









Visualizing and understanding convolutional networks
Absolution
大型卷积网络模型最近在ImageNet基准测试中证明了令人印象深刻的分类性能。但是,对于它们为什么表现如此出色或如何进行改进尚无明确的了解。本文介绍了一种可视化技术可深入了解中间要素层的功能以及分类器的操作。 在诊断角色中使用时,这些可视化使我们能够找到优于Krizhevsky等人的模型架构。 在ImageNet分类基准上。 我们还进行了消融研究,以发现不同模型层对性能的贡献。 我们展示了ImageNet模型可以很好地推广到其他数据集:重新训练softmax分类器时,它令人信服地击败了Caltech-101和Caltech-256数据集上的最新结果。
1.Introduction
近年来,随着技术发展,卷积神经网络的性能越来越强,且应用越来越广。但是有疑问就是这些复杂模型的内部操作和行为,以及是如何获得如此好的性能,还是很难理解。
本文介绍的可视化技术可以揭示在模型上任何层上激发单个特征图的输入刺激。它还使我们能够在训练过程中观察特征的演变并诊断模型的潜在问题。
该文章采用了多层反卷积网络,将特征激活投影回输入像素空间。并且通过遮挡部分对分类器输出进行敏感性分析输入图像的位置,解释场景中哪部分对分类更重要。
使用了这些工具后,发现在ImageNet上性能优于其架构的架构。 然后,我们仅需重新训练模型顶部的softmax层,即可探索模型对其他数据集的泛化能力。 因此,这是一种有监督的预训练形式,并在并发工作中也探索了卷积特征的泛化能力。
1.1 related work
可视化功能以获得关于网络的直觉是常见的做法,但主要限于可以投影到像素空间的第一层。 在高层,情况并非如此,解释活动的方法也很有限。通过在图像空间中执行梯度下降来最大程度地激活该单元,从而找到每个单元的最佳刺激。 这需要进行仔细的初始化,并且不提供有关单元invariances的任何信息。问题在于,对于较高的层,invariances非常复杂,因此通过简单的二次逼近很难捕获。
相比之下,我们的方法提供了invariances的非参数试图,显示了训练集中的哪些模式激活了特征图。Donahue的方法可视化了那些在模型高层响应于强激活的补丁。我们的可视化的不同之处在于它们不仅是输入图像的裁剪,而且是自顶向下的投影,它们揭示了每个补丁中刺激特定特征图的结构。
2.Approach
论文中采用传统的全监督模型, 这些模型通过一系列图层将彩色2D输入图像x i映射到C个不同类上的概率矢量y i。 每一层由(i)将上一层输出(或在第一层的情况下为输入图像)与一组学习过的滤波器进行卷积;(ii)通过一个linear function传递响应(relu(x)= max(x,0)); (iii)[可选地]在本地邻域上的max pooling;以及(iv)[可选地]进行跨特征图响应normalization的局部对比操作。并且最上基层为全连接层,最后一层为softmax层。
我们使用大量的N个标记图像{x,y}训练这些模型,其中标记y i是指示真实类别的离散变量。loss function采用cross-entropy。网络的参数(卷积层的滤波器,全连接层的权重和偏置值)都通过反向传播算法计算,并通过随机梯度下降来更新参数。可以对SVM进行训练
2.1 Visualization with a Deconvnet
了解卷积网络的操作需要解释中间层中的要素活动。 我们提出了一种新颖的方法来将这些活动映射回输入像素空间,从而显示出哪种输入模式最初在功能图中导致了给定的激活。
我们使用反卷积网络(deconvnet)进行此映射(Zeiler等,2011)。 deconvnet可以被认为是使用相同组件(过滤,池化)但反过来使用的convnet模型,因此,与其将像素映射到特征相反,反之亦然。在(Zeiler et al。,2011)中,提出了反卷积网络作为一种无监督学习的方法。 在这里,它们不使用任何学习能力,就像对已经训练过的卷积网络的探究。
为了检查卷积网络,将deconvnet附加到其每一层,如图1(顶部)所示,提供返回图像像素的连续路径。首先,将输入图像呈现给卷积网络,并在整个图层中计算特征。 为了检查给定的convnet激活,我们将该层中的所有其他激活设置为零,并将特征映射作为输入传递到附加的deconvnet层。(返璞归真)
然后依次进行:1)分解;2)校正;3)滤波以在下面的层中重建活动,从而产生指定的激活。然后重复以上操作,直到达到输入像素空间
**Unpooling:**在卷积网络中,max pooling操作是不可逆的,但是我们可以通过在一组开关变量中记录每个pooling区域内最大值的位置来获得近似逆。 在去卷积网络中,unpooling操作使用这些开关将来自上一层的重建内容放置到适当的位置,从而保留刺激的结构。
**Rectification:**卷积网络使用relu非线性,可校正特征图,从而确保特征图始终为正。 为了在每一层上获得有效的特征重建(也应该是正数),我们将重建的信号通过relu非线性传递。
**Filtering:**卷积网络使用学习的filter对来自上一层的feature map进行卷积。 为了解决这个问题,deconvnet使用相同filter的转置版本,但应用于校正后的map,而不是其下一层的输出。 实际上,这意味着垂直和水平翻转每个过滤器。(连贯动作)
从较高的层向下投影使用向上转换时convnet中最大池生成的开关设置。 由于这些开关设置是给定输入图像所特有的,因此从一次激活获得的重建效果类似于原始输入图像的一小部分,其结构根据其对特征激活的贡献而加权。 由于对模型进行了判别式训练,因此它们隐式显示了输入图像的哪些部分是判别式的。 请注意,这些预测并非来自模型的样本,因为不涉及生成过程。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NNXRUIMK-1611736462792)(C:\Users\18929\AppData\Roaming\Typora\typora-user-images\image-20210121161643659.png)]](https://img-blog.csdnimg.cn/20210127163508779.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RJQUpFWQ==,size_16,color_FFFFFF,t_70)
3.Training Details
现在我们描述将在第4节中可视化的大型convnet模型。图3所示的体系结构类似于(Krizhevsky et al。,2012)用于ImageNet分类的体系结构。 区别之一在于,Krizhevsky第3、4、5层中使用的稀疏连接(由于模型被划分为2个GPU),因此在我们的模型中被密集连接取代。
如第4.1节所述,在检查了图6中的可视化之后,做出了与第1层和第2层有关的其他重要区别。
该模型在ImageNet 2012训练集中进行了训练(130万张图像,分布在1000个不同的类中)。 通过将最小尺寸调整为256,裁剪中心256x256区域,减去每像素均值(所有像素的),然后使用10个大小为224x224的不同子裁剪(角+中心(水平翻转))。使用随机梯度下降方法和mini-batch(size is 128)来更新参数。初始学习率为0.01,加上0.9的动力参数。
当验证误差趋于平坦时,我们对学习率进行退火。在全连接层使用大小为0.5的dropout。所有的权重初始化为0.01,偏置值设置为0
如图6(a)所示,第一层滤波器的可视化显示,在训练过程中发现其中有一些滤波器占据了主导地位。为了解决这一问题,对卷积层中的那些超过固定半径10%的滤波器进行再优化。这一点至关重要,尤其是在模型的第一层,输入图像大约在[-128,128]的范围内
与(Krizhevsky et al 2012)中一样,我们生成了多个crop(裁剪后)和翻转以扩充训练集规模。基于krizhevsky的框架。在70个epochs后停止了训练,这在单个GTX580 GPU上花费了大约12天。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ImV3olZM-1611736462795)(C:\Users\18929\AppData\Roaming\Typora\typora-user-images\image-20210123094427811.png)]](https://img-blog.csdnimg.cn/2021012716352295.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RJQUpFWQ==,size_16,color_FFFFFF,t_70)
4.Convnet Visualization
使用Section3描述的模型,现在我们使用反卷积去可视化ImageNet验证集上的特征激活因子。
**Feature Visualization:**图二表示我们网络成功运行一次后的特征可视图。并且和显示最强的激活因子不同,我们显示了前9强的激活因子。将每个像素分别投影到像素空间会揭示激发给定特征图的不同结构,从而显示其对输入变形的不变性。除了这些可视化之外,我们还显示了相应的图像patches。 它们比可视化具有更大的变化,因为可视化仅关注每个patches内的判别结构。例如,在第5层第1行第2列中,patches看上去几乎没有什么共同点,但是可视化显示该特定的特征图着重于背景中的草,而不是前景对象。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-axgaSUMv-1611736540873)(C:\Users\18929\AppData\Roaming\Typora\typora-user-images\image-20210121211255912.png)]](https://img-blog.csdnimg.cn/20210127163623341.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RJQUpFWQ==,size_16,color_FFFFFF,t_70)
图2.经过完全训练的模型中的功能可视化。 对于第2-5层,我们在整个验证数据中的特征图的随机子集中显示了前9个激活,并使用我们的反卷积网络方法将其投影到像素空间。 我们的重构不是来自模型的样本:它们是来自验证集的重构模式,这些模式在给定的特征图中导致高度激活。 对于每个特征图,我们还显示相应的图像补丁。 注意:(i)每个特征图内的强分组,(ii)较高层的不变性较大,以及(iii)图像可区分部分的夸大,例如 狗的眼睛和鼻子(第4层,第1行,第1列)。 最好以电子形式查看。
每层的投影显示了网络中功能的分层性质。 第2层响应角点和其他边缘/颜色相交。 第3层具有更复杂的不变性,可以捕获相似的纹理(例如网格图案(第1行,第1行);文本(R2,C4))。第4层显示出明显的变化,但更特定于类别:狗脸(R1,C1); 鸟的腿(R4,C2)。第5层显示整个对象的姿态变化很大,例如 键盘(R1,C11)和狗(R4)。
**·Feature Evolution during Training:**图4可视化了在投影回像素空间的给定特征图中最强激活因子(在所有训练示例中)的训练过程。 外观突然跳变是由于最强烈的激活所源自的图像变化所致。 可以看到模型的较低层在几个epochs内收敛。 但是,只有在相当多个epochs(40-50)之后才会发展上层,这表明需要让模型训练直到完全收敛。(底层的收敛得快,高层的收敛得较慢)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yiCg2ogT-1611736462799)(C:\Users\18929\AppData\Roaming\Typora\typora-user-images\image-20210123095102660.png)]](https://img-blog.csdnimg.cn/20210127163702476.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RJQUpFWQ==,size_16,color_FFFFFF,t_70)
**·Featur Invariance:**图5展示了5个样本图像,它们以不同的程度进行平移,旋转和缩放,同时查看来自模型顶层和底层的特征向量相对于未转换特征的变化。 较小的变换在模型的第一层产生了巨大的影响,但在顶层要素层的影响较小,对于平移和缩放是准线性的。 网络输出对于转换和缩放是稳定的。 通常,除了具有旋转对称性的对象(例如娱乐中心)外,输出对于旋转不是不变的。(对于图像变化的特征响应)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DcwpWwjW-1611736462801)(C:\Users\18929\AppData\Roaming\Typora\typora-user-images\image-20210123095652065.png)]](https://img-blog.csdnimg.cn/20210127163716733.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RJQUpFWQ==,size_16,color_FFFFFF,t_70)
分析模型中的垂直平移,缩放和旋转不变性(分别为行a-c)。 第1列:5个进行转换的示例图像。 第2列和第3列:分别来自第1层和第7层中原始图像和变换图像的特征向量之间的欧式距离。 第4列:图像经过变换后,每个图像被标记为真的概率
4.1 Architecture Selection
通过可视化卷积层的操作后,不仅可以深入了解其操作,还有助于选择好的网络结构。通过可视化Krizhevsky的网络结构,可以看到许多问题。比如第一层滤波器混合了极高和极低的频率信息,但很少覆盖中频。此外,第二层可视化还显示了由第一层卷积中使用的大步幅4引起的混叠伪影。(如图6 (b)&(d)所示)
为了解决这些问题。我们(1)将第一层的滤波器从11x11缩小到了7x7;(2)步长从4设置为2。(伪影就是卷积面积太大了)
如图六的©&(e)所示。新结构下第一层和第二层,保存了更多的特征信息。更重要的是,如Section5.1所示,这样还可以提高分类的表现。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xZXF9G9l-1611736462802)(C:\Users\18929\AppData\Roaming\Typora\typora-user-images\image-20210123100450329.png)]](https://img-blog.csdnimg.cn/20210127163733578.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RJQUpFWQ==,size_16,color_FFFFFF,t_70)
图6.(a):没有要素比例裁剪的第一层要素。 请注意,一个功能占主导。 (b):(Krizhevsky et al。,2012)的第一层特征。 (c):我们的第一层功能。 较小的步幅(2对4)和滤镜大小(7x7对11x11)可提供更多可区分的特征以及更少的“死”特征。 (d):(Krizhevsky et al。,2012)中第二层特征的可视化。 (e):第二层特征的可视化。 这些更加干净,没有在(d)中可见的锯齿失真。
4.2 Occlusion Sensitivity
对于图像分类方法。有一个问题是模型到底是真正识别出图像中对象的位置,还是仅使用周围环境区分?(通过遮挡来测试是否真正识别到了对象,也可以通过遮挡来确定特征具体位置)
图7试图通过用灰色正方形系统地遮盖输入图像的不同部分并监视分类器的输出来回答这个问题。这些示例清楚地表明,该模型正在场景中定位对象,因为当对象被遮挡时,正确类别的概率会大大降低。
图7还显示了顶层卷积层的最强特征图的可视化效果,此外,该图(根据空间位置求和)中的活动也取决于遮挡物位置。当遮挡物覆盖可视化中出现的图像区域时,我们会看到特征图中的活动大大减少。
这表明可视化确实与刺激该特征图的图像结构相对应,从而验证了图4和图2所示的其他可视化。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-f7UOzTqw-1611736462804)(C:\Users\18929\AppData\Roaming\Typora\typora-user-images\image-20210123101441607.png)]](https://img-blog.csdnimg.cn/20210127163749851.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RJQUpFWQ==,size_16,color_FFFFFF,t_70)
(b)对于灰度的每个位置,我们将总激活记录在一个第5层特征图中(在无遮挡的图像中响应最强的那个)(c):该特征图的可视化投影到输入图像中(黑色正方形) ),以及该地图从其他图像中获得的可视化效果。第一行示例显示了最强的特征是狗的脸。遮盖住后,特征图中的活动会减少((b)中的蓝色区域)。 (d):根据灰色正方形的位置,正确分类概率的图。例如。当狗的脸被遮盖时,“博美犬”的可能性将大大降低。 (e):最可能的标签是封堵器位置的函数。例如。在第一行中,对于大多数位置,它是“ pomeranian”,但是如果狗的脸被遮盖而不是被遮盖,则表示“网球”。在第二个示例中,汽车上的文字是第5层中最强大的功能,但分类器对车轮最敏感。第三个示例包含多个对象。第5层中最强的特征会拾取人脸,但分类器对狗((d)中的蓝色区域)敏感,因为它使用了多个特征图。
4.3 Correspondence Analysis
深度模型与许多现有的识别方法不同,因为没有明确的机制来建立不同图像中特定对象部分之间的对应关系(例如,脸部具有眼睛和鼻子的特定空间配置)。但是,一个有趣的可能性是深层模型可能会隐式地对其进行计算。为了探索这一点,我们以正面姿势拍摄了5张随机绘制的狗图像,并在每张图像中系统地遮盖了脸部的同一部分(例如,所有左眼,见图8)。然后,对于每个图像i,我们计算: li = x l i-〜x l i,其中x l i和〜x l i分别是原始图像和遮挡图像在l层的特征向量。然后,我们测量该差异向量的一致性。 在所有相关图像对(i,j)之间:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EREh9Eob-1611736462805)(C:\Users\18929\AppData\Roaming\Typora\typora-user-images\image-20210123093435331.png)],其中H是汉明距离。较低的值表示由遮罩操作导致的更改的一致性更高,因此,不同图像中相同对象部分之间的紧密对应关系(即,遮挡左眼会以一致的方式更改特征表示)。在表1中,我们使用l = 5层和l = 7层的特征,比较了脸的三个部分(左眼,右眼和鼻子)与对象的随机部分的∆得分。 对于随机对象区域,对于第5层要素显示模型确实建立了一定程度的对应性。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o2w26uAb-1611736462806)(C:\Users\18929\AppData\Roaming\Typora\typora-user-images\image-20210123102214399.png)]](https://img-blog.csdnimg.cn/20210127163806223.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RJQUpFWQ==,size_16,color_FFFFFF,t_70)
5个不同狗图像中不同对象部分的对应性度量。 眼睛和鼻子的较低分数(与随机物体的部分相比)表明该模型隐式地在模型的第5层建立了某种形式的部分对应关系。 在第7层,得分更为相似,可能是由于上层试图区分不同品种的狗。
5.Experiments
5.1 ImageNet 2012
This dataset consists of 1.3M/50k/100k training/validation/test examples, spread over 1000 categories. Table 2 shows our results on this dataset.
使用(Krizhevsky et al。,2012)中指定的确切架构,我们尝试将其结果复制到验证集上。 我们在ImageNet 2012验证集中实现的错误率在其报告值的0.1%之内。
接下来,我们将根据第4.1节中概述的架构更改(第1层中的7×7过滤器以及第1和第2层中的第2步卷积)分析模型的性能。 如图3所示,该模型的性能明显优于(Krizhevsky et al。,2012)的体系结构,将其单个模型的结果击败了1.7%(测试前5名)。当我们组合多个模型时,得到的测试误差为 14.8%,在此数据集1上的最佳发布绩效(尽管仅使用2012年的培训集)。 我们注意到,此错误几乎是ImageNet 2012分类挑战中排名最靠前的非convnet条目的一半,后者获得26.2%的错误(Gunji等,2012)。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4R1P8pfZ-1611736462807)(C:\Users\18929\AppData\Roaming\Typora\typora-user-images\image-20210123114631550.png)]](https://img-blog.csdnimg.cn/20210127163825111.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RJQUpFWQ==,size_16,color_FFFFFF,t_70)
**Varying ImageNet Model Sizes:**在表3中,我们首先通过调整图层大小或完全删除图层来探索(Krizhevsky et al。,2012)的体系结构。 在每种情况下,都使用修订后的架构从头开始训练模型。 卸下完全连接的层(6,7)只会使误差略有增加。考虑到它们包含大多数模型参数,这令人惊讶。 去除两个中间卷积层也使误差率的变化相对较小。但是,除去中间的卷积层和完全连接的层后,将得到仅具有4个层的模型,其性能明显较差。这表明模型的整体深度对于获得良好的性能很重要。
在表3中,我们修改了模型,如图3所示。更改完全连接的层的大小对性能几乎没有影响(与(Krizhevsky et al。,2012)的模型相同)。但是增加中间卷积层的单元数可以在性能上获得有用的收益。 但是如果同时又扩大完全连接的层数会导致过度拟合(只增加中间会有收益,同时增加会over-fitting)。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-osCAjfkZ-1611736462808)(C:\Users\18929\AppData\Roaming\Typora\typora-user-images\image-20210123120540464.png)]](https://img-blog.csdnimg.cn/20210127163837746.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RJQUpFWQ==,size_16,color_FFFFFF,t_70)
5.2 Feature Generalization
上面的实验显示了ImageNet模型的卷积部分对于获得最新性能的重要性。 这由图2的可视化支持,该可视化显示了在卷积层中学习到的复杂不变性。
我们现在探索这些特征提取层将其推广到其他数据集的能力,即Caltech-101(Fei fei等人,2006),Caltech-256(Griffin等人,2006)和PASCAL VOC 2012。
为此,我们固定了ImageNet训练模型的第1-7层,并使用新数据集的训练图像在顶部训练了new softmax分类器(对于适当数量的类)(迁移学习)。由于softmax包含的参数相对较少,因此可以从相对较少的示例中快速对其进行训练,就像某些数据集一样。
我们的模型(一个softmax)和其他方法(通常是线性SVM)使用的分类器具有相似的复杂度,因此实验将从ImageNet中学习到的我们的特征表示与其他方法使用的hand-crafted特征进行了比较。重要的是要注意,我们的特征表示和手工制作的特征都是使用Caltech和PASCAL训练集以外的图像设计的。例如,HOG描述符中的超参数是通过对行人数据集进行系统实验确定的(Dalal&Triggs,2005)。 我们还尝试了第二种从头开始训练模型的策略,即将第1-7层重置为随机值,然后在数据集的训练图像上训练它们以及softmax。(比较迁移效果?)
一种复杂的情况是,一些Caltech数据集的图像也包含在ImageNet训练数据中。 使用归一化的相关性,我们识别出了这几张“重叠”图像2并将其从Imagenet训练集中删除,然后重新训练了Imagenet模型,从而避免了训练/测试污染的可能性。
**Caltech-101:**我们遵循(Fei-fei et al。,2006)的程序,随机选择每类15或30张图像进行训练,并在每类最多50张图像上进行测试,Table4中显示了每类准确性的平均值,使用 top5 训练/测试折叠。 培训耗时17分钟,每类使用30张图像。 预先训练的模型在(Bo等人,2013年)获得的30张图像/类的最佳报告结果中胜出2.2%。 从头开始训练的卷积模型却做得非常糟糕,仅达到46.5%。(预训练模型效果不错,从头开始训练一般)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5hnWn0RQ-1611736462809)(C:\Users\18929\AppData\Roaming\Typora\typora-user-images\image-20210123122133192.png)]](https://img-blog.csdnimg.cn/20210127163852862.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RJQUpFWQ==,size_16,color_FFFFFF,t_70)
**Caltech-256:**我们遵循(Griffin et al。,2006)的程序,每类选择15、30、45或60个训练图像,在表5中表示每班准确性的平均值。我们的ImageNet预训练模型优于当前模型。 Bo等人获得的最新结果。 (Bo et al。,2013)大幅提高:对于60个训练图像/类,74.2%vs55.2%。 但是,与Caltech-101一样,从头训练的模型的效果也很差。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jky8E6yW-1611736462811)(C:\Users\18929\AppData\Roaming\Typora\typora-user-images\image-20210123145114926.png)]](https://img-blog.csdnimg.cn/20210127163905423.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RJQUpFWQ==,size_16,color_FFFFFF,t_70)
在图9中,我们探索了“一次性学习”(Fei-fei等,2006)的机制。 使用我们的预训练模型,只需使用6张Caltech-256训练图像即可击败领先方法,而领先方法使用的图像数量是其10倍。 这显示了ImageNet功能提取器的功能。

**PASCAL 2012:**我们使用标准的训练和验证图像在ImageNet预训练的卷积网络上训练20个输出的softmax。 这不是理想的,因为PASCAL图像可以包含多个对象,而我们的模型仅为每个图像提供了一个唯一的预测。表6显示了测试集上的结果。 PASCAL和ImageNet图像本质上有很大不同,前者是完整场景,与后者不同。 这可能解释了我们的平均成绩比领先成绩(Yan等人,2012)低3.2%,但我们确实在5个班级上都取得了优异的成绩,有时差距很大。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Z8nHZ6H6-1611736462812)(C:\Users\18929\AppData\Roaming\Typora\typora-user-images\image-20210123145709940.png)]](https://img-blog.csdnimg.cn/20210127163953894.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RJQUpFWQ==,size_16,color_FFFFFF,t_70)
5.3 Feature Analysis
我们探索了Imagenet预训练模型的每一层中的特征如何区分。 我们通过更改从ImageNet模型保留的层数并在顶部放置线性SVM或softmax分类器来实现此目的。
表7显示了Caltech-101和Caltech-256上的结果。 对于这两个数据集,当我们提升模型时都可以看到稳定的改进,通过使用所有图层可以获得最佳结果。这支持了这样的前提,即随着要素层次结构的深入,他们将学习越来越强有力的特征。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MlPHamzs-1611736462813)(C:\Users\18929\AppData\Roaming\Typora\typora-user-images\image-20210123150554057.png)]](https://img-blog.csdnimg.cn/20210127164033725.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RJQUpFWQ==,size_16,color_FFFFFF,t_70)
6.Discussion
我们以多种方式探索了受过图像分类训练的大型卷积神经网络模型。首先,我们提出了一种新颖的方法来可视化模型中的活动。 这表明功能远非随机的,无法解释的模式。相反,它们显示了许多直观上理想的属性,例如组成性,和随着我们提升图层而进行的类区分不断增加的不变性。 我们还展示了如何使用这些可视化工具来调试模型中的问题以获得更好的结果,例如对Krizhevsky等进行改进。 (Krizhevsky et al。,2012)令人印象深刻的ImageNet 2012成果。
然后,我们通过一系列遮挡实验证明,该模型在进行分类训练时对图像中的局部结构高度敏感,而不仅仅是使用宽广的场景上下文。 对模型的消融研究表明,对网络(而不是任何单个部分)的最小深度对于模型的性能至关重要。
最后,我们展示了ImageNet训练的模型如何很好地推广到其他数据集。 对于Caltech-101和Caltech-256,数据集足够相似,以至于我们可以击败报告的最佳结果,在后一种情况下,看到了一定的局限性。 该结果使具有小的(即<10 4)训练集的基准的实用性受到质疑。我们的卷积模型对PASCAL数据的泛化效果较差,可能遭受了数据集偏差(Torralba&Efros,2011年),尽管它仍未达到最佳报告结果的3.2%,尽管该任务并未进行调整。 例如,如果使用不同的损失函数(每个图像允许多个对象),我们的性能可能会提高。 这自然将使网络也能够处理对象检测。
·总结:
1、反池化过程
我们知道,池化是不可逆的过程,然而我们可以通过记录池化过程中,最大激活值得坐标位置。然后在反池化的时候,只把池化过程中最大激活值所在的位置坐标的值激活,其它的值置为0,当然这个过程只是一种近似,因为我们在池化的过程中,除了最大值所在的位置,其它的值也是不为0的。刚好最近几天看到文献:《Stacked What-Where Auto-encoders》,里面有个反卷积示意图画的比较好,所有就截下图,用这篇文献的示意图进行讲解:
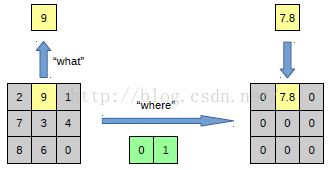
以上面的图片为例,上面的图片中左边表示pooling过程,右边表示unpooling过程。假设我们pooling块的大小是33,采用max pooling后,我们可以得到一个输出神经元其激活值为9,pooling是一个下采样的过程,本来是33大小,经过pooling后,就变成了11大小的图片了。而upooling刚好与pooling过程相反,它是一个上采样的过程,是pooling的一个反向运算,当我们由一个神经元要扩展到33个神经元的时候,我们需要借助于pooling过程中,记录下最大值所在的位置坐标(0,1),然后在unpooling过程的时候,就把(0,1)这个像素点的位置填上去,其它的神经元激活值全部为0。再来一个例子:
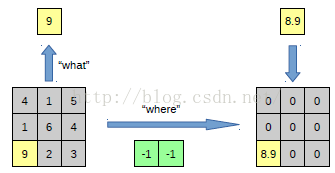
在max pooling的时候,我们不仅要得到最大值,同时还要记录下最大值得坐标(-1,-1),然后再unpooling的时候,就直接把(-1-1)这个点的值填上去,其它的激活值全部为0。
2、反激活
我们在Alexnet中,relu函数是用于保证每层输出的激活值都是正数,因此对于反向过程,我们同样需要保证每层的特征图为正值,也就是说这个反激活过程和激活过程没有什么差别,都是直接采用relu函数。
3、反卷积
对于反卷积过程,采用卷积过程转置后的滤波器(参数一样,只不过把参数矩阵水平和垂直方向翻转了一下),这一点我现在也不是很明白,估计要采用数学的相关理论进行证明。
最后可视化网络结构如下:
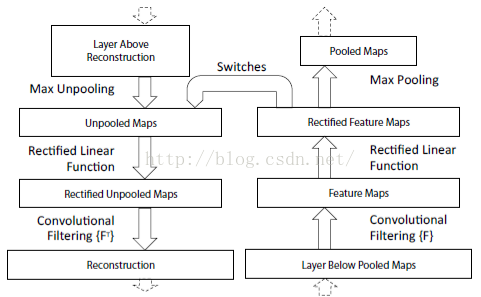
网络的整个过程,从右边开始:输入图片-》卷积-》Relu-》最大池化-》得到结果特征图-》反池化-》Relu-》反卷积。
4、特征可视化结果:

总的来说,通过CNN学习后,我们学习到的特征,是具有辨别性的特征,比如要我们区分人脸和狗头,那么通过CNN学习后,背景部位的激活度基本很少,我们通过可视化就可以看到我们提取到的特征忽视了背景,而是把关键的信息给提取出来了。从layer 1、layer 2学习到的特征基本上是颜色、边缘等低层特征;layer 3则开始稍微变得复杂,学习到的是纹理特征,比如上面的一些网格纹理;layer 4学习到的则是比较有区别性的特征,比如狗头;layer 5学习到的则是完整的,具有辨别性关键特征。
5、特征学习的过程。

作者给我们显示了,在网络训练过程中,每一层学习到的特征是怎么变化的,上面每一整张图片是网络的某一层特征图,然后每一行有8个小图片,分别表示网络epochs次数为:1、2、5、10、20、30、40、64的特征图:
结果:(1)仔细看每一层,在迭代的过程中的变化,出现了sudden jumps;(2)从层与层之间做比较,我们可以看到,低层在训练的过程中基本没啥变化,比较容易收敛,高层的特征学习则变化很大。这解释了低层网络的从训练开始,基本上没有太大的变化,因为梯度弥散嘛。(3)从高层网络conv5的变化过程,我们可以看到,刚开始几次的迭代,基本变化不是很大,但是到了40~50的迭代的时候,变化很大,因此我们以后在训练网络的时候,不要着急看结果,看结果需要保证网络收敛。
6、图像变换。
从文献中的图片5可视化结果,我们可以看到对于一张经过缩放、平移等操作的图片来说:对网络的第一层影响比较大,到了后面几层,基本上这些变换提取到的特征没什么比较大的变化。
·待解决问题:
退火函数:在解空间内随机搜索,遇到较优解就接受,遇到较差解就按一定的概率决定是否接受,这个概率随时间的变化而降低。(避免进入局部最优解的+)
https://www.cnblogs.com/rvalue/p/8678318.html















 1094
1094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









