







数据、代码等相关资料来源于b站日月光华老师视频,此博客作为学习记录。
一、softmax函数
之前对于员工是否离职的MLP程序,他是一个二分类问题,我们使用了sigmoid函数作为激活。那么对于多分类问题呢?可以看看softmax函数,它是对数几率回归在N个可能不同的值上的推广。



当只有两个类别的时候,也就相当于sigmoid激活函数。在pytorch里使用nn.CrossEntropyLoss()和nn.NLLLoss等进行softmax交叉熵。
二、torchvision库
torchvision库是PyTorch框架中用来处理图像和视频的一个辅助库,属于PyTorch项目的一部分。PyTorch通过torchvision库提供了一些常用的数据集、模型、转换函数等等torchvision库提供的内置数据集可用于测试、学习和创建基准模型。

torchvision加载的内置图片数据集均继承自torch.utils.data.Dataset类,因此我们可直接使用加载的内置数据集创建DataLoader。PyTorch内置图片数据集均在torchvision.datasets模块下,包含Caltech,CelebA、CIFAR、Cityscapes.CocO、Fashion-MNIST、ImageNet、MNIST等等很多著名的数据集。

接下来通过代码进行了解。
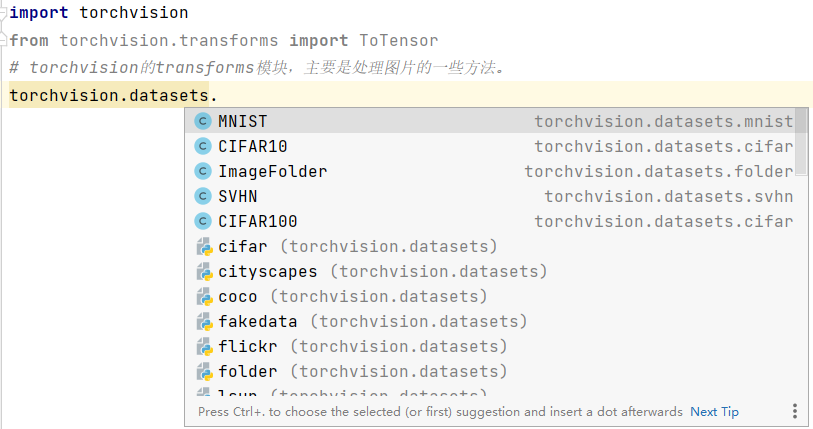
可以看到torchvision的datasets方法下的多个数据库,若选MNIST作为数据集,则需填入一些参数:
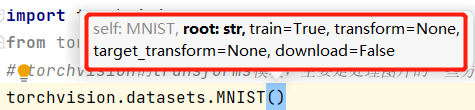
四个参数:数据集存储路径、是否训练、transform方法、是否下载数据集。
其中方法ToTensor()的作用:
1.将输入转为tensor;
2.规范图片格式为pytorch中的图像格式:(channel, height, width)
3.将像素取值范围规范到(0,1)
运行时如果下载很慢,可以把链接复制到迅雷里下载。
下载好了以后,再运行就不会再下载了,直接使用本地下载好的。
接下来使用Dataloader对dataset进行封装,参数如下:
1.shuffle:可选择True OR False,看是否乱序;
2.batch_size:将数据采样为小批次(单个训练,则单个样本可能引起梯度巨大震荡,出现一个不好的样本,就很影响结果;如果使用全部数据,计算机内存又放不下;所以通过批次进行数据的遍历,在节省内存的情况下以批次影响梯度)
3.num_workers:多进程进行处理
4.collate_fn:设置批次处理函数
# torch.utils.data.DataLoader 使用DataLoader对datasets进行封装
train_dl = torch.utils.data.DataLoader(train_ds, batch_size=64, shuffle=True)
test_dl = torch.utils.data.DataLoader(test_ds, batch_size=64, shuffle=False)
从DataLoader中取出一个批次的数据进行查看:
imgs, labels = next(iter(train_dl)) # iter生成器,next返回一个批次的数据
plt.figure(figsize=(10,1)) # 看看前10张图
for i,img in enumerate(imgs[:10]):
npimg = img.numpy() # 图是tensor,转成numpy
npimg = np.squeeze(npimg)
plt.subplot(1,10,i+1) # 1行,10列
plt.imshow(npimg)
plt.axis('off') # 坐标轴关闭
plt.show()
print(labels[:10])
结果:


三、完整代码
import torch.utils.data
import torchvision
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
import numpy as np
# torchvision的transforms模块,主要是处理图片的一些方法。
# 加载数据集
train_ds = torchvision.datasets.MNIST('data', train=True, transform=ToTensor(), download=True)
test_ds = torchvision.datasets.MNIST('data', train=False, transform=ToTensor(), download=True)
# torch.utils.data.DataLoader 使用DataLoader对datasets进行封装
train_dl = torch.utils.data.DataLoader(train_ds, batch_size=64, shuffle=True)
test_dl = torch.utils.data.DataLoader(test_ds, batch_size=64, shuffle=False)
imgs, labels = next(iter(train_dl)) # iter生成器,next返回一个批次的数据
plt.figure(figsize=(10,1)) # 看看前10张图
for i,img in enumerate(imgs[:10]):
npimg = img.numpy() # 图是tensor,转成numpy
npimg = np.squeeze(npimg)
plt.subplot(1,10,i+1) # 1行,10列
plt.imshow(npimg)
plt.axis('off') # 坐标轴关闭
plt.show()
print(labels[:10])















 4020
4020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











