent Layer的输入。所以编码器不需要输出的(不需要全连接层)只有拿到RNN的输入状态就可以了,结合初始状态作为下一层的输入。(编码器的RNN的隐藏层输出结果 和 输入的embedding结合起来给到解码器的recurrent 层)
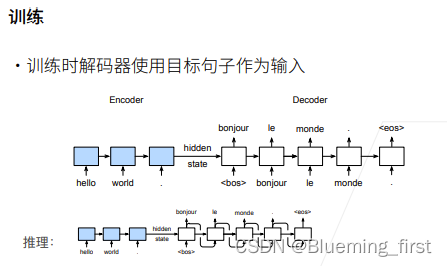
训练: 在训练时知道真的翻译(目标句子),decoder每个输入实际上是用的真正的翻译,就是即使上一个时刻的翻译是错误的,给到下一个时刻的输入依旧传入的是正确的真实的翻译结果,这样时序序列就可以预测长的序列,在训练的时候给的是真正的词。
推理:推理时没有真正的翻译,于是只能用上一时刻的输出作为下一时刻的输入,然后预测下去。
衡量生成序列的好坏的BLEU
之前是预测一个词,现在预测一个句子。预测的句子和真实的句子长度可能不一样,那么如何去判断预测的句子的好坏?
BLEU(机器学习最常用的衡量状态)。
算所有n-gram的精度,pn就是预测所有n-gram的精度,unique-gram就是单个词对应的预测精度,by-gram就是两个词对应的预测精度,那么n-gram就n个长度的词组成的句子的预测精度。
然后 min(1-预测长度/真实长度) 叫做惩罚过短预测 ,用来防止预测过短;pn<=1 n 越大 (2^n)/1就越小,乘起来长匹配有高权重 就越大。

seq2seq就是从一个句子生成另一个句子(机器翻译只是其中一个),使用的编码器解码器的架构,将编码器最后时刻的隐状态来初始化解码器的隐状态,也会作为一个输入穿进去。然后这种方式也经常用BLEU来作为衡量结果。
















 460
460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









